


Research generally agrees that orthographic knowledge (especially alphabetic knowledge) plays a pivotal role in speech processing for literate speakers. So strong is the influence of alphabetic knowledge that Frith (Reference Frith1998) likens the possession of alphabetic knowledge to a virus that “infects all speech processing” and “language is never the same again” (p. 1011). Olson (Reference Olson1996) claims that “people familiar with an alphabet come to hear [original emphasis] words as composed of the sounds represented by the letters of the alphabet” (p. 93). Alphabetic knowledge affects speech processing by influencing individuals’ abilities to isolate phonemes, perceive phonemes, and separate phonemes and letters. First, learning to read creates a virtually unbreakable bond between letters and sounds such that individuals cannot completely separate sounds from letters (Treiman & Cassar, Reference Treiman and Cassar1997) and cannot avoid thinking of sounds in terms of their orthographic representations (Burnham, Reference Burnham2003; Landerl, Frith, & Wimmer, Reference Landerl, Frith and Wimmer1996). Second, the ability to count phonemes only surfaces once children learn to read via an alphabet (e.g., Bertelson, de Gelder, Tfouni, & Morais, Reference Bertelson, de Gelder, Tfouni and Morais1989; Carroll, Reference Carroll2004; Morais, Cary, Alegria, & Bertleson, Reference Morais, Cary, Alegria and Bertelson1979; Read, Zhang, Nie, & Ding, Reference Read, Zhang, Nie and Ding1986), and only individuals with alphabetic experience are able to breakdown words into their component sounds because alphabets “sensitize” individuals to the phonemic level (e.g., Bassetti, Reference Bassetti2006; Cheung & Chen, Reference Cheung and Chen2004; Cook & Bassetti, Reference Cook, Bassetti, Cook and Bassetti2005; Derwing, Reference Derwing, Downing, Lima and Noonan1992; Gombert, Reference Gombert1996). Third, visual forms of words acquired through reading shape a learner's conceptualizations of the phoneme segments (Ehri, Reference Ehri, Olsen, Torrence and Hildyard1985), and once they make letter–phoneme associations, readers may find it hard to ignore letters and focus on phonemes alone (Gombert, Reference Gombert1996). Fourth, when a mismatch occurs between the orthography and the phonology, the orthographic representation often overrides the phonological representation thereby causing individuals to misperceive/mispronounce words (Bassetti, & Atkinson, Reference Bassetti and Atkinson2015; Erdener & Burnham, Reference Erdener and Burnham2005; Hallé, Chéreau, & Segui, Reference Hallé, Chéreau and Segui2000; Hayes-Harb, Nicol, & Barber, Reference Hayes-Harb, Nicol and Barker2010).
This study aims to determine if orthographic representation influences how individuals perceive phonemes in second language (L2) words, specifically with respect to native speakers of Canadian English perceiving phonemes in their L2, either Russian or Mandarin Chinese. In addition, this research investigated how first language (L1) and L2 orthographies interact (if at all) in influencing L2 learners’ perception of L2 phonemes. The primary research question asks: does the orthographic representation override the phonological representation and determine the number of phonemes individuals perceive in L2 words? That is, do literate learners rely on their knowledge of how words are spelled (both in L1 and L2) in order to perform a phoneme awareness task?
ACQUISITION AND DEVELOPMENT OF PHONEME AWARENESS
Research suggests that writing systems dictate the subword language units literate speakers are aware of and thus can identify and manipulate (e.g., Bassetti, Reference Bassetti2006; Derwing, Reference Derwing, Downing, Lima and Noonan1992). Syllabaries (e.g., Japanese kana and hiragana) create awareness of more consonantal writing systems (e.g., Arabic and Hebrew) and create awareness of consonant–vowel (CV) units, and alphabets (e.g., Roman and Cyrillic) create awareness of phonemes (Cook & Bassetti, Reference Cook, Bassetti, Cook and Bassetti2005; Gombert, Reference Gombert1996; Goswami, Reference Goswami, Harris and Hatano1999; Mann, Reference Mann1986; Saiegh-Haddad, Kogan, & Walters, Reference Saiegh-Haddad, Kogan and Walters2010; Wade-Woolley, Reference Wade-Woolley1999). Different types of writing systems make different phonological units salient, suggesting that phonemes may not be the “natural, universal unit of speech segmentation” and that “orthographic norms. . . may play a larger role in fixing what the appropriate scope is for those discrete repeated units” (Derwing, Reference Derwing, Downing, Lima and Noonan1992, p. 200). While children/adults acquire phonological awareness (i.e., the ability to manipulate syllables and onsets/rimes) naturally without reading instruction, they can only acquire phoneme awareness (i.e., the ability to manipulate individual phonemes) with instruction in a written code, specifically an alphabetic code (Carroll, Reference Carroll2004; Chueng & Chen, Reference Cheung and Chen2004; Morais, Reference Morais, Brady and Shankweiler1991). Alphabetic experience allows listeners to abstract the phonemes from the speech signal. A substantial body of research on children, dyslexics, illiterates, and nonalphabetic literates suggests that phoneme awareness is a product of alphabetic knowledge. For individuals to perform successfully on phoneme awareness tasks (e.g., phoneme counting: count or tap the number of phonemes in a word; phoneme deletion: isolate a target phoneme and delete it from the syllable; phoneme blending: combine given phonemes in to a word), they must have experience with an alphabetic script. Chueng and Chen (Reference Cheung and Chen2004) argue that “phoneme awareness requires support from alphabetic reading . . . because the identity of the phoneme is made explicit only in alphabets” (p. 3). Children learn how to isolate and/or segment phonemes via learning letters, and their threshold for phoneme awareness is knowledge of a few letters and the phonemes those letters represent (Carroll, Reference Carroll2004). Alphabetic knowledge allows listeners to parse words into their component phonemes because alphabets sensitize listeners to the phonemic level.
For children, knowledge of syllables and onsets and rimes appears to develop spontaneously before children go to school, but knowledge of phonemes does not appear to develop until children go to school and begin to learn to read in an alphabetic orthography (e.g., Chueng & Chen, Reference Cheung and Chen2004; Liberman, Shankweiler, Fischer, & Carter, Reference Liberman, Shankweiler, Fischer and Carter1974; Morais et al., Reference Morais, Cary, Alegria and Bertelson1979; Treiman & Cassar, Reference Treiman and Cassar1997). For adults, alphabetic literates are significantly more successful at performing phoneme awareness tasks than both nonliterates (Bertelson et al., Reference Bertelson, de Gelder, Tfouni and Morais1989; Morais, Bertelson, Cary, & Alegria, Reference Morais, Bertelson, Cary and Alegria1986; Morais et al., Reference Morais, Cary, Alegria and Bertelson1979) and nonalphabetic literates (Cheung, Reference Cheung1999; Cheung & Chen, Reference Cheung and Chen2004; Read et al., Reference Read, Zhang, Nie and Ding1986), suggesting that differences in segmentation skills are a result of alphabetic literacy.
Research has also shown that phoneme awareness is contingent on alphabetic experience for L2 learners. Alphabetic L1 orthographies facilitate L2 phoneme awareness such that L2 learners who have an alphabetic L1 orthography perform better on phoneme manipulation tasks than L2 learners who have a nonalphabetic L1 orthography. Ben-Dror, Frost, and Bentin (Reference Ben-Dror, Frost and Bentin1995) discovered that the English speakers could accurately delete target phonemes in both English (L1) and Hebrew (L2), while the Hebrew speakers tended to delete initial CV segments rather than the single target phonemes in Hebrew (L1) and English (L2). They suggest that because the orthographic units in English generally correspond to single phonemes, the L1 orthography enhances phoneme awareness, and that because the orthographic units in Hebrew (a consonantal system) generally correspond to CV segments, the L1 orthography inhibits Hebrew speakers’ abilities to accurately manipulate individual phonemes. Similarly, Wade-Woolley (Reference Wade-Woolley1999) also argues that L1 orthographic experience is a contributing factor for performance in phoneme awareness tasks. She discovered that Russian learners of English performed significantly better in a phoneme deletion task than Japanese learners of English. The Russian learners’ experience with an alphabetic orthography (i.e., Cyrillic) positively facilitated their ability to manipulate sublexical speech units, while the Japanese learners’ experience with a syllabic orthography (i.e., Kana) sensitized them to visual information but did not help them perform the phoneme deletion task.
