


It is well known that second language (L2) learners have difficulty perceiving and producing certain nonnative phonemes. Because of these acquisitional difficulties, a number of training studies have investigated whether L2 learners can overcome the difficulties, the results of which have revealed positive training effects in laboratory and classroom settings (Lambacher, Martens, Kakehi, Marasinghe, & Molholt, Reference Lambacher, Martens, Kakehi, Marasinghe and Molholt2005; Lee & Lyster, Reference Lee and Lyster2016a; Saito, Reference Saito2013). Of particular interest is the association between speech production and perception whereby L2 learners’ perception accuracy serves as a predictor of their production accuracy. Several empirical studies (e.g., Bradlow, Pisoni, Akahane-Yamada, & Tohkura, Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997; Hardison, Reference Hardison2003; Thomson, Reference Thomson2011; Wang, Jongman, & Sereno, Reference Wang, Jongman and Sereno2003) have found that L2 learners’ production accuracy increases as a result of perception training without any explicit production training. Considering the importance of L2 speech perception and its training in L2 phonological development, the previous literature leads us to the following pedagogical question: what are the most effective training techniques in L2 speech perception training?
Bradlow (Reference Bradlow, Edwards and Zampini2008) and Hardison (Reference Hardison, Gass and Mackey2012) argued that successful training involves stimulus variability (e.g., multiple talkers and multiple exemplars) and corrective feedback (CF) during training. Similarly, Wang and Munro (Reference Wang and Munro2004) also emphasized the roles of CF in their L2 speech perception training study. However, CF per se as a technique has unfortunately been out of the spotlight in the field of speech perception training. Recently, Lee and Lyster (Reference Lee and Lyster2016a) conducted an experimental study in which they employed CF as a key technique during perception training and provided empirical evidence for its effectiveness. Furthermore, while criticizing the use of simple and uniform types of CF (i.e., right or wrong) commonly employed in the field, Lee and Lyster (Reference Lee and Lyster2016b) examined the use of various types of CF and revealed differential effects for different CF types during L2 speech perception training.
Acknowledging that the ultimate goal of L2 speech perception training is to improve L2 learners’ production as well as perception performance, Hardison (Reference Hardison, Gass and Mackey2012) argued that successful perception training should transfer to other skills such as production. Given that CF has the potential to play a key role in successful perception training as demonstrated by Lee and Lyster (Reference Lee and Lyster2016a, Reference Lee and Lyster2016b), it is timely to probe the extent to which CF treatment facilitates skill transfer (i.e., from receptive skills to productive skills). Accordingly, the current study aims to explore (a) whether L2 learners’ production performance benefits from perception training without any explicit production training and, (b) if so, whether the benefits depend on perception training techniques, particularly different types of CF. In addition, given that the participants in the current study were the same learners as in Lee and Lyster (Reference Lee and Lyster2016b), which investigated their changes in perception accuracy by CF type, the present study attempts to delve into the relationship between improvement in perception accuracy and improvement in production accuracy by adopting the perception accuracy data from Lee and Lyster (Reference Lee and Lyster2016b).
By investigating whether the effects of perception training on production accuracy vary depending on CF type, the current study is expected to provoke methodological debates concerning L2 speech perception training and to expand horizons in regard to the roles attributed to CF. In addition, the present study is expected to provide empirical evidence with respect to the relationship between L2 speech production and perception.
BACKGROUND
Perception-first view in L2 phonological acquisition
In the realm of L2 phonological acquisition, a relationship between L2 speech production and perception has been postulated, which in turn has been both theoretically and empirically addressed in terms of the following questions: Are the two modalities connected? If so, does one precede the other? Although not espousing a perception-first view explicitly, the perceptual assimilation model (PAM, Best, Reference Best and Strange1995; PAM-L2, Best & Tyler, Reference Best, Tyler, Bohn and Munro2007) posits that speakers employ articulatory gestures as the basis of speech perception. Furthermore, the speech learning model (SLM; Flege, Reference Flege and Strange1995; Flege, Schirru, & MacKay, Reference Flege, Schirru and MacKay2003) puts forward that well-formed phonological representation at the perception level is a sine qua non for targetlike sensory motor skills and accurate L2 speech production. In particular, SLM hypothesizes that nonnative phonemes are categorized as either new sounds or similar sounds based on a L2 learner's first language (L1) phonemic inventory. The model predicts that L2 learners, therefore, need more time and intervention to acquire similar sounds compared to new sounds.
The perception-first view in L2 phonological acquisition has been supported by many empirical studies such as those by Bradlow et al. (Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997), Hardison (Reference Hardison2003), Thomson (Reference Thomson2011), and Wang et al. (Reference Wang, Jongman and Sereno2003), which showed that the production accuracy of L2 learners benefited from perception training without any production-related training. However, some studies (de Jong, Hao, & Park, Reference de Jong, Hao and Park2009; Goto, Reference Goto1971; Sheldon & Strange, Reference Sheldon and Strange1982) challenged the relationship between L2 speech production and perception. In particular, Baker, Trofimovich, Flege, Mack, and Halter (Reference Baker, Trofimovich, Flege, Mack and Halter2008) argued that inaccurate perceptual performance is more likely a matter for L2 beginners. In a similar vein, according to Kissling (Reference Kissling2014) and Strange and Shafer (Reference Strange, Shafer, Edwards and Zampini2008), the discrepant findings might result from methodological issues or from other variables that influence L2 speech production (e.g., time spent using the L2 outside the classroom, age, and attitude). In this respect, it is less contentious in the field of study that there is a link between L2 speech production and perception at certain levels and that perception precedes production (for details, see Colantoni & Steele, Reference Colantoni and Steele2008). Neurological studies have also underpinned this claim (Pulvermüller & Shumann, Reference Pulvermüller and Schumann1994; Watkins & Paus, Reference Watkins and Paus2004).
