


There is considerable variability in adult second language acquisition (SLA; Birdsong, Reference Birdsong, Ritchie and Bhatia2009). The difficulties that adult learners encounter are varied, and include challenges in the phonological (Baker & Trofimovich, Reference Baker and Trofimovich2005; Sebastián-Gallés, Rodríguez-Fornells, de Diego-Balaguer, & Díaz, Reference Sebastián-Gallés, Rodríguez-Fornells, de Diego-Balaguer and Díaz2006), lexical (Bialystok, Reference Bialystok2008), morphological (Franceschina, Reference Franceschina2005), and syntactic (DeKeyser, Reference DeKeyser2005; Tokowicz & MacWhinney, Reference Tokowicz and MacWhinney2005) domains. Even highly proficient second language (L2) speakers often display differences compared to native speakers in the form of accented speech (phonological), vocabulary size (lexical), or preposition use (syntactic). The persistence of these differences has led to debate on the source of adults’ SLA difficulties and whether a critical or sensitive period exists for adult SLA (Birdsong, Reference Birdsong, Pawlak and Aronin2014; Friederici, Steinhauer, & Pfeifer, Reference Friederici, Steinhauer and Pfeifer2002; Johnson & Newport, Reference Johnson and Newport1989; Singleton, Reference Singleton2005). Theories of SLA must also expain why adults continue to learn native language vocabulary throughout life (Ramscar, Hendrix, Shaoul, Milin, & Baayen, Reference Ramscar, Hendrix, Shaoul, Milin and Baayen2014). In order to distinguish between first- and second-language learning as an adult, learning theories need to account for how the target language interacts with the learner's cognitive skills and specific language background.
Monolingual adults are more adept at learning native language content throughout life. People can shift their phonemic categories after sustained exposure to new dialects (Bigham, Reference Bigham2010; Evans & Iverson, Reference Evans and Iverson2007; Munro, Derwing, & Flege, Reference Munro, Derwing and Flege1999) and continue to learn new words with age (Ramscar et al., Reference Ramscar, Hendrix, Shaoul, Milin and Baayen2014; Verhaeghen, Reference Verhaeghen2003). Some of these new words will be neologisms, including such recent additions to the Merriam–Webster English dictionary as staycation or truthiness, while others constitute low-frequency words or jargon found in many hobbies and professional pursuits, such as morpheme or aphasia. Word learning aptitude is associated with several cognitive predictors, including short-term memory (Majerus, Poncelet, van der Linden, & Weekes, Reference Majerus, Poncelet, van der Linden and Weekes2008; Martin & Ellis, Reference Martin and Ellis2012) and attention/inhibition (Gass, Behney, & Uzum, Reference Gass, Behney, Uzum, Drozdzial-Szelest and Pawlak2013; Yoshida, Tran, Benitez, & Kuwabara, Reference Yoshida, Tran, Benitez and Kuwabara2011). In addition, the characteristics of the word itself can influence success at different stages of lexical acquisition. New words with irregular letter or sound patterns are often better at triggering initial stages of learning (Storkel, Armbrüster, & Hogan, Reference Storkel, Armbrüster and Hogan2006), because their novelty makes them more salient when embedded in a context of known words. In the study by Storkel et al., participants encountered new words in sentences, and a low-wordlike advantage was observed during the acquisition phase (before the word was fully learned), because the novelty of the low-wordlike items triggered learning better. However, novel items that resemble one's native language tend to be remembered more accurately after training (Frisch, Large, & Pisoni, Reference Frisch, Large and Pisoni2000; Luce & Large, Reference Luce and Large2001; Roodenrys & Hinton, Reference Roodenrys and Hinton2002; Thorn & Frankish, Reference Thorn and Frankish2005), because their forms are easier to integrate with prior language knowledge. This training advantage is evident from one of the first investigations of lexical similarity (Schwartz & Leonard, Reference Schwartz and Leonard1982), in which young children with limited vocabularies (<5 words) learned novel words consistent with their lexical inventory better after several sessions.
However, the types of linguistic patterns that promote first language (L1) growth may also interfere with L2 vocabulary learning. This is because languages are highly regular, but these regularities diverge across languages. For example, while less than half a percent of the 456,976 possible four-letter English words (264) are estimated to exist in speakers’ vocabularies (calculations based on CLEARPOND; Marian, Bartolotti, Chabal, & Shook, Reference Marian, Bartolotti, Chabal and Shook2012), the words that do exist share many similarities. These four-letter English words have an average of 10.33 neighbors (words that differ by only one letter), and while certain letters and bigrams (pairs of letters) appear frequently (e.g., CE or LY), others do not appear at all (e.g., ZW or FD). However, similarity drops when you compare across languages: written English words tend to have five to seven times fewer neighbors in related languages like Dutch, French, German, or Spanish than they do English neighbors (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012), highlighting the language-specific nature of lexical patterns.