ORTHOGRAPHIC DEPTH
Orthographic depth plays an important role in how orthographic representation influences speech processing. For alphabetic orthographies, orthographic depth refers to the consistency of letter–phoneme correspondences in a language (Ellis et al., Reference Ellis, Natsume, Stavropoulou, Hoxhallari, Van Daal and Polyzoe2004; Frost & Katz, Reference Frost and Katz1989; Katz & Frost, Reference Katz, Frost, Katz and Frost1992; Liberman, Liberman, Mattingly, & Shankweiler, Reference Liberman, Liberman, Mattingly, Shankweiler, Kavanagh and Venezky1980). Orthographic depth depends on two variables: (a) the depth of the morphophonological representation, that is, whether the system represents the language at the phonemic, syllabic, or morphemic level and (b) the degree to which the orthography approximates the phonemic representation, that is, the degree of letter regularity (Liberman et al., Reference Liberman, Liberman, Mattingly, Shankweiler, Kavanagh and Venezky1980). Essentially, the regularity and consistency of letter–phoneme correspondences determines the degree of orthographic transparency. Because of the varying degrees of transparency, languages can be viewed along a continuum of orthographic depth (e.g., Danielsson, Reference Danielsson2003; Ellis et al., Reference Ellis, Natsume, Stavropoulou, Hoxhallari, Van Daal and Polyzoe2004; Liberman et al., Reference Liberman, Liberman, Mattingly, Shankweiler, Kavanagh and Venezky1980; Seymour, Aro, & Erskine, Reference Seymour, Aro and Erskine2003) from very shallow (e.g., Finnish), with a high degree of regularity between the letters and phonemes where one letter represents one phoneme, to very deep (e.g., Scots Gaelic), with a high degree of irregularity in their letter–phoneme correspondences where letters often represent more than one phoneme (feedforward inconsistency) and/or there is often more than one way to spell a phoneme (feedback inconsistency). English exists at the deeper end of the orthographic depth continuum because of its irregularity and the high degree of both feedforward (letter-to-phoneme) and feedback (phoneme-to-letter) inconsistencies. For example, the letter sequence <ough> can be pronounced as /ʌf/, /ɑf/, /u/, /ow/, /ʌp/, /ɑ/, /ʌw/, and /aw/) as in the words tough, cough, through, though, hiccough, brought, drought, and plough (feedforward), and the phoneme /i/ can be written as <e, ee, ea, ie, ei, y, and i> as in the words evil, sweet, wheat, yield, receipt, city, and graffiti (feedback). Research has shown these two types of inconsistency can both decrease accuracy and slow processing times in word recognition (Stone, Vanhoy, & Van Orden, Reference Stone, Vanhoy and Van Orden1997).
Reading abilities are directly linked to whether the children learn to read in a shallow or deep orthography. According to the orthographic depth hypothesis (Katz & Frost, Reference Katz, Frost, Katz and Frost1992), orthographic depth leads to processing differences in word recognition and lexical decisions. In L1 research, shallow orthographies support word recognition processes based on a language's phonology, and deep orthographies support word recognition based on accessing lexical information through visual analysis of the orthographic structure (Danielsson, Reference Danielsson2003; Ellis et al., Reference Ellis, Natsume, Stavropoulou, Hoxhallari, Van Daal and Polyzoe2004). Shallow orthographies are easier for children to learn than deep orthographies (e.g., Goswami, Gombert, & De Barrera, 1999; Goswami, Porpodas, & Wheelwright, Reference Goswami, Porpodas and Wheelwright1997; Seymour et al., Reference Seymour, Aro and Erskine2003). The time needed to establish foundation literacy (i.e., decoding and word recognition skills) varies according to the depth of the orthography (Öney & Durgunoğlu, Reference Öney and Durgunoğlu1997; Seymour et al., Reference Seymour, Aro and Erskine2003). Children learning deep orthographies exhibit a delayed acquisition of foundation literacy compared to children learning shallow orthographies. In addition, learners of shallow orthographies also develop their phonological awareness skills more rapidly than learners of deep orthographies (Cossu, Shankweiler, Liberman, Tola, & Katz, Reference Cossu, Shankweiler, Liberman, Tola and Katz1988; Öney & Goldman, Reference Öney and Goldman1984; Spencer & Hanley, Reference Spencer and Hanley2003).
AUTOMATIC COACTIVATION OF ORTHOGRAPHIC AND PHONOLOGICAL CODES
L1 research on coactivation of orthographic and phonological codes challenges the traditional assumption that speech processing is independent of orthographic representation and that speech processing is primary, while orthographic representation is secondary (Derwing, Reference Derwing, Downing, Lima and Noonan1992; Ziegler & Ferrand, Reference Ziegler and Ferrand1998). Orthography and phonology in adult literates are very closely connected, so closely connected that orthography “intrudes” on phoneme awareness and the two are automatically coactivated (Landerl et al., Reference Landerl, Frith and Wimmer1996), and orthographic representation is automatically activated during auditory processing tasks and affects spoken word recognition (e.g., Peereman, Dufour, & Burt, Reference Peereman, Dufour and Burt2009; Perre & Ziegler, Reference Perre and Ziegler2008; Ziegler & Ferrand, Reference Ziegler and Ferrand1998; Ziegler, Ferrand, & Montant, Reference Ziegler, Ferrand and Montant2004; Ziegler, Muneaux, & Grainger, Reference Ziegler, Muneaux and Grainger2003). Even in the absence of visual information, orthographic knowledge influences the speech processing of alphabetic literate speakers (e.g., Ziegler & Ferrand, Reference Ziegler and Ferrand1998). In addition, Chéreau, Gaskell, and Dumay (Reference Chéreau, Gaskell and Dumay2007) discovered a “substantial extra facilitation” for targets with primes containing orthographic overlap (e.g., winch–finch). Primes with orthographic overlap helped the participants make significantly faster lexical decisions on real and pseudowords than did primes without orthographic overlap and unrelated primes. Similarly, Taft, Castles, Davis, Lazendic, and Nguyen-Hoan (Reference Taft, Castles, Davis, Lazendic and Nguyen-Hoan2008) discovered that pseudohomographs that could potentially be spelled in the same way as their targets would facilitate lexical decisions on the targets (as measured in response times), whereas pseudohomographs that could not be spelled in the same way as their targets would not help with lexical decisions.
LETTER–PHONEME ASSOCIATIONS AND MISPERCEPTION OF PHONEMES
Alphabetic knowledge makes separating letter–phoneme associations extremely difficult, and orthography affects how readers conceptualize the sound structure of words (Burnham, Reference Burnham2003; Treiman & Cassar, Reference Treiman and Cassar1997). Research suggests that (a) both literate children and adults cannot completely ignore letter–phoneme associations in the L1 and separate the phonemes from the letters used to represent them (Treiman & Cassar, Reference Treiman and Cassar1997), (b) listeners often count more phonemes in words with more letters and fewer phonemes in words with fewer letters (e.g., Bassetti, Reference Bassetti2006; Ehri & Wilce, Reference Ehri and Wilce1980; Perin, Reference Perin1983), and (c) listeners have more difficulty manipulating phonemes not present in a word's orthographic representation (Castles, Holmes, Neath, & Kinoshita, Reference Castles, Holmes, Neath and Kinoshita2003). For example, Ehri and Wilce (Reference Ehri and Wilce1980) discovered that when asked to count phonemes, fourth graders report more phonemes in words like pitch and badge than in words like rich and page, and Castles et al. (Reference Castles, Holmes, Neath and Kinoshita2003) discovered that participants had extreme difficulty in deleting the phoneme /s/ in words like fix where the /s/ is not represented by the letter <s> but rather it is represented, along with /k/, by the single letter <x>.
In both L1 and L2 research, studies have also shown that spelling can “suggest” phonemes and override phonemic information. Hallé et al. (Reference Hallé, Chéreau and Segui2000) demonstrated that French speakers misperceived the phonemes they heard in French words like absurde /apsyrd/ and reported hearing /b/ instead of the actual /p/ produced because the letter <b> in these types of words suggested the phoneme /b/. This led Hallé et al. to conclude that when the phonetic and orthographic information do not match in the L1, the orthographic representation overrides the phonetic representation, thus causing the listeners to misperceive the phoneme produced. L2 research too has shown that orthographic knowledge can also lead to misperception and mispronunciation of L2 targets no matter the language proficiency (Bassetti, Reference Bassetti2006; Bassetti & Atkinson, Reference Bassetti and Atkinson2015; Erdener & Burnham, Reference Erdener and Burnham2005; Hayes-Harb et al., Reference Hayes-Harb, Nicol and Barker2010). For naïve Turkish listeners, Erdener and Burnham (Reference Erdener and Burnham2005) discovered that adding orthographic information increased error rates from 0% to 46% for production of the nonnative Spanish phonemes (e.g., /x/ was pronounced as /ʒ/ because the L1 Turkish phoneme associated <j> was substituted for the L2 Spanish phoneme they heard). Bassetti and Atkinson (Reference Bassetti and Atkinson2015) discovered even learners with over 10 years of learning experience exhibit orthographic effects on speech processing, such that almost half of differently spelled homophone pairs (e.g., son vs. sun) were pronounced with nonhomophonic realizations.