It is arguable that L2 learners difficulty perceiving certain nonnative phonemes is not due to basic auditory capabilities. Rather, it may be the case that certain phonetic differences (i.e., acoustic differences) result in phonological differences (i.e., differences in meaning) in one language, whereas the same phonetic differences do not necessarily result in phonological differences in the other language. According to Strange's (Reference Strange2006, Reference Strange2007) automatic selective perception model, infants are pushed to tune into acoustic cues, which are crucial for processing their L1 while ignoring other irrelevant cues. According to this account, online L1 speech perception by adults is processed via highly overlearned selective perceptual routines (SPRs).
When L2 learners perceive L2 phonemes, the SPRs predispose them to select and integrate acoustic cues that are crucial in processing their L1, but not with respect to their L2. Consequently, L2 learners fail to perceive L2 phonemes correctly. In spite of such perceptual difficulties, it is possible for L2 learners to create and develop SPRs that are more targetlike over their life span. For instance, Flege's SLM (Flege, Reference Flege and Strange1995; Flege et al., Reference Flege, Schirru and MacKay2003) and related empirical research (e.g., Flege, Reference Flege, Burmeister, Piske and Rohde2002) suggest that the ability to modify L2 speech perception patterns is maintained well into adulthood. As Bradlow (Reference Bradlow, Edwards and Zampini2008) explained, however, the “retuning” procedure to develop targetlike perception patterns is not something that occurs in an incidental manner. Instead, it appears to require a great deal of language exposure and explicit training.
As for explicit training, previous research has investigated the effects of several training techniques, mostly in laboratory settings and particularly via computer-assisted perception training. For example, high-variability phonetic training methods, such as multiple talkers (Lively, Logan, & Pisoni, Reference Lively, Logan and Pisoni1993), auditory–visual stimuli (Hardison, Reference Hardison2003), and hyperarticulated/exaggerated stimuli (Iverson, Hazan, & Bannister, Reference Iverson, Hazan and Bannister2005; Uther, Knoll, & Burnham, Reference Uther, Knoll and Burnham2007) have all been tested in laboratory settings. A fading stimulus presentation scheme (e.g., Pruitt, Reference Pruitt1995) and various training tasks such as oddity discrimination, categorical discrimination, and identification tasks (Strange & Shafer, Reference Strange, Shafer, Edwards and Zampini2008) were also adopted in laboratory-based training studies. Outside of a typical laboratory setting, Lee and Lyster (Reference Lee and Lyster2016a) conducted perception training in a simulated classroom context, employing several pedagogical techniques such as awareness tasks and relevant L2 instruction. A close look at the literature in all these cases helped us to find one common training technique, namely, CF intervention in response to L2 learners’ errors, leading to the question: what are the roles of CF in L2 learning?
Roles of CF in L2 learning
The effectiveness of CF in L2 learning has been demonstrated in many studies (for meta-analysis and narrative reviews, see Li, Reference Li2010; Lyster & Saito, Reference Lyster and Saito2010; Lyster, Saito, & Sato, Reference Lyster, Saito and Sato2013). The learning mechanisms of CF are explained by several L2 acquisition theories such as skill acquisition theory (DeKeyser, Reference DeKeyser, Doughty and Williams1998, Reference DeKeyser and Robinson2001; Lyster & Sato, Reference Lyster, Sato, García Mayo, Gutierrez-Mangado and Martínez Adrián2013), the output hypothesis (Swain, Reference Swain, Gass and Madden1985, Reference Swain, Cook and Seidlhofer1995), and the interaction hypothesis (Long, Reference Long, Ritchie and Bhatia1996). With respect to different types of CF, for example, there are two main groups in the CF literature: one provides L2 learners with the target forms (e.g., recasts) and the other withholds the target forms and pushes L2 learners to produce modified output (e.g., prompts). Recasts are considered effective because they provide L2 learners with opportunities to notice the gap between interlanguage forms and target forms, whereas prompts are considered effective because they provide L2 learners with signals to retrieve target forms on their own and thus to engage in practice opportunities that lead to a restructuring of their L2 interlanguage system. The absence of any type of CF is thought to prevent L2 learners from attaining more targetlike accuracy, as their interlanguage representations become automatized routines.
Notwithstanding the richness of the CF literature, a disproportionate number of studies have investigated the effects of CF on productive skills (i.e., spoken and written outcomes), exclusively with regard to morphosyntatic errors. As Lyster et al. (Reference Lyster, Saito and Sato2013) concluded, the CF field would benefit from investigating the effects of different CF types on various linguistic targets such as L2 phonological and pragmatic features. Ellis, Loewen, and Erlam (Reference Ellis, Loewen and Erlam2006) and McDonough (Reference McDonough and Mackey2007) also suggested that the field aim to explore differential learning outcomes resulting from different types of CF. In this sense, a recent study by Lee and Lyster (Reference Lee and Lyster2016b) investigated the effects of CF on L2 speech perception training (i.e., a domain of receptive rather than productive skills) and compared four different CF types motivated by the existing CF literature (Lyster et al., Reference Lyster, Saito and Sato2013). In their study, 100 Korean learners of English were assigned to five different groups (i.e., four different CF types plus a no-CF control) and participated in eight computer-assisted perception training sessions. During the training sessions, whereas the control group received no CF, participants in each treatment group received one of three auditory CF types (a rejection followed by the target form; a rejection followed by the learner's nontarget form; or a rejection followed by both the target and nontarget forms), and a fourth group received a wrong visual type of CF. Overall, the CF treatment groups outperformed the control group at the immediate and delayed posttests. Within the CF groups, the auditory CF groups performed better than the wrong visual CF group, which failed to outperform the control group regarding trained words recorded by unfamiliar voices. Among the auditory CF groups, the group given auditory CF contrasting both target and nontarget forms showed the highest performance.
RESEARCH QUESTIONS
Successful perception training should enable L2 learners to improve not only their perception but also their production accuracy (e.g., Hardison, Reference Hardison, Gass and Mackey2012). In the same vein, while acknowledging the effectiveness of CF in perception training, Lee and Lyster (Reference Lee and Lyster2016a) speculated that “CF may affect L2 learners’ perception first and may then trigger successful production of L2 sounds” (p. 36). In order to test this speculation and investigate whether the benefits of L2 speech perception training implemented with various types of CF extend to L2 speech production, the current study extends Lee and Lyster's (Reference Lee and Lyster2016b) study to investigate the following research questions:
-
1. As a result of computer-assisted perception training targeting the English vowel pairs /i/–/ɪ/ and /ɛ/–/æ/, to what extent do Korean learners of English improve their production accuracy regarding the target pairs in perceptually trained words and in perceptually untrained words?
-
2. To what extent do the perception training effects on production accuracy differ according to three different types of auditory CF (i.e., rejection plus target form; rejection plus nontarget form; and rejection plus target and nontarget forms) and one type of visual CF (i.e., “wrong” appears on computer screen)?
-
3. Does improvement in perception accuracy resulting from computer-assisted perception training predict improvement in production accuracy?
Because the participants in the current study are the same as those in Lee and Lyster (Reference Lee and Lyster2016b), the perception accuracy data from the earlier study are used here in order to answer research question 3.
METHODOLOGY
Participants
Participants in the current study consisted of 100 Korean learners of English (73 females, 27 males), with a mean age of 30.3 (SD = 9.69). They were the same participants who had participated in Lee and Lyster (Reference Lee and Lyster2016b). Most of them were students learning English as a foreign language in private or university language institutions, while residing in the Montreal area. Their average length of residence in English-speaking countries was 21.8 months (SD = 18.1), 19.1 months (SD = 19.5), 20.1 months (SD = 18.8), 18.9 months (SD = 19.7), and 22.1 months (SD = 18.1) in each of the five different groups. A majority of them had lived abroad after the age of 18. In addition, they self-reported that they were intermediate or advanced learners based on their length of learning experience in formal instructional settings (M = 9.8 years, SD = 8.62).
A total of 64 native speakers of English (50 females, 14 males) also participated in the study, serving as L1 speakers for stimuli (n = 4), L1 baseline participants (n = 20), and L1 raters for speech tokens recorded by the L1 baseline and L2 participants (n = 40). All the English native participants were L1 English speakers residing in the Montreal area with a mean age of 22.9 (SD = 5.23). They were North American English speakers coming from the United States and English-speaking provinces in Canada and were attending universities in Montreal, Canada. Those who were recruited as the L1 raters did not have any background in linguistics or applied linguistics and were thus considered inexperienced raters in the current study.
Procedure
The 100 Korean learners of English took a pretest, and the 20 L1 baseline participants completed a baseline test at the research laboratory. After the pretest, the Korean participants were randomly assigned to one of four CF treatment groups (three auditory CF groups, one visual CF group) or the control group (20 participants per group) in which they participated in eight computer-assisted perception training sessions scheduled over a 2-week period. Those who were in the four CF treatment groups received a specific type of CF when they made perceptual errors during the perception training sessions:
-
• the target group heard a rejection followed by the target form,
-
• the nontarget group heard a rejection followed by the nontarget form,
-
• the combination group heard a rejection followed by the target and nontarget forms, and
-
• the wrong group saw “wrong” on computer screen.
Those who were in the control group participated in the same perception training; however, they did not receive any CF when they made any perception errors. An immediate posttest was conducted on the last day of the training sessions, and 2 weeks later a delayed posttest was administered. All the tests were designed to measure the participants’ production accuracy at a controlled-speech level. Specifically, to measure their production accuracy, speech tokens were judged by the 40 L1 raters to assess the extent to which the perception training including different types of CF improved the L2 participants’ production accuracy.
Target stimuli
Stimuli for the perception training were prepared with the aid of the four native speakers of English. Vowels are known to play an important role in intelligibility (Bent, Bradlow, & Smith, Reference Bent, Bradlow, Smith, Bohn and Munro2007), and previous studies have shown that L2 learners experience more difficulty acquiring L2 vowels than L2 consonants (Munro & Derwing, Reference Munro and Derwing2008; Neri, Cucchiarini, & Strik, Reference Neri, Cucchiarini and Strik2006). Nevertheless, there is a general lack of research targeting vowels in L2 speech perception training (Thomson, Reference Thomson2011). The current study thus targeted two pairs of English vowels (/i/–/ɪ/ and /ɛ/–/æ/). Several speech learning theories such as the PAM-L2 (Best & Tyler, Reference Best, Tyler, Bohn and Munro2007) and the SLM (Flege, Reference Flege and Strange1995; Flege et al., Reference Flege, Schirru and MacKay2003) predict that Korean learners of English will encounter difficulties regarding the target pairs owing to their absence in the Korean vowel inventory (Lee, Reference Lee1993). For example, according to PAM-L2, each target pair might show an assimilation pattern of single-category or category-goodness difference, and Korean learners of English will thus have difficulty categorizing each vowel in each target pair. In addition, the SLM hypothesizes that the English vowel pairs /i/–/ɪ/ and /ɛ/–/æ/ are each somewhat similar to the Korean phonemes /i/ and /ɛ/ and, therefore, that Korean learners of English need more L2 experience and intervention to acquire these two contrasts properly. These difficulties have been confirmed by a number of empirical studies (e.g., Baker, Trofimovich, Mack, & Flege, Reference Baker, Trofimovich, Mack, Flege, Fisch, Scarabela and Do2002; Flege, Bohn, & Jang, Reference Flege, Bohn and Jang1997; Ingram & Park, Reference Ingram and Park1997; Tsukada et al., Reference Tsukada, Birdsong, Bialystok, Mack, Sung and Flege2005). Tsukada et al. (Reference Tsukada, Birdsong, Bialystok, Mack, Sung and Flege2005), for example, revealed that native speakers of English identified Korean adults’ productions of the target pairs as various phonemes: for instance, the productions of English /i/ and /ɪ/ as /i/, /ɪ/, /e/, or /ɛ/, and the productions of English /ɛ/ and /æ/ as its counterpart, respectively.