Other research on cross-language homophones has also shown a phonological facilitation effect such that both L1 and L2 phonological codes are activated simultaneously when reading in the L2, and phonological information from both codes contribute to word recognition (Carrasco-Ortiz, Midgley, & Frenck-Mestre, Reference Carrasco-Ortiz, Midgley and Frenck-Mestre2012; Haigh & Jared, Reference Haigh and Jared2007; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004). L2 cross-language homophones benefit from the coactivation of their nonpresented L1 cross-language counterparts. Lemhöfer and Dijkstra (Reference Lemhöfer and Dijkstra2004) found phonological overlap facilitates lexical decisions such that Dutch–English bilinguals identified cross-language homophones more accurately and faster than the control words, which did not share a phonological overlap. Similarly, Haigh and Jared (Reference Haigh and Jared2007) found that French–English bilinguals made more accurate and faster lexical decisions on cross-language homophones than control words. Haigh and Jared also discovered that the phonological facilitation effect was greater when participants were reading in their L2 than when they were reading in their L1. Carrasco-Ortiz et al. (Reference Carrasco-Ortiz, Midgley and Frenck-Mestre2012) compared the cortical responses to cross-language homophones and control words of English monolignuals with French–English biliguals and discovered a processing advantage for homophones with the bilinguals.
CURRENT STUDY
The primary research question asks: does L2 orthographic knowledge affect how native English speakers count phonemes in their L2? That is, do language learners count phonemes more accurately in L2 words with consistent letter–phoneme correspondences than in L2 words with inconsistent letter–phoneme correspondences? Subsequently, if L2 orthography does affect L2 phoneme perception, how does L2 orthographic information interact with L1 orthographic information? Do L1 orthographic representations of L2 cross-language homophones (L2 words with a homophonous L1 counterpart, e.g., nào /naw/ “noisy” has the English counterpart now /naw/) also influence native speakers? Does L1 orthographic knowledge override L2 orthographic knowledge and affect phoneme perception in the L2?
This research posits three hypotheses. With respect to the first question, listeners should employ their L2 orthographic knowledge to help them count phonemes in nonhomophones (L2 target words without an L1 homophonous counterpart, e.g., что /ʃtɔ/ “what”). This strategy should facilitate phoneme counting in accuracy and speed when the nonhomophones contain consistent (number of letters = number of phonemes, e.g., друг /druk/ “friend”) letter–phoneme correspondences but hinder counting when the nonhomophones have inconsistent correspondences (number of letters ≠ number of phonemes, e.g., семь /sʲɛmʲ/ “seven”). The first hypothesis is that listeners will have significantly higher accuracy and faster response times for the consistent nonhomophones than for inconsistent nonhomophones, suggesting that L2 orthography impacts phoneme counting in the L2.
How L1 and L2 orthographies interact is unclear. If L1 orthographic knowledge is coactivated with L1 phonology (Peereman et al., Reference Peereman, Dufour and Burt2009; Ziegler & Ferrand, Reference Ziegler and Ferrand1998) and the L1 affects L2 learning in a general sense (Archibald, Reference Archibald1998; Major, Reference Major2001), then, L1 orthographic knowledge (the knowledge of the rules and principles by which a script is used for a particular language; Cook & Bassetti, Reference Cook, Bassetti, Cook and Bassetti2005) should affect L2 phoneme perception, and L1 orthographic knowledge will override L2 orthographic knowledge and affect L2 phoneme perception. The second hypothesis is that listeners should count phonemes accurately and quickly for consistent homophones because listeners tap into their L1 orthographic knowledge to help them. In contrast, listeners should count phonemes inaccurately and slowly for inconsistent homophones because again they tap into their L1 orthographic knowledge, but in this case, the inconsistent correspondences prevent the same degree of success for the mismatched homophones. Finally, the third hypothesis is that consistent nonhomophones (no L1 orthographic associations) will be counted more accurately and faster than inconsistent homophones (L1 associations contain inconsistent correspondences).
L2 Orthographic systems: Russian and Mandarin
Russian uses the Cyrillic alphabet, and phoneme–letter correspondences are not always straightforward because many of the letters in the Russian alphabet do not represent only one phoneme (Kerek & Niemi, Reference Kerek and Niemi2009). The 33 letters of the Cyrillic alphabet can be divided into three groups: letters that do not symbolize independent phonemes (<ъ ь>), letters that represent two phonemes (<е ё ю я>), and letters that represent one phoneme (all others; Grigorenko, Reference Grigorenko, Malatesha Joshi and Aaron2006). See Table 1 for a list of the letters and their International Phonetic Alphabet transliterations. Russian is considered a deeper orthography, albeit not as deep as English, because Russian has a number of inconsistent phoneme–letter correspondences and some letters can represent two or more different phonemes (Grigorenko, Reference Grigorenko, Malatesha Joshi and Aaron2006; Kerek & Niemi, Reference Kerek and Niemi2009).
Table 1. Cyrillic and Pinyin letters with International Phonetic Alphabet (IPA) transliterations
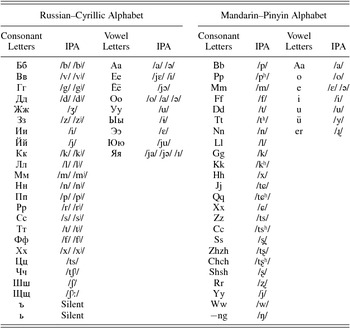
The Russian phoneme–letter inconsistencies result from four major irregularities, which are predictable. First, many phonemes share the same letter; 14 of the consonant letters <б в г д з л м н п р с т ф х> represent two phonemes: the hard and soft phonemes. Palatalization is indicated by the following letter rather than as part of the letter itself. For example, <ф> can represent either /f/ or /fʲ/; the softness of the consonant is indicated by the letter following it, either a soft sign <ь> or a vowel letter, and is entirely predictable. Second, the 6 vowel phonemes are represented by 10 vowel letters. The letters <а э о ы у и > represent the simple vowel phonemes, and <я е ё ю> represent these vowels preceded by [j] in word-initial position or after a vowel (e.g., её [“her”]) is pronounced as /jɛjɔ/). When these 4 vowels follow a consonant, they indicate that the preceding consonant is soft. Third, the soft sign <ь> does not represent a phoneme; rather, it indicates softness of a preceding consonant when the consonant is not followed by a vowel. The <ь> indicates that the final consonant, /t/, in брать (“to take”) is palatalized (/bratʲ/) in contrast to the lack of <ь> in брат (“brother”) where the /t/ is nonpalatalized (/brat/). Fourth, the Russian orthographic system does not represent vowel reduction, and therefore, the vowel letters can represent different vowel sounds depending on where the stressed syllable is. For example, in the word окнó (“window”), <o> is pronounced as /o/ in the second syllable (stressed) but as /a/ in the first syllable (unstressed).
In addition to Chinese characters, Mainland Chinese Mandarin uses Pinyin, a highly systematic and transparent alphabetic system, While the Pinyin orthography is relatively transparent, it does have two major spelling irregularities that are highly predictable. First, Pinyin has two digraphs that represent single phonemes; <sh> and <ng> represent /ʂ/ and /ŋ/, respectively. Second, as well as diphthongs, Mandarin also has triphthongs (i.e., glide–vowel–glide sequences), which are represented differently depending on whether or not they are preceded by a consonantal onset (Bassetti, Reference Bassetti2006). Before the nucleus vowel, the glides /w/ and /j/ are represented orthographically as <w> and <y> when they do not follow a consonant onset. In contrast, they are represented as <u> and <i> when they do follow a consonant onset. In addition, when not preceded by a consonant onset, the main vowel in a triphthong is represented orthographically, but when preceded by a consonant, the main vowel is not represented orthographically. For example, in duì /twej/ (“team/group”) and wèi /wej/ (“place/location”), the triphthong is /wej/. However, in w èi, the first glide is spelled as <w> because there is no preceding consonant, but in d u ì, the glide is spelled as <u> because it is preceded by the consonant /t/. When not preceded by a consonant, each segment of the triphthong is represented orthographically: in wèi, /wej/ = <wei>. However, when preceded by a consonant, only the glides and not the main vowel are represented orthographically: in duì, /wej/ = <ui>.
METHOD
Participants
Twenty-five participants who were all native speakers of Canadian English participated. Twelve participants were learning Mandarin Chinese, and 13 participants were learning Russian. These learners were recruited from University of Victoria language classes, and both groups had completed the equivalent of four semesters of language learning (participant level of proficiency was determined by completed courses). Only those volunteers who reported no auditory or visual impairments (either natural or corrected) were accepted for the study. The Mandarin learners had no previous experience with learning Mandarin; however, other languages learned by participants in this group include Japanese, French, Korean, Cantonese, German, Spanish, Italian, and Attic Greek. Similarly, the Russian learners had no previous experience with Russian, but other language learned included French, Italian, Japanese, Spanish, Polish, German, Java, Ainu, and Gaelic. To determine participant orthographic proficiency, they completed a spelling dictation task of L1 and L2 words (after completing the experimental task). The Mandarin group had a 97% accuracy rate for spelling English words and 92% accuracy for spelling Mandarin words. The Russian group had a 98% accuracy rate for spelling the English words and 93% accuracy for spelling the Russian words.
Experimental stimuli and materials
The stimuli were Russian and Mandarin words containing between one and five letters and/or phonemes. These target words were organized according to two binary variables: consistency and homophony. Consistency (matched vs. mismatched) refers to whether the number of letters in the target words equaled the number of phonemes in those words.
-
• matched: the number of letters = the number of phonemes; for example, Russian всё /fsʲɔ/ (“everything”)
-
• mismatched: the number of letters ≠ the number of phonemes; for example, Mandarin huáng /xwaŋ/ (“yellow”)
Homophony (homophone vs. nonhomophone) refers to whether the L2 words have cross-language homophone.
-
• nonhomophone: does not have a homophonous counterpart in English; for example, Russian плащ /plaʃː/ (“raincoat”)
-
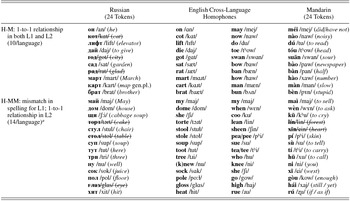
• homophone: has a homophonous counterpart in English; for example, Mandarin méi /mej/ (“did not/have not”) homophonous with English may /mej/.
These variables resulted in four experimental conditions: matched homophones, mismatched homophones, matched nonhomophones, and mismatched nonhomophones. For the mismatched homophones, the mismatch was always in the L1, and the L2 words always had one-to-one letter to phoneme correspondence. For example, Russian cтул /stul/ (“chair”) and Mandarin wèn /wɤn/ (“to ask”) have consistent correspondences while the English counterparts, stool /stuɫ/ and when /wɛn/, have inconsistent correspondences. The lists of cross-homophones (words that sound very similar across the L1 and L2) for the Russian and Mandarin target words were determined in consultation with linguistically trained native speakers of English, Russian, and Mandarin. These homophones were then judged by native English speakers to determine their degree of homophony between the L2 and L1 cross-language homophones. Fourteen nonlinguistically trained native English speakers were asked to rate the “accendedness” of the L2 words on a 9-point Likert scale. While some of the L2 target words are not true homophones with their English counterparts, only L2 words (see Appendix A, Table A.1) that the listeners identified as sounding like nativelike pronunciations of English words were included in the analyzed data.
Two other important considerations dictated the target word selection. First, because the data analyses investigate (a) the interaction between the L1 orthography and the L2 orthography and (b) the effect of the L2 orthography on L2 phonology, the participants needed to be familiar with the words orthographically and phonologically. Based on the vocabulary both the Russian and Mandarin learners learn in their language classes, a limited number of cross-language homophones fit all the parameters (including the parameters that these target words be monosyllabic and contain between one and five phonemes). As a result, the matched homophones contained only 10 target words as opposed to the 14 target words in the other conditions. Second, due of the nature of Mandarin Chinese syllable structure, it was impossible to avoid having target words containing diphthongs (e.g., gòu /kow/ [enough], maì /maj/ [to sell], tóu /tʰow/ [head], and nào /naw/ [noisy]). This research assumes all diphthongs in open syllables are two units: a vowel plus an offglide /j/ or /w/ (Lehiste & Peterson, Reference Lehiste and Peterson1961; Rogers, Reference Rogers2000). For example, the word go (an open syllable) is phonemicized as /gow/ with the offglide /w/ while the word pole (a closed syllable) is phonemicized as /po:ɫ/. Thus, accurate responses will be those responses where listeners count two phonemes for each diphthong heard.
Each language group consisted of 52 tokens (14 matched nonhomophone + 14 mismatched nonhomophone + 14 matched homophone + 10 mismatched homophone). For the matched homophones, 10 had consistent one-to-one correspondences and had English counterparts with consistent correspondences (e.g., Russian лифт /lift/ “elevator” [4 letters/4 phonemes] and English lift /lɪft/ [4/4]). For the mismatched homophones, 14 had consistent correspondences, but the English counterparts had inconsistent correspondences (e.g., Mandarin wèn /wɤn/ “to ask” and English when /wɛn/; see Appendix A, Table A.2).
One female native speaker from each language recorded the target words for her L1. The words were recorded in a sound-treated booth with Audacity (Version 1.2.6) using a Grove Tubes GT57 large diaphragm microphone and a Mackie 1402-VLZ3 mixer. All individual sound files were normalized for loudness using the software WavNormalizer (Version 1.0). To confirm that the stimuli were good, natural representations of the target words, three native speakers for each language judged the nativeness of the chosen target words. Each native speaker listened to the target words and wrote the words he or she heard using the orthography of his or her particular language (i.e., Cyrillic for Russian and Pinyin for Mandarin; see Table 2). The speakers also indicated any tokens that were problematic (e.g., unclear, mispronounced, unnatural). All problematic tokens were discarded, rerecorded, and judged again. In addition, all three judges in each group of native speakers agreed on the “correct” spelling of each word.
Table 2. Stimuli paradigm for Russian and Mandarin words
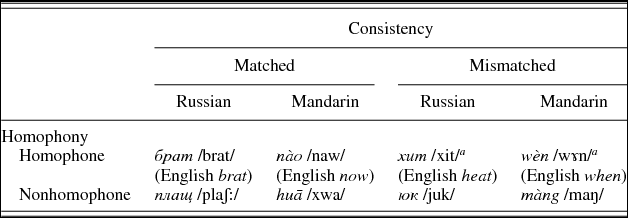
a The mismatch was always in the English counterpart for the mismatched-homophone condition.
Experimental materials and tasks
The software E-prime Pro (Version 2.0.1.97) was used to create the experimental task and recorded both accuracy (ACC) and response times (RTs). The participants completed a phoneme counting task (e.g., Ehri & Wilce, Reference Ehri and Wilce1980; Liberman et al., Reference Liberman, Shankweiler, Fischer and Carter1974; Treiman & Cassar, Reference Treiman and Cassar1997), indicating the number of individual “sounds” they counted in a given auditorily presented word. Because cognitive requirements for phoneme counting include perceiving separate phonemes, holding the target in memory, and segmenting sound units (Yopp, Reference Yopp1988), phoneme counting is commonly used as a measure of phoneme awareness. Since Liberman et al. (Reference Liberman, Shankweiler, Fischer and Carter1974) first developed the phoneme counting task for testing children's phoneme awareness, it has been used to measure adults’ phoneme awareness and the influence of orthographic factors (Treiman & Cassar, Reference Treiman and Cassar1997). Therefore, the phoneme counting task is an appropriate measure here to help determine the effects of L1 and L2 orthographic knowledge on L2 phoneme awareness.
Procedure
The participants received verbal instructions in English (L1). They were told that while all the words were one-syllable words, these words varied in the number of sounds (between one and five sounds) within each word. All participants were nonlinguistically trained (i.e., none had taken a linguistics or phonetics course); therefore, to avoid confusion, the term sound (rather than the term phoneme) was used when explaining the tasks and speaking to the participants about the research project. The participants were asked to count the individual sounds that they heard in each particular word and indicate their responses by pressing the number on a keyboard (1, 2, 3, 4, or 5) that corresponded to the number of sounds they heard in each word. They only had 10 s within which to respond, and if they did not respond in that time, the program would record a “nonresponse” and move on to the next word. In cases where the participants were unsure, they were encouraged to make their best guess. E-prime recorded the number responses and response times (the time between the onset of the stimuli and the point at which the participants pressed one of the response keys) for each participant. The participants first completed a practice session to familiarize them with the equipment and task and to make sure that all the data collection equipment (i.e., the data collection software program, computer monitor, headphones, etc.) was functioning properly. After the practice session, participants had another opportunity to ask questions before moving on to the actual task.