Eighteen sets of English minimal pairs with /i/–/ɪ/ and another 18 sets of English minimal pairs including /ɛ/–/æ/ were targeted (see Table 1). These stimuli are the same as those used in Lee and Lyster (Reference Lee and Lyster2016b). The target stimuli were monosyllabic consonant–vowel–consonant English words with various onsets and codas. They were selected from the Corpus of Contemporary American English (Davies, Reference Davies2008). Except for the words underlined in Table 1, all the words were of high frequency in the corpus (>15 occurrences/million words). In addition, in order to control for any influence of word unfamiliarity, the Korean participants were asked which words they knew listed in Table 1 prior to the pretest. The first author then explained, in Korean, the meaning of the words that they did not know and modeled their pronunciation.
Table 1. Target stimuli

In Table 1, the trained words refer to the items occurring during the perception training, whereas the untrained words are those that did not occur during the perception training. The word pairs with asterisks (4 of the 12 pairs of trained words, 3 of the 6 pairs of untrained words) were employed in the production ratings to determine whether the perception training would improve the L2 learners’ production of the target pairs.
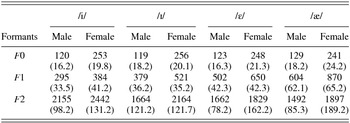
The four English L1 speakers for stimuli (two males: M1 and M2; two females: F1 and F2) were asked to read each stimulus twice embedded in a carrier sentence “I said [X]” after which the target stimuli were extracted from the carrier sentences and digitalized at 44,100 Hz using Praat (Boersma & Weenink, Reference Boersma and Weenink2013). One out of two productions from each speaker, considered a good exemplar, was selected by the first author and research assistants. The final stimuli were acoustically analyzed (see Table 2), which confirmed that they were valid samples compatible with previous acoustic studies (e.g., Hillenbrand, Getty, Clark, & Wheeler, Reference Hillenbrand, Getty, Clark and Wheeler1995; Yang, Reference Yang1996).
Table 2. Mean (standard deviation) formant values (Hz) for each target vowel according to gender
Perception training
Based on its attested effectiveness (Wang & Munro, Reference Wang and Munro2004), forced-choice identification training was implemented in the current study. The training was delivered through a computer-assisted perception training program, which was specifically designed for the purposes of this research by using programmed web-based computer scripts that included JavaScript, PHP, and MySQL (Nixon, Reference Nixon2012). The perception training was operationalized as individual training with a computer. A minimal pair of stimuli and a relevant sound file were provided to the L2 participants. For example, a sound file conveying the word “ship” played after which two orthographic options (sheep and ship) appeared on the computer screen. The L2 participants were in turn asked to answer the question “What did s/he say?” (i.e., to select what they heard). The participants were allowed to take as much time as they needed to answer the question. In addition, because there was a repeat button available, they were also permitted to listen to the sound file repeatedly if they wished. Once they chose the answer, the appropriate CF treatment was provided depending on their answer and group; then, the next trial ensued. For those who were in the control group, however, the next trial was automatically provided as soon as they selected their answer.
For the CF intervention, Speakers M1 and F1 and Speakers M2 and F2 were paired. For example, if Speaker M1 provided the stimulus, Speaker F1 provided the relevant CF, and vice versa. Speakers M2 and F2 were matched in the same manner. When learners chose the wrong answer, different types of CF were provided in each treatment group. The following describes each type of CF for the four treatment groups, using the example of a learner selecting “sheep” in response to the auditory stimulus “ship”:
-
• Target group: “No, s/he said ‘ship.’”
-
• Nontarget group: “No, not ‘sheep.’”
-
• Combination group: ”No, s/he said ‘ship,’ not ‘sheep.’”
-
• Wrong group: A word card with “wrong” written in red appears on the screen.
After the CF intervention, a pop-up message in the form of “okay?” was immediately shown on the screen with the intention of helping the L2 learners to notice their error and CF. The learners needed to click “yes” to move onto the next trial. If the learner chose the right answer (i.e., “ship” in the above example), positive oral confirmation saying “yes” was given to those in the three auditory CF groups and the word “right” appeared in blue on the screen for those in the wrong group. The next trial ensued right after the positive affirmation.
One training session comprised a total of 384 trials: the 48 trained words recorded by Speakers M1, M2, F1, and F2 with one repetition. All the trials were randomized for each participant in each training session. The L2 learners were asked to complete eight training sessions within a 2-week period, each of which took approximately 1 to 1.5 hr. Finally, it is important to note that the current study was designed to investigate the benefits of L2 speech perception training with different types of CF on L2 learners’ production. Therefore, the training per se did not involve any production training; none of the tasks in the training required the L2 learners to produce the target words orally.
Production measurement
The L2 learners were audiorecorded on three occasions: in a pretest, an immediate posttest, and a delayed posttest. One single instrument was utilized to elicit the participants’ productions. The learners were prompted to produce English sentences orally using the 28 target words listed in Table 1 with asterisks. Their utterances were audiorecorded in the research office in a researcher–participant dyadic setting. The first author or research assistants showed seven worksheets one by one, each of which had 4 target words, and then asked the learners to produce utterances using a carrier sentence “I said [X].” The learners were asked to produce the target words only once in each recording session, to equalize the number of utterances across participants. If they articulated the given words more than once, the first utterance was taken into account for the analysis. If they missed any words, the first author or research assistants induced them to produce utterances with the missing words at the end of each test.
Finally, the 20 L1 baseline participants took the same production test as the L2 learners, in order to obtain a native-speaker sample (baseline) for subsequent ratings. The purpose of having the L1 baseline participants was to ensure that the judgment results from the 40 inexperienced raters were reliable (i.e., L1 baseline participants were expected to receive consistently high ratings while variability was expected in the ratings of L2 participants).