Data analyses
The data were analyzed according to three independent factors: group (Russian, Mandarin), homophony (homophone, nonhomophone), and consistency (matched, mismatched) and two dependent factors: ACC and RTs. A three-way factorial analysis of variance (ANOVA) with repeated measures was conducted to calculate significance using SPSS. The significance level was set at .05 such that any p value less than .05 was considered statistically significant. The data were analyzed using a three-way by-subjects ANOVA with one between-subjects factor, group, and two within-subjects factors, homophony and consistency.
For each participant, the ACC of each condition was calculated by adding the number of correct responses in that condition and dividing that number by the total number of tokens in that condition. The RTs (ms) were calculated as the time between the offset of the stimulus token and the point at which the participants pressed one of the response keys. Participant RTs were used to calculate the mean RTs for each condition by averaging the RTs of the accurate responses only. The ACCs and RTs for all the participants in each condition were then averaged for the overall mean ACCs and RTs for that condition.
Exploration of the raw ACC and RT data showed that ACC data were negatively skewed (the frequent scores were clustered at the higher end and the tail points toward the lower scores) and the RT data were positively skewed (the frequent scores were clustered at the lower end and the tail points toward the higher scores). Therefore, square root transformations (for ACC) and natural log (for RTs) were applied to normalize the data. Via the transformation process, the ACC values were reversed such that the transformed values (reflected accuracy [RACC]) are interpreted as “error” not “accuracy.” Thus, in the following tables and figures, higher RACC numbers mean lower accuracy (higher error). For participant RTs (logged RTs), logging the RTs brought extreme, long RT values in closer to the faster RT values, that is, pulling in the positive skew. In these calculations, the natural log e base is 2.718. In addition, using boxplots for each individual, RT outliers were identified and not factored into the mean logged RT values.
RESULTS
This research undertook three comparisons of the data to (a) determine the effect of L2 orthography on L2 phoneme perception (the matched vs. mismatched nonhomophones), (b) determine the effect of L1 orthography on L2 phoneme perception (the matched vs. mismatched homophones), and (c) tease apart the effects of the L1 orthography and the L2 orthography on L2 phoneme perception (the matched nonhomophone vs. mismatched homophones). The hypotheses relating to these comparisons were (a) matched nonhomphones would be counted more accurately and faster than mismatched nonhomphones, (b) matched homophones would be counted more accurately and faster than mismatched homophones, and (c) matched nonhomophones would be counted more accurately and faster than mismatched homophones.
Table 3 provides the descriptive statistics for the Russian and Mandarin data and contains the mean (standard deviation) RACC and logged RTs for each group according to each experimental condition. Also included in this table are the mean differences between the matched and mismatched words for homophone type and group. The ACC and RT differences were calculated by subtracting the mean matched values from the mean mismatched values. Positive values represent higher accuracy and faster responses for the matched words than the mismatched words, and negative values represent lower accuracy and slower responses. The positive differences between the matched and mismatched words for the homophones and nonhomophones show that matched words were generally counted more accurately and faster than mismatched words.
Table 3. Mean (standard deviation) RACC and LRTs for Russian and Mandarin groups across all four experimental conditions
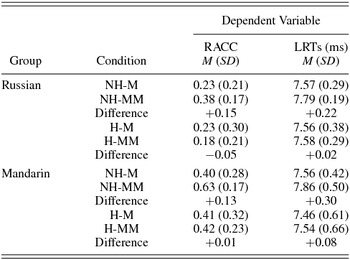
Note: RACC, Reflected accuracy; LRTs, logged response times; NH-M, nonhomophone matched; NH-MM, nonhomophone mismatched; H-M, homophone matched; H-MM, homophone mismatched.
Figure 1 illustrates the RACC results for the matched and mismatched nonhomophones and homophones. The data were analyzed using a three-factor (2 × 2 × 2) repeated measures ANOVA with group (Russian, Mandarin) as the one between-subjects factor and homophony (nonhomophone, homophone) and consistency (match, mismatch) as the within-subjects factors. The main effects of homophony, consistency and group, and the two-way interaction of Homophony × Consistency were significant: homophony: F (1, 23) = 5.269, p < .05; consistency: F (1, 23) = 4.814, p < .05; group: F (1, 23) = 8.395, p < .01; Homophony × Consistency: F (1, 23) = 14.348, p < .001. All other effects were not significant: Homophony × Group: F (1, 23) = 0.001; Consistency × Group: F (1, 23) = 0.767; Homophony × Consistency × Group: F (1, 23) = 0.007; not significant at p > .05. The effects of consistency and group were tested separately for each homophony type. For the nonhomophones, the tests indicate significant main effects of consistency and group: consistency: F (1, 23) = 17.977, p < .001; group: F (1, 23) = 8.211, p < .01, but no significant interaction of Consistency × Group, F (1, 23) = 0.677, p > .05. Thus, the Russian group is significantly more accurate at counting phonemes than the Mandarin group in the nonhomophones, and both groups are significantly more accurate at counting phonemes in matched words than in mismatched words. For the homophones, the follow-up tests indicate a significant main effect for group, F (1, 23) = 2.812, p < .05, with the Russian group more accurately counting phonemes than the Mandarin group. Neither the main effect of consistency nor the interaction of Consistency × Group were significant: consistency: F (1, 23) = 0.097; Consistency × Group: F (1, 23) = 0.402; all effects not significant at p > .05, indicating that the groups show the same degree of accuracy on the matched and mismatched homophone words.
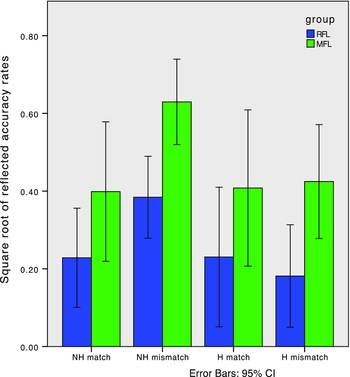
Figure 1. Mean Russian and Mandarin reflected accuracy values comparing the matched and mismatched nonhomophones and homophones.
Finally, to confirm the lack of L1 effect and further test for any L1 and L2 interaction effects, an additional analysis compared the matched nonhomophone and the mismatched homophone word data. This analysis tested the effects of consistency and group for the matched nonhomophones and the mismatched homophones. It indicated a significant main effect of group, F (1, 23) = 7.089, p < .05, such that the Russian group counted phonemes more accurately than the Mandarin group. However, the test indicated no main effect for consistency or interaction of Consistency × Group: consistency: F (1, 23) = 0.030; Consistency × Group: F (1, 23) = 0.454; both effects not significant at p > .05, such that there was no accuracy difference between the matched nonhomophones and the mismatched homophones for either group, again suggesting that L1 orthography does not have an effect on L2 phoneme perception at the intermediate stage of learning.
The RTs provided an additional opportunity to investigate the effects of L1 and L2 orthography on L2 phoneme perception (Figure 2). The logged RTs were analyzed using a three-factor (2 × 2 × 2) repeated measures ANOVA with group (Russian, Mandarin) as the between-subjects factor and homophony (nonhomophone, homophone) and consistency (match, mismatch) as the within-subjects factors. The main effects of homophony and consistency as well as the interaction of Homophony × Consistency were significant: homophony: F (1, 23) = 15.054, p < .001; consistency: F (1, 23) = 18.929, p < .001; Homophony × Consistency: F (1, 23) = 8.736, p < .01. All other effects were not significant: group: F (1, 23) = 0.010; Homophony × Group: F (1, 23) = 1.362; Consistency × Group: F (1, 23) = 0.838; Homophony × Consistency × Group: F (1, 23) = 0.003; effects not significant at p > .05. Tests for the effects of consistency for each homophony type separately, collapsed over group, indicate a significant effect of consistency for nonhomophones, with participants counting phonemes faster in matched nonhomophones than in mismatched nonhomophones, F (1, 23) = 34.613, p < .001, but the effect was not significant for the homophones, F (1, 23) = 0.755, p > .05. Like the accuracy data, the effects of consistency, collapsed over group, on the matched nonhomophones and mismatched homophones were conducted to tease apart the effects of the L1 and L2 orthographies. This analysis indicates no significant effect of consistency, F (1, 23) = 0.016, p > .05, such that neither consistency type was significantly faster than the other.

Figure 2. Mean Russian and Mandarin response times comparing the matched and mismatched nonhomophones and homophones.
In sum, the analyses of the matched and mismatched nonhomophones show that both groups are more accurate and faster at counting phonemes in matched nonhomophones than in mismatched nonhomophones, suggesting that L2 orthographic knowledge was present in the auditory phoneme counting task and influenced L2 phoneme perception and counting. In addition, the analyses of the matched and mismatched homophones show that while the Russian learners counted phonemes more accurately overall than the Mandarin learners, neither group was more accurate or faster at counting phonemes in the matched homophones than in the mismatched homophones. Because the mismatches in the mismatched homophones were always in the L1 associations and the L2 orthographic spellings of the mismatched homophones were always consistent, these results suggest that the L1 orthography did not negatively impact L2 phoneme perception for the learners. These results are supported by the final comparison, which show no significant difference between the matched nonhomophones and the mismatched homophone words. These results further suggest that for bilingual learners with intermediate-level proficiency, L1 orthography did not negatively affect L2 phoneme perception although this may not be the case for novice learners (e.g., Pytlyk, Reference Pytlyk2012) or monolinguals (e.g., Erdener & Burnham, Reference Erdener and Burnham2005). L2 orthographic knowledge appears to have overrode L1 orthographic knowledge for both L2 groups.
DISCUSSION
While previous research has established that L1 orthographic knowledge exerts an unavoidable influence on L1 phonology (e.g., Burnham, Reference Burnham2003; Castles et al., Reference Castles, Holmes, Neath and Kinoshita2003; Ehri & Wilce, Reference Ehri and Wilce1980; Perin, Reference Perin1983; Treiman & Cassar, Reference Treiman and Cassar1997), little research has investigated the effect of orthography on L2 phoneme awareness.
L2 orthographic effects
The analyses suggest that L2 orthographic knowledge influenced the L2 phoneme perception of the intermediate Russian and Mandarin adult learners (who have already mastered L1 reading) because both groups counted phonemes more accurately and faster in matched nonhomophones than in mismatched nonhomophones. L2 orthographic knowledge appears to be a contributing factor for their performance in an auditory phoneme counting task: L2 orthography appears to facilitate L2 phoneme perception and counting in L2 words with consistent letter–phoneme correspondences and hinders L2 phoneme perception and counting in L2 words with inconsistent correspondences.
These results support other findings on letter–phoneme inconsistencies. Even in the absence of visual stimulation, research has shown that orthographic knowledge influences auditory processing (e.g., Ziegler & Ferrand, Reference Ziegler and Ferrand1998; Ziegler et al., Reference Ziegler, Ferrand and Montant2004). The current findings support the theory that orthographic knowledge is coactivated with auditory information, and once it is activated, orthographic knowledge influences how and what phonemes are perceived even when visual stimulation is absent (Chéreau et al., Reference Chéreau, Gaskell and Dumay2007; Taft et al., Reference Taft, Castles, Davis, Lazendic and Nguyen-Hoan2008). Because “the orthographic code cannot be suppressed even when it hinders performance” (Perin, Reference Perin1983, p. 138), orthographic interference is unavoidable (e.g., Burnham, Reference Burnham2003; Treiman & Cassar, Reference Treiman and Cassar1997). Dijkstra, Roelofs, and Fiews (Reference Dijkstra, Roelofs and Fieuws1995) propose that when completing phoneme-monitoring tasks such as phoneme detection, listeners may keep both the orthographic representation and the phonological representation in mind even if it is detrimental to performance. The automatic coactivation makes separating orthographic knowledge and phonological representation virtually impossible (Treiman & Cassar, Reference Treiman and Cassar1997), and as a result, individuals are more “susceptible to unwanted interference” from the orthographic code (Landerl et al., Reference Landerl, Frith and Wimmer1996, p. 12), and have “difficulty focusing on phonemes and ignoring the letters” (Gombert, Reference Gombert1996, p. 762). While most of this previous research investigated orthographic effects on monolingual speakers, the current research investigated bilingual speakers (with intermediate-level competency) and demonstrated that individuals are susceptible to interference from not only their L1 orthographic code but also their L2 orthographic code.
This research suggests that L2 orthographic knowledge facilitates phoneme perception in words with consistent letter–phoneme correspondences but hinders phoneme perception in words with inconsistent correspondences. One possible explanation for why may lie in the assumptions literate speakers/learners make about the relationship between letters and phonemes. In general, speakers of languages with alphabetic representations function under the assumption that one letter represents one phoneme and “take for granted that letters correspond to individual phonemes” (Cook, Reference Cook2004, p. 8). Therefore, where the number of letters does not match the number of phonemes in a word, listeners are faced with conflicting information (orthographic and phonetic), and they must reconcile their underlying assumption about the relationship between letters and phonemes with the phonetic information they hear. To do this, listeners must spend extra cognitive resources reconciling the letter–phoneme contradictions, and trying to reconcile these contradictions results in processing difficulties, which, in turn, results in lower accuracy rates and longer processing times. In contrast, when the number of letters equals the number of phonemes, listeners do not receive any conflicting information and as such are very accurate at counting phonemes. The orthographic information supports the phonetic information, and the listeners do not experience processing difficulties.
The language-specific nature of orthographic effects
The results here suggest that the effect of orthographic knowledge may be language specific for listeners literate in languages with alphabetic orthographies, though the strength of the effect may depend on the depth of the L1 and L2 orthographies (see the discussion on orthographic transparency below). The results suggest that by an intermediate learning level, the L2 orthography is entrenched enough to exert its own effect on L2 speech perception and replaces the effect of L1 orthography. If L1 orthographic information had overrode L2 orthographic information, both groups should have been more accurate and faster at counting phonemes in matched homophones than in mismatched homophones. Instead, the mismatched homophones were counted as accurately and as quickly as the matched homophones, suggesting that the L1 orthography did not intrude on L2 phoneme perception. The L2 listeners did not appear to fall back on their L1 orthographic knowledge to help them count phonemes in their L2. Rather, the difference between the matched and mismatched nonhomophones (i.e., L2 words with no L1 associations) and the lack of difference between the matched and mismatched homophones (i.e., L2 words with L1 associations where the mismatch was in the L1) suggest that the L2 listeners relied more heavily on their L2 orthographic knowledge than they did on their L1 orthography knowledge.
The final analysis (matched nonhomophones vs. mismatched homophones) sought to tease apart the potential orthographic effects of L1 and L2. The hypothesis predicted that matched nonhomophones would be more accurately counted than mismatched homophones because the listeners would have been positively influenced by the consistent L2 letter–phoneme correspondences of the matched nonhomophones, and they would have been negatively influenced by the inconsistent L1 letter–phoneme correspondences of the mismatched homophones. However, this comparison yielded no significant accuracy or response differences between the matched nonhomophones (no L1 association) and mismatched homophones (L1 association). This final comparison supports the above results suggesting that L1 orthography does not negatively affect L2 phoneme perception to the same degree as predicted and that L2 orthography may play more of a stronger role.
In short, the results here suggest that intermediate Russian and Mandarin adult learners (with a Canadian English L1) are less influenced by their L1 orthography than their L2 orthography. Further, L2 orthographic knowledge appears to override the more established L1 orthographic knowledge for both the Russian and Mandarin learners. These language-specific findings raise some very important questions. First, how do the L2 orthographic and phonological systems become so closely connected? How does L2 phonology become linked with L2 orthography? Second, what promotes the formulation of the orthography–phonology link?
Regarding the first question, research has suggested that orthography and phonology are coactivated in the native language because learning orthographic representations of phonemes serves to reorganize and restructure the L1 phonological system (Burnham, Reference Burnham2003; Perre, Pattamadilok, Montant, & Ziegler, Reference Perre, Pattamadilok, Montant and Ziegler2009). Burnham (Reference Burnham2003) claims that once children start to acquire an alphabet, the orthographic knowledge reorganizes the L1 phonological system and the two systems become interdependent. Ziegler et al. (Reference Ziegler, Muneaux and Grainger2003) suggest that orthographic knowledge “provides an additional constraint in driving segmental restructuring” (p. 790). Event-related potential research has measured online activation of phonological codes and supports the restructuring hypothesis by demonstrating that orthographic knowledge influences the functional organization of the temporal–parietal junction (Perre et al., Reference Perre, Pattamadilok, Montant and Ziegler2009). After reorganizing and restructuring the phonological system, orthographic knowledge is so intimately linked to the phonological system that readers cannot avoid thinking about the letters even when specifically instructed not to do so (Landerl et al., Reference Landerl, Frith and Wimmer1996) and in the absence of visual stimulation (e.g., Ziegler & Ferrand, Reference Ziegler and Ferrand1998; Ziegler et al., Reference Ziegler, Muneaux and Grainger2003, Reference Ziegler, Ferrand and Montant2004).