Native-speaker judgments
In order to measure the intelligibility and comprehensibility of the target vowel pairs, the 40 inexperienced L1 raters listened individually to the speech tokens produced by the L1 baseline and L2 participants. The 28 target words produced by each participant at each test had been extracted from each participant's utterances and then digitalized at 44,100 Hz using Praat (Boersma & Weenink, Reference Boersma and Weenink2013). As a result, a total of 8,960 speech tokens (28 words × 100 L2 participants × 3 testing sessions = 8,400, 28 words × 20 L1 baseline participants = 560) were collected. The 8,960 speech tokens were randomly divided into 8 blocks (1,120 tokens per block). Each block was judged by five different raters (8 blocks × 5 raters = 40 inexperienced L1 raters). Each block was again divided into Day 1 and Day 2 subblocks (560 tokens/day), which were judged by the same five raters on 2 separate days within a week. Each daily task took approximately 1 hr to complete.
The judgment tasks were designed using Praat (Boersma & Weenink, Reference Boersma and Weenink2013) in order to measure intelligibility and comprehensibility of the speech tokens as suggested by Derwing and Munro (Reference Derwing and Munro2015). The L1 raters were asked to categorize a given sound (i.e., intelligibility measurement) and then grade its goodness (i.e., comprehensibility measurement). For instance, a sound file intended as the word “ship” was played and then three options (sheep, ship, and not sure/neither) appeared on the computer screen. Once the raters selected one of the three options, a 5-point Likert scale appeared along with the following instruction: “Judge how good the pronunciation is between 1 (difficulty to understand) and 5 (easy to understand).” There was a repeat button available; the raters were allowed to change their choices until they clicked “next” to judge the next sound files.
In order to quantify the participants’ production accuracy, one score was computed from the intelligibility and comprehensibility measurement tasks for each speech token employing the following coding scheme: considering the above example “ship,” if a rater selected the intended word (i.e., choosing ship), its comprehensibility measurement (i.e., from 1 to 5) was recorded as its accuracy score. However, 0 was given regardless of its comprehensibility measurement if a rater did not choose the intended word in the intelligibility measurement (i.e., choosing sheep or not sure/neither).
Interrater reliability and data verification/preparation for statistical analyses
The Cronbach α was calculated in order to verify interrater agreement among the 40 inexperienced raters. Within the perceptually trained words, 0.82, and 0.78 were the α values for the target pairs /i/–/ɪ/ and /ɛ/–/æ/, respectively. With respect to the perceptually untrained words, values of 0.75 and 0.73 were obtained for each target pair. The reliability indexes were considered acceptable, following the benchmark value of 0.70–0.80 in L2 research studies (Larson-Hall, Reference Larson-Hall2010). Thus, by averaging all raters’ scores, one mean score for each target pair in each word context (i.e., the trained and untrained words) at each test was computed as the production accuracy for each participant. Using the standardized z score of 3.29, it was confirmed that there were no outliers in the data set. In addition, the 20 L1 baseline participants showed ceiling effects for the target pairs, /i/–/ɪ/ (M = 4.37, SD = 0.75 in the trained words; M = 4.56, SD = 0.71 in the untrained words) and /ɛ/–/æ/ (M = 4.21, SD = 0.81 in the trained words; M = 4.29, SD = 0.89 in the untrained words), thus confirming that the judgment results from the raters were reliable.
Finally, in order to investigate whether improvement in perception accuracy is a significant predictor of improvement in production accuracy, we adopted the perception accuracy data from the participants in Lee and Lyster (Reference Lee and Lyster2016b) because they are the same as in the current study. Table 3 summarizes the participants’ production and perception accuracy across groups and time for the trained words. Similarly, Table 4 displays their production and perception accuracy across groups and time for the untrained words.
Table 3. Mean (standard deviation) accuracy scores over time by group and target pair for trained words (n = 20 per group)

Note: Production accuracy: 1 (difficulty to understand) ~ 5 (easy to understand).
Table 4. Mean (standard deviation) accuracy scores over time by group and target pair for untrained words (n = 20 per group)
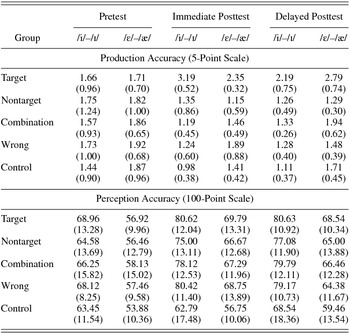
Note: Production accuracy: 1 (difficulty to understand) ~ 5 (easy to understand).
Between-group analyses before the training and amount of feedback instances per group
To ensure that the five experimental groups were similar in production accuracy prior to the perception training, the participants were randomly assigned to each group. In addition, several sets of univariate analysis of variance (ANOVA) with an α level of 0.05 were conducted to detect any group differences in their accuracy before the training. The statistical assumptions for all the ANOVAs (e.g., Levene tests) were at first confirmed. The analyses confirmed that the groups were similar in their production accuracy for the pair /i/–/ɪ/ in the trained words, F (4, 95) = 0.38, p = .825, and in the untrained words, F (4, 95) = 0.31, p = .870, and for the pair /ɛ/–/æ/ in the trained words, F (4, 95) = 0.44, p = .782, and in the untrained words, F (4, 95) = 0.19, p = .941.
In order to ensure that one particular CF group did not receive more CF than the other CF groups, the number of CF occurrences was documented per group, revealing that the participants in the four CF groups received a similar amount of CF per training session (i.e., 384 trials): 99.2 (SD = 35.2), 105.2 (SD = 52.7), 91.6 (SD = 45.2), and 106.1 (SD = 36.7) CF occurrences per training session in the target, nontarget, combination, and wrong groups. An ANOVA with an α level of 0.05 revealed that there were no group differences in terms of the amount of CF, F (3, 76) = 0.48, p = .696, with the Levene test insignificant, p = .164.