If L1 orthographic learning does force a reorganization of L1 phonology, is it possible that L2 orthography forces an organization of L2 phonology? In L1, native speakers learn phonology before orthography, but in L2 language classrooms, learners generally learn phonology and orthography concurrently. Therefore, learning L2 orthography cannot “reorganize” the L2 phonology. However, does learning L2 orthography help to organize L2 phonology? The results suggest that perhaps learning L2 orthography contributes to the organization of the L2 phonology, making these two systems interconnected, which in turn would suggest that they are coactivated in L2 speech processing and reduce the impact L1 orthography has on the L2. Coutsougera (Reference Coutsougera2007) maintains that “beginner learners are forced [original emphasis] into reaching some kind of phonological awareness [in L2] so that they are able to start reading and writing” and that “learners urgently need to establish letter-phoneme correspondences in order to decode writing” (pp. 3–4). As a result of this urgency, L2 learners build the L2 letter–phoneme correspondences upon the foundation of L1 orthographic assumptions and principles. If true, the question then becomes how (or at what point) does L2 orthography organize L2 phonology?
In general, research indicates that L1 phonology is sharpened and reorganized at two important junctures of L1 acquisition: in infancy with exposure to the ambient/oral language (Kuhl, Reference Kuhl2000) and in childhood with the onset of learning to read (e.g., Burnham, Reference Burnham1986, Reference Burnham2003; Carroll, Reference Carroll2004; Castro-Caldas, Petersson, Reis, Stone-Elander, & Ingvar, Reference Castro-Caldas, Petersson, Reis, Stone-Elander and Ingvar1998; Olson, Reference Olson1996; Treiman & Cassar, Reference Treiman and Cassar1997; Ziegler et al., Reference Ziegler, Ferrand and Montant2004). With respect to the second juncture, Olson argues that learning to read results in “learning to hear speech in a new way” (p. 95) because it provides an abstract conceptual model that creates speech categories and brings those categories into consciousness. Similarly, Castro-Caldas et al. (Reference Castro-Caldas, Petersson, Reis, Stone-Elander and Ingvar1998) propose that learning to read modifies the phonological system by adding a “visuographic” dimension and opens the door for new language-processing possibilities such that different and more areas of the brain are activated in literates than in nonliterates. Burnham (Reference Burnham2003) maintains that children's heightened language-specific speech perception is related to the onset of reading; it is a critical developmental step in L1 phonological acquisition because (as mentioned above) learning to read forces a reorganization of the L1 phonology, which in turn creates a codependency between the two systems whereby they are coactivated, and they reciprocally influence each other. More important, previous research suggests that orthographic effects are not limited to skilled readers; orthographic knowledge affects speech perception and awareness as soon as children begin to learn how their L1 speech is represented in print (Treiman & Cassar, Reference Treiman and Cassar1997).
If learning to read is a critical juncture in L1 phonological development, is it possible that learning to read in the L2 is also a critical juncture in L2 phonological development? This research suggests that by the time adult learners achieve an intermediate-level proficiency in their L2, L2 orthographic knowledge appears to exert a greater influence on L2 phoneme perception than L1 orthographic knowledge. According to Burnham (Reference Burnham2003), language-specific speech perception is heightened following and significantly related to the onset of reading instruction. One possible explanation for the current results is that learning to read in L2 may organize the L2 phonology and lead learners to develop a codependency between the L2 orthography and L2 phonology. As a result of the new codependency, the intermediate L2 learners appeared to be able to disassociate themselves from L1 orthographic knowledge and use L2 orthographic information as a new crutch when performing L2 phoneme awareness tasks.
What promotes a link between orthography and phonology? Orthographic transparency appears to dictate the formulation and strength of the link. A new L2 codependency may be strengthened by the degree of orthographic transparency of the L2 orthographic system. Children who learn more transparent orthographies (like Greek, Spanish, and Welsh) acquire orthography–phonology relations rapidly in the first year of reading instruction, while children who learn less transparent orthographies (like English and French) acquire these relations slowly over the course of many years (e.g., Goswami et al., Reference Goswami, Porpodas and Wheelwright1997, Reference Goswami, Gombert and De Barrera1998; Seymour et al., Reference Seymour, Aro and Erskine2003; Spencer & Hanley, Reference Spencer and Hanley2003). Seymour et al. (Reference Seymour, Aro and Erskine2003) estimate that after the first year of literacy learning, readers of English require a minimum of an additional 2.5 years of learning to gain mastery of word recognition, a mastery that most readers of transparent orthographies gain by the end of the first year of learning. In addition, children who learn transparent orthographies like Spanish and Welsh develop orthographic representations that encode individual letter–phoneme correspondences; in contrast, children who learn opaque orthographies like English and French develop orthographic representations that encode sequences of letter–phoneme correspondences (i.e., rimes; Goswami et al., Reference Goswami, Porpodas and Wheelwright1997, Reference Goswami, Gombert and De Barrera1998).
Could orthographic transparency have also been a factor in the relatively rapid development and strength of L2 orthographic and phonological associations observed in the current research? Both the Russian and Mandarin orthographies are more transparent than the English orthography. If learning more transparent orthographies facilitates rapid development of letter–phoneme correspondences, this may explain the current results, which suggest that the L2 learners gathered enough experience in their language classes to create and foster L2 orthographic and phonological associations that were strong enough to withstand any potential interference from L1 orthographic knowledge.
Another possible explanation for the seemingly language-specificness of the orthographic effects may come from the nature of the experimental design itself (Dijkstra, Grainger, & van Heuven, Reference Dijkstra, Grainger and van Heuven1999; Dijkstra, van Jaarsveld, & ten Brinke, Reference Dijkstra, van Jaarsveld and ten Brinke1998; Schulpen, Dijkstra, Schriefers, & Hasper, Reference Schulpen, Dijkstra, Schriefers and Hasper2003). L1 interference is dependent on whether participants are presented with stimuli from both languages or just one. When homophonous stimuli from both languages are presented, the homophone representations from both languages are activated and suppress each other thereby creating phonological inhibition effects (i.e., competition between two phonological representations of homophones). However, when presented with stimuli from only one language, only representations from the target language are activated and nontarget language interference is reduced. Thus, because the participants were presented with stimuli from only the L2, it may have limited the amount of L1 interference.
Two types of orthographic knowledge
If L2 orthography exerts its own influence on L2 phoneme perception once it is learned, the next question is how does L1 orthographic knowledge affect L2 orthographic knowledge's influence on L2, if at all? Researchers are currently debating the issue of L1 orthographic transfer. On the one hand, some researchers have provided evidence that L1 orthographic knowledge does transfer into and affect nonnative speech processing (e.g., Bassetti, Reference Bassetti2006; Ben-Dror et al., Reference Ben-Dror, Frost and Bentin1995; Holm & Dodd, Reference Holm and Dodd1996; Sun-Alperin & Wang, Reference Sun-Alperin and Wang2011, Vokic, Reference Vokic2011; Wade-Woolley, Reference Wade-Woolley1999). On the other hand, other researchers have provided evidence that L1 orthographic knowledge does not transfer into and affect nonnative speech processing (e.g., Wang, Park, & Lee, Reference Wang, Park and Lee2006; Wang, Perfetti, & Liu, Reference Wang, Perfetti and Liu2005). The L2 results here appear to support the later argument, suggesting that L2 orthographic knowledge supersedes L1 orthographic knowledge and affects L2 processing.