RESULTS
Analysis 1: Gains in production accuracy
Mixed-design ANOVAs were conducted to investigate the gains in production accuracy after the perception training in the trained and untrained words, respectively. Each mixed-design ANOVA was designed with group as a between-subject independent variable (target, nontarget, combination, wrong, and control) and time as a within-subject independent variable (pretest, immediate posttest, and delayed posttest) with an α level of 0.05. Statistical assumptions such as data normality, Levene tests, and Mauchly tests were verified before carrying out each mixed-designed ANOVA. Significant main effects of time (irrespective of the group variable) were not of primary interest and thus not further analyzed. Of primary interest were the significant Time × Group interaction effects, which entailed pairwise comparisons of each posttest and the pretest for each group using the Bonferroni correction. In the same vein, the effect sizes between each posttest and the pretest were calculated using the Cohen d (Cohen, Reference Cohen1988) and classified as small (0.50 ≤ d < 1.10), medium (1.10 ≤ d < 1.60), or large (1.60 ≤ d) for within-group contrasts (Plonsky & Oswald, Reference Plonsky and Oswald2014).
As for the trained words, there was a significant main effect of time regarding the pair /i/–/ɪ/, F (2, 190) = 5.26, p = .006, and the pair /ɛ/–/æ/, F (2, 190) = 13.14, p < .001. The analyses also revealed a significant Time × Group interaction for the pair /i/–/ɪ/, F (8, 190) = 3.00, p = .003, and for the pair /ɛ/–/æ/, F (8, 190) = 6.89, p < .001.
Following up each interaction effect, pairwise comparisons found that the target group's production accuracy of the pair /i/–/ɪ/ at each posttest was significantly higher than that of the pair at the pretest (p = .001, d = 1.13 at the immediate posttest; p = .021, d = 0.93 at the delayed posttest). The target group's production accuracy of the pair /ɛ/–/æ/ was also significantly higher at each posttest than that of the pair at the pretest (p = .002 d = 1.96 at the immediate posttest; p = .015, d = 0.68 at the delayed posttest). Regarding the nontarget group, there was no significant improvement in its production accuracy of the pair /i/–/ɪ/ between each posttest and the pretest (p = .101, d = 0.54 at the immediate posttest; p = .418, d = 0.39 at the delayed posttest). However, its production accuracy of the pair /ɛ/–/æ/ at each posttest was significantly higher than that of the pair at the pretest (p = .002, d = 0.96 at the immediate posttest; p = .015, d = 0.78 at the delayed posttest). As for the other three groups, the analyses failed to reach significance between each posttest and the pretest regarding the two pairs /i/–/ɪ/ and /ɛ/–/æ/ and the effect sizes were small.
With respect to the untrained words, the analyses did not find a significant main effect of time regarding the pair /i/–/ɪ/, F (2, 190) = 2.33, p = .100, and the pair /ɛ/–/æ/, F (2, 190) = 2.71, p = .069. However, the analyses revealed a significant Time × Group interaction for the pair /i/–/ɪ/, F (8, 190) = 8.44, p < .001, and for the pair /ɛ/–/æ/, F (8, 190) = 6.42, p < .001.
Following up each interaction effect, pairwise comparisons regarding the target group revealed that its production accuracy of the pair /i/–/ɪ/ was significantly higher at the immediate posttest than at the pretest (p < .001, d = 1.97); however, its production accuracy at the delayed posttest was not (p = .098, d = 0.61). As for the pair /ɛ/–/æ/, the target group's production accuracy was significantly higher at each posttest compared to the pretest (p = .007, d = 1.18 at the immediate posttest; p < .001, d = 1.50 at the delayed posttest). Regarding the nontarget group, the only significant improvement was for the pair /ɛ/–/æ/ at the immediate posttest (p = .005; d = 0.82). No other comparisons for this group reached significance. Finally, with regard to the other three groups, there were no statistically significant changes in their production accuracy of either sound pair between each posttest and the pretest, and the effect sizes were small.
To summarize, concerning the target group, the production accuracy of both pairs in the trained words was significantly higher at both posttests with large to small effect sizes. The production accuracy of the pair /ɛ/–/æ/ in the untrained words was significantly higher at both posttests with medium effect sizes, whereas the production accuracy of the pair /i/–/ɪ/ in the untrained words was significantly higher only at the immediate posttest with a large effect size. As for the nontarget group, there were no significant changes in the production accuracy of the pair /i/–/ɪ/ in the trained and untrained words. As for the pair /ɛ/–/æ/, the production accuracy in the trained words was significantly higher at both posttests; however, the production accuracy in the untrained words was significantly higher at the immediate posttest only. All the effect sizes regarding the nontarget group were small. With respect to the combination, wrong, and control groups, there were no significant changes in the production accuracy of either pair in the trained and untrained words. Again, all the effect sizes pertaining to those groups were small.
Analysis 2: Relationship between improvement in perception accuracy and improvement in production accuracy
In order to delve into whether improvement in perception accuracy as a result of perception training is a significant predictor of improvement in production accuracy, regression analyses were conducted with an α level of 0.05 in the trained and untrained words each. To reiterate, we adopted the perception accuracy data from Lee and Lyster (Reference Lee and Lyster2016b) to quantify improvement in participants’ perception accuracy. In particular, the improvement in perception accuracy was computed by averaging two improvement scores; one was obtained by subtracting the scores of the immediate posttest from the scores of the pretest, and the other was prepared by subtracting the scores of the delayed posttest from the scores of the pretest. The improvement in production accuracy was also quantified in the same manner. Before conducting each regression analysis, the assumption of linearity was verified; homoscedasticity, normality, and independence were also examined. The regression analyses were conducted including all groups (i.e., all 100 Korean participants) except for the native baseline speakers.
As for the trained words, improvement in perception accuracy of the pair /i/–/ɪ/ was a significant predictor of improvement in its production accuracy (R 2 = .05, b = 0.02, SE = 0.01; β = 0.22, t = 2.24, p = .028). Similarly, improvement in perception accuracy of the pair /ɛ/–/æ/ was a significant predictor of improvement in its production accuracy (R 2 = .05, b = 0.02, SE = 0.01; β = 0.22, t = 2.27, p = .025). With respect to the untrained words, however, improvement in perception accuracy of the pair /i/–/ɪ/ was not a significant predictor of improvement in production accuracy of the pair (R 2 = .01, b = 0.01, SE = 0.01; β = 0.08, t = 0.79, p = .431). The regression analysis regarding the pair /ɛ/–/æ/ also failed to identify improvement in perception accuracy as a significant predictor of improvement in production accuracy (R 2 = .01, b = 0.01, SE = 0.01; β = 0.09, t = 0.91, p = .365).
DISCUSSION
Differential effects of L2 speech perception training on production accuracy
The first noteworthy finding in the current study is that, overall, participants improved their production accuracy of the target pairs with the aid of the L2 speech perception training. However, the extent to which the production accuracy of the L2 learners benefited from the perception training depended on CF type. That is, those who were in the target and nontarget groups improved their production accuracy after the perception training, whereas those in the combination, wrong, and control groups failed to do so. In particular, the results showed that the target condition is more effective than the nontarget condition with respect to inducing L2 learners to improve their production accuracy.
The perception training did not entail any production training insofar as the tasks did not require the participants to produce the target pairs. Nonetheless, the first author and research assistants observed a particular behavior during the training on the part of the participants in the target and nontarget groups but not those in the other groups. That is, most participants in the target and nontarget groups verbally responded to the CF on their perception errors. They were eager to utter the target form after each CF intervention. Hardison (Reference Hardison2003) also revealed a similar finding: “I did note that learners in the AV (auditory-visual) training sessions imitated the lip movements of the talkers they were observing, although the training involved perception only, and their task was to circle the word from a minimal pair that they thought the talker on the screen was saying” (p. 516). Previous research on learner responses to CF revealed that, relative to other error types, CF on phonological errors led to the greatest amount of immediate learner uptake (Lyster, Reference Lyster1998; Sheen Reference Sheen2006), suggesting that this verbal behavior might be intrinsic to learner responses to CF on phonological errors.
Applying skill acquisition theory (DeKeyser, Reference DeKeyser, Doughty and Williams1998, Reference DeKeyser and Robinson2001; Lyster & Sato, Reference Lyster, Sato, García Mayo, Gutierrez-Mangado and Martínez Adrián2013) to L2 phonological development, declarative knowledge refers to phonological representations of the target pairs encoded in memory, whereas procedural knowledge refers to abilities to actually produce language by accessing the L2 phonological representations. Anderson, Corbett, Koedinger, and Pelletier (Reference Anderson, Corbett, Koedinger and Pelletier1995) argued that the proceduralization of declarative knowledge is accomplished through practice and feedback. In this view, findings from the Lee and Lyster (Reference Lee and Lyster2016b) study indicated that participants in the target and nontarget groups developed more targetlike phonological representations with the support provided by the perception training. In addition, in the present study, given that both types of CF ended up unintentionally inciting the participants to produce the target form, the target and nontarget conditions seem to have favored proceduralization. As a result, participants in the target and nontarget groups benefited from the perception training even in terms of production accuracy. In addition, the improvement in production was visible not only in the trained words but also to some extent, albeit somewhat less generalized, in the untrained words. This suggests that, within the target and nontarget groups, L2 learners’ phonological representations of these two target pairs became more targetlike.
The target condition was expected to enhance the target pattern and thus to induce the participants to notice and become aware of the phonetic differences between the target and nontarget forms. As for the nontarget condition, it was expected to encourage the participants to consider the alternative by providing them with negative evidence that included the nontarget form; therefore, they were also predisposed to notice and become aware of the phonetic differences between the target and nontarget forms. As a result, such opportunities for noticing and awareness in the receptive mode helped L2 learners to reanalyze and restructure their L2 phonological representations into more targetlike representations. Moreover, considering that both types of CF created opportunities to produce the target form, the target and nontarget conditions inadvertently provided opportunities for production practice, which may have contributed to the proceduralization of these reanalyzed phonological representations.
With respect to production opportunities, the target condition would appear more conducive than the nontarget condition, owing to the nature of the CF types. Specifically, given that the target condition entailed provision of the target form immediately following a perception error, those in the target group were predisposed to verbally utter the target form. As for the nontarget condition, it was designed to draw the L2 learners’ attention to the nontarget form so they would consider the alternative. Accordingly, it would seem less conducive for inciting participants to reproduce the form correctly, because the CF did not include the actual target form and instead pushed them to consider the alternative. In both cases, however, participants were observed uttering the target form, but these utterances were not expected and so were not quantified for further analysis.
Concerning the combination type, we found a mismatch between the perception and production outcomes. As reported in Lee and Lyster (Reference Lee and Lyster2016b), the combination group showed the highest perception accuracy after the perception training. However, as for the production measurement in the present study, those in the combination condition did not show any significant improvement. By juxtaposing the target form with the nontarget form, the combination type of CF was designed to optimize awareness of phonetic differences (i.e., the psychoacoustic salience), and so the participants in the combination condition had robust opportunities for noticing and awareness as a means to achieve more targetlike phonological representations in declarative knowledge. However, compared to the participants in the target and nontarget conditions, those in the combination condition seemed not to engage as frequently in the verbal behavior (i.e., uttering the target form) and may thus have had fewer opportunities for proceduralization. This is of course an open question worthy of further investigation. In a similar vein, further studies are needed to answer the question of why the combination condition was not as conducive to inciting the L2 participants to produce the target form.
Compared to the three auditory CF types, the wrong type did not provide any linguistic information other than a statement that an error had been made. As a result, the wrong type was ineffective in helping the L2 learners to improve their perception accuracy. In addition, those in the control group participated in the same perception training; however, they were not able to confirm whether their L2 phonological representations were acceptable in the target language owing to the absence of CF (Lee & Lyster, Reference Lee and Lyster2016b). Given that accurate speech production might derive from targetlike L2 phonological representations (Flege, Reference Flege and Strange1995; Flege et al., Reference Flege, Schirru and MacKay2003), it might be the case that those in the wrong and control groups were not able to improve their production accuracy due to the absence of targetlike L2 phonological representations.