On the side advocating L1 orthographic transfer, researchers argue that L1 orthographic knowledge shapes L2 orthographic knowledge, which in turn shapes L2 phoneme perception (Bassetti, Reference Bassetti2006; Erdener & Burnham, Reference Erdener and Burnham2005; Holm & Dodd, Reference Holm and Dodd1996; Vokic, Reference Vokic2011). For Holm and Dodd (Reference Holm and Dodd1996), L2 learners draw on their L1 literacy skills and strategies and apply them to their L2 orthography. Once literate in their L1 alphabet and when learning an L2 alphabet, L2 learners transfer their L1 knowledge of the orthographic mapping principle (i.e., what sound units [morphemes, syllables, or phonemes] graphemes map on to) and assumptions about the function of the orthography and its relationship to phonology. These assumptions are learned via the L1 orthography acquisition, and they are transferred and applied to the L2 orthographic relationships. The abstract ideas about the function of orthographic representation are acquired when adults/children become literate in their L1, and the mapping principle and its assumptions are then transferred into their L2 learning and applied to the L2 orthographic–phonological associations where learners interpret their L2 orthography through the “prism” of their L1 orthography (Vokic, Reference Vokic2011). For example, Bassetti (Reference Bassetti2006) discovered that English learners of Mandarin most often counted and segmented Mandarin rimes as they are spelled. She argues that learners interpret Pinyin orthography in terms of English letter–phoneme conversion rules rather than the L2 orthographic conventions and concludes then that L1 orthographic knowledge transfers into L2 and shapes the mental representations of Mandarin Chinese rimes. Similarly, Vokic (Reference Vokic2011) concluded that because Spanish has highly regular letter–phonological mappings (i.e., phonemic), native Spanish speakers cannot easily recover the English phonology from the highly irregular letter–phonological mappings (i.e., morphophonemic) in English despite the fact that /ɾ/ is also part of the Spanish consonant inventory.
On the other side of the debate, researchers have found that orthographic skills do not transfer from L1 to L2. In a series of experiments involving biliteracy, Wang and colleagues (Sun-Alperin & Wang, Reference Sun-Alperin and Wang2011; Wang et al., Reference Wang, Perfetti and Liu2005, Reference Wang, Park and Lee2006) sought to determine whether orthographic skills transfer from L1 to L2 in learning to read. Wang et al. investigated Chinese (L1)–English (L2) bilingual children (2005) and Korean (L1)–English (L2) bilingual children (2006). Using combined phonological and orthographic tasks and regression analyses, Wang et al. discovered that phonological skills transferred from L1 to L2, but orthographic skills did not. Neither Chinese nor Korean orthographic skills could predict reading skills in English, suggesting that the visual orientations of graphemes may contribute to the language specificness of their respective orthographies and that disparity in mapping principles does not lend itself to L1–L2 transfer. From there, Sun-Alperin and Wang (Reference Sun-Alperin and Wang2011) investigated orthographic transfer in two languages where the orthographic representation not only shares the same mapping principle (i.e., letters to phonemes) but also resembles each other, Spanish (L1) and English (L2). They hypothesized that because the two orthographies were closely related visually, the Spanish orthography (L1) may facilitate English reading and spelling. Their results showed that when closely related, the orthographic skills are transferred into and facilitate L2 reading but not L2 spelling, indicating “an independence of orthographic processing as it relates to spelling” (p. 612).
How can we reconcile the findings from Bassetti (Reference Bassetti2006) and Vokic (Reference Vokic2011) with those from Wang et al. (Reference Wang, Perfetti and Liu2005, Reference Wang, Park and Lee2006) and Sun-Alperin and Wang (Reference Sun-Alperin and Wang2011)? One possible explanation is that orthographic knowledge is composed of at least two types of knowledge: abstract and operational. When we consider the notion of orthographic knowledge not as a single entity but rather as a combination of the abstract and operational components, the findings from this and previous research no longer appear to contradict each other. Abstract orthographic knowledge refers to the assumptions literates have about the function of orthographic representation and its relationship to the phonological representation. Children/adults acquire abstract knowledge through the process of becoming literate in their L1, which creates a set of assumptions upon which all other orthographic effects rest. The general assumption surrounding alphabets (like the Roman and Cyrillic alphabets) is that individual letters represent individual phonemes (Cook, Reference Cook2004; Coutsougera, Reference Coutsougera2007). In contrast, the general assumption surrounding logographies (like the Chinese characters) is that individual letters represent individual morphemes (Cook, Reference Cook2004; Coulmas, Reference Coulmas2003). In the case of alphabetic systems, literates use their abstract knowledge about the function of orthographic representation to interpret the operational letter–phoneme correspondences. Operational orthographic knowledge refers to the actual letter–phoneme correspondences in any given language. For example, English literates know that the letter <t> corresponds to the phoneme /t/, <x> corresponds to the phonemes /ks/, <c> corresponds to either /k/ or /s/, and so on. Similarly, Russian literates know that the letter <у> corresponds to the phoneme /u/, <г> corresponds to the phonemes /g/ or /gʲ/, <ю> corresponds to the phonemes /ju/, and so on. In L1, operational orthographic knowledge is also acquired as children become literate in their L1 orthography.
While both abstract and operational knowledge are acquired concurrently in L1 acquisition, it may not always be the case for L2 orthographic knowledge. In L2 learning, when both L1 and L2 orthographies share visual orientation (e.g., a linear alphabetic orientation), abstract L1 orthographic knowledge transfers into L2 and contributes to a perceived relationship between L2 orthography and phonology. The L1 assumptions about the function of orthography transfer into L2 letter–phoneme associations such that learners assume that the L2 orthography functions in relation to the L2 phonology in much the same way that the L1 orthography functions in relation to the L1 phonology. Then, through this perceived relationship (whether accurate or not), learners acquire new operational orthographic knowledge about L2 letter–phoneme correspondences. Once this new L2-specific operational knowledge is acquired, it supersedes L1 operational knowledge. Bassetti's (Reference Bassetti2006) findings support the notion of two types of orthographic knowledge: she reported that Mandarin words were segmented as they were spelled (L1 abstract knowledge), but they were segmented with Mandarin pronunciations of each individual letter (L2 operational knowledge).
The current research adds insight into L1 orthographic transfer and facilitation, namely, with respect to L2 speech perception for adult intermediate English learners of Russian and Mandarin. It provides preliminary evidence that abstract orthographic knowledge behaves differently from operational orthographic knowledge. First, the performance differences between the matched and mismatched nonhomophones suggest that learners apply their assumptions about the function of orthography and its relationship to phonology (i.e., abstract knowledge) that they learn in L1 orthographic acquisition to their L2. Second, the homophone results indicate that once learners become literate in their L2, they do not transfer L1 operational knowledge; rather, they employ their L2 operational knowledge to aid them in phoneme awareness tasks. The findings here suggest that abstract orthographic knowledge transfers when L1 and L2 share the same visual orientations (i.e., alphabetic letters). Listeners rely on their L1 assumptions about how letters are mapped onto phonemes and apply those assumptions to the relationship between L2 letters and phonemes (e.g., Ben-Dror et al., Reference Ben-Dror, Frost and Bentin1995; Wade-Woolley, Reference Wade-Woolley1999). In addition, operational orthographic knowledge appears to be language specific for L2 speech perception; once L2 learners are literate in their L2, they rely on actual L2 letter–phoneme associations. The current results provide no evidence for operational L1 orthographic transfer in L2 speech perception by the intermediate state of learning; the results suggest that at this stage, L2 orthographic knowledge takes over and influences L2 phoneme perception. While this idea of different types of orthographic knowledge is still in its infancy and has yet to be thoroughly tested, it does offer a new way of thinking about orthographic knowledge and possibly allows us to unify the seemingly conflicting accounts of L1 orthographic transfer into L2.
Conclusion
This research focused on investigating how orthographic representation influences sound perception in L2 learning for adult intermediate language learners and whether orthographic representation overrides phonemic information in L2 speech processing. The relationship between orthographic representation and phonemic representation in nonnative speech processing has been largely ignored. This research characterizes and explores that relationship. It sheds light on how much influence orthographic representation exerts on learners’ perceptions of phonemes in L2. Research of this kind contributes to the sparse body of research on orthography's relationship to nonnative sound processing and provides a non-English L2 perspective on the speech-processing literature. Much more research needs to be conducted, especially investigating the impact of L1 and L2 orthographies on learners with different L1 backgrounds (shallow to deep) and with varying levels of proficiency (beginner to advanced) in shallow and deep L2s.
APPENDIX A
Tables A.1 and A.2 provide the Russian and Mandarin target words.
Table A.1. Russian and Mandarin NH word lists

Table A.2. Russian and Mandarin H wordlists
ACKNOWLEDGMENTS
The research presented in this article is part of a larger doctoral research project supported by a Pacific Century Scholarship (Provincial Government of British Columbia, Canada) and a Social Sciences and Humanities Research Council Doctoral Fellowship (752-2010-1157). I thank my supervisory committee members, Drs. Sonya Bird (supervisor), John Archibald, Julia Rochtchina, and Patrick Bolger, and external examiner Dr. Bruce Derwing for their invaluable guidance and feedback. I also extend a very special thank you to all participants who generously gave up their free time to participate in this research. Finally, I express my sincere thanks to the two anonymous reviewers and Associate Editor Patricia Cleave for their careful and constructive reviews.