Finally, the current study found that the effects of the training including CF seemed to have a lasting effect on one pair but not the other. Previous studies (e.g., Flege et al., Reference Flege, Bohn and Jang1997) showed that Korean learners of English have more difficulty with /ɛ/–/æ/ than with /i/–/ɪ/. Thus, we speculate that there might be more room for improvement in the former pair compared to the latter.
Impacts of improvement in perception accuracy on production accuracy
As for the trained words, improvement in perception accuracy was a significant predictor of production accuracy. That is, the extent to which production accuracy improved depended on L2 learners’ improvement in perception accuracy. This finding is compatible with previous empirical studies and the perception-first view in L2 phonological acquisition. In this view, the increased accuracy in L2 speech perception of the L2 participants in the present study served a bootstrapping function that enabled them to achieve more targetlike production. Nevertheless, considering that the regression analyses were significant for the trained words only, the impact of improvement in perception accuracy was not robust enough for us to draw a definitive conclusion, as was the case in other studies (e.g., Bradlow et al., Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997; Peperkamp & Bouchon, Reference Peperkamp, Bouchon and Trancoso2011), which also showed mixed results.
What draws our attention regarding the relationship between production and perception accuracy is that improvements in production and perception accuracy are not always parallel (Bradlow et al., Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997). In this sense, we argue that targetlike phonological representations might be necessary for targetlike production but do not necessarily guarantee targetlike production. That is, participants in the wrong and control conditions showed no improvement in perception accuracy (Lee & Lyster, Reference Lee and Lyster2016b) nor in production accuracy, owing arguably to the absence of targetlike L2 phonological representations. Participants in the combination condition improved their perception accuracy, and had thus encoded targetlike phonological representations, yet did not improve their production accuracy, owing again to the absence of opportunities for production practice and thus for proceduralization. Accordingly, for learners to achieve successful L2 speech production and perception, we recommend pedagogical interventions for L2 speech training that draw on skill acquisition theory by including opportunities for noticing, awareness, and practice, in addition to CF (Lyster, Reference Lyster2007; Ranta & Lyster, Reference Ranta, Lyster and DeKeyser2007).
Conclusion and future directions
Along with previous research, the current study found that the production accuracy of L2 learners benefits from L2 speech perception training without explicit production training. However, the extent of the benefits varies in accordance with CF type. In this respect, we argue that proper perception training be taken into consideration in L2 pronunciation instruction. We also recommend that CF treatments be carefully identified in L2 speech perception training and that their differential effects be accounted for in L2 speech acquisition.
In terms of production accuracy, the current study found that the target and nontarget types of CF were effective because they seemed to provide the L2 participants with opportunities to produce the target forms orally, which were in turn believed to expedite the proceduralization of L2 phonological representations. As for the combination type, the present study and the previous one by Lee and Lyster (Reference Lee and Lyster2016b) revealed a mismatch between perception and production accuracy outcomes. While the combination type of CF was effective in improving the L2 learners’ perception accuracy (Lee & Lyster, Reference Lee and Lyster2016b), this type of CF was not beneficial with respect to improving their production accuracy. On the one hand, we observed that the participants in the combination condition were less likely to produce target forms following CF, and we speculated that these were missed opportunities for proceduralization. On the other hand, we call for further studies to explore why they were less likely to do so.
During the perception training, the participants were allowed to listen to each stimulus repeatedly. Considering that excess input exposure might result in improvement in production accuracy regardless of CF type, it would be interesting to investigate whether similar results would obtain if the number of repetitions was controlled. In addition, the participants in the target and nontarget groups were eager to utter the target form after each CF intervention, whereas those in the other groups were not. Because we did not expect this phenomenon, we were not able to quantify the number of utterances per group. Accordingly, in order to solidify our argument regarding the roles of the CF types, we suggest that future studies be designed to quantify the number of utterances produced during L2 speech perception training with various CF types.
One might argue that L2 speech production training (e.g., explicit phonetic instruction) would result in similar findings and that speech production-perception mixed training would be ideal for both modalities. Comparison studies of the effects of L2 speech production-focused training, L2 speech perception-focused training, and L2 speech production-perception mixed training on both modalities would be thus of future interest. It would be also interesting to replicate the current study with different age groups, such as late versus early L2 learners (Saito, Reference Saito2015) and children versus adults (Baker et al., Reference Baker, Trofimovich, Flege, Mack and Halter2008); with different learning contexts, such as laboratory versus classroom settings; and with different proficiency levels. The impact of length of instruction and residence in target language countries would be worth investigating as well (Saito & Brajot, Reference Saito and Brajot2013; Saito & Hanzawa, Reference Saito and Hanzawa2015). Finally, given that the current study adopted two particular vowel pairs in monosyllabic words and a production measurement at a controlled-speech level, we call for research studies with more fine-grained research designs (e.g., various measurement tasks) and several linguistic targets with various word/sentence environments to have a clearer understanding regarding the roles of various CF types in L2 phonological development. In particular, it would be valuable to scrutinize the influence of speech perception training and CF on L2 speech production of linguistic targets when they are embedded in multisyllabic words, when the words are located in various positions in a carrier sentence, and when L2 learners are prompted to produce the words at a spontaneous-level speech.
Nevertheless, along with Lee and Lyster (Reference Lee and Lyster2016b), one finding is certain: the use of right or wrong as a primary means of providing CF in L2 speech perception training should be reconsidered.
ACKNOWLEDGMENTS
This research was supported by Social Sciences and Humanities Research Council of Canada Grant 410-2011-0671 (to R.L.). An earlier version of this article was presented at the 2016 annual meeting of the American Association for Applied Linguistics held in Orlando, Florida. We express our gratitude to all participants and research assistants Benjamin Gormley, Reginald Gooch, and Takashi Oba for helping us at various phases of this study. We also thank the anonymous reviewers and Associate Editor Isabelle Darcy for offering invaluable comments on earlier drafts.