Because of the significant differences across languages that make L2 word learning difficult, learners ought to capitalize on any similarities available. Teachers and students have long known to make use of similarities when acquiring an L2 (Ringbom, Reference Ringbom2007). Cognates, for example, are an effective learning tool. Cognates are words that overlap in form and meaning across languages, and they are easier to learn than noncognates (De Groot & Keijzer, Reference De Groot and Keijzer2000; Lotto & De Groot, Reference Lotto and De Groot1998). However, because the inventory of cognates is fairly limited, even between two related languages (Schepens, Dijkstra, Grootjen, & van Heuven, Reference Schepens, Dijkstra, Grootjen and van Heuven2013), they cannot make up the entirety of a learner's initial L2 vocabulary. In addition, learners’ conservative assumptions about cognates’ meanings may make cognates harder to use in context (Rogers, Webb, & Nakata, Reference Rogers, Webb and Nakata2014), limiting their utility to the language learner. Fortunately, there exists another large class of words that capitalizes on the learner's prior language knowledge, which are words whose spellings or sounds happen to adhere to native language patterns. For an English learner of German, words like sind or hinter (meaning are and behind) may be easier to learn than atypical words such as jetz (meaning now), because of the formers’ closer resemblance to existing English words. Studies using artificially designed auditory words have shown that phonological wordlikeness does improve novel word repetition and learning (Frisch et al., Reference Frisch, Large and Pisoni2000; Luce & Large, Reference Luce and Large2001; Roodenrys & Hinton, Reference Roodenrys and Hinton2002; Storkel et al., Hogan, Reference Storkel, Armbrüster and Hogan2006; Thorn & Frankish, Reference Thorn and Frankish2005), and one reason for this advantage may be that highly wordlike sequences, as they begin to degrade in memory, can be more accurately reconstructed.
Although most L2 exposure in immersion and instructional contexts is phonological at early stages, there has been an increase in text-based instruction, especially via web-based learning resources (Golonka, Bowles, Frank, Richardson, & Freynik, Reference Golonka, Bowles, Frank, Richardson and Freynik2012; Liu et al., Reference Liu, Evans, Horwitz, Lee, McCrory, Park, Lamy and Zourou2013). In addition, when considering the effect of cross-language similarity, orthographic overlap is often higher than phonological overlap in languages that share a script due to the conservation of symbols across languages (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012). These factors combined make the study of orthographic effects on L2 learning an important area of study.
The orthographic wordlikeness of a word in the L2 is its similarity to existing vocabulary and letter patterns in the L1. Here we define wordlikeness based on a combination of neighborhood size, positional segment frequency, and positional bigram frequency. Neighborhood size and segment/bigram frequencies provide two distinct, complementary metrics of typicality at lexical and sublexical levels of processing, respectively (Vitevitch & Luce, Reference Vitevitch and Luce1999). Neighborhood size was defined as the total number of words in the L1 that differed from the target in the substitution of a single letter (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012). Positional segment frequency was calculated for each letter in a target word as the total log frequency of all words that contain that letter in the same position, relative to the total log frequency of all words containing any letter at that position (Vitevitch & Luce, Reference Vitevitch and Luce2004); frequency estimates are thus token rather than type based, which better accounts for total exposure to a letter. The total positional segment frequency for a word was the sum across all letters in that word. Positional bigram frequency was calculated in a similar manner, based on the frequency of occurrence of each two-letter sequence. We use the abbreviated terms segment frequency and bigram frequency to refer to total positional segment frequency and total positional bigram frequency.
Wordlikeness is an especially useful aid early in learning, when little is known about the structure of the novel language itself. With increased experience, though, L2 learners are able to utilize L2-specific letter and sound patterns (Stamer & Vitevitch, Reference Stamer and Vitevitch2012) or morphological rules (Brooks, Kempe, & Donachie, Reference Brooks, Kempe and Donachie2011) to improve acquisition of L2-wordlike vocabulary. Participants in Stamer and Vitevitch's (Reference Stamer and Vitevitch2012) study had several years of college experience with an L2, but learners may detect basic L2 patterns even earlier. Results from statistical learning of nonsense syllables or tone sequences suggest that the mechanism to extract regularities in the input operates rapidly on novel stimuli (Mirman, Magnuson, Graf Estes, & Dixon, Reference Mirman, Magnuson, Graf Estes and Dixon2008; Newport & Aslin, Reference Newport and Aslin2004; Saffran, Johnson, Aslin, & Newport, Reference Saffran, Johnson, Aslin and Newport1999), and suggests that even early stages of L2 learning may be influenced by L2-specific patterns.
The current study investigates how novel words’ similarity to one's native language and to other novel words interacts to affect word learning in a L2. The present study assessed learning of carefully designed words in an artificial language that emulated an SLA context. Novel written words were paired with familiar picture referents (e.g., airplane or cat), and we tracked participants’ gains in performance over time on two measures of learning (word recognition and word production) within a single training session. Words were designed to have either high or low English wordlikeness based on their neighborhood size, segment frequency, and bigram frequency. We predicted an accuracy and response time advantage for wordlike items, which are easier to store and retrieve from memory due to their similarity to known lexical patterns in the native language. In addition, if learners intuitively identify letter and bigram patterns within the L2, we should observe characteristic errors in production caused by overgeneralization of L2 patterns.
A secondary goal of the study was to determine how the learner's individual differences in English vocabulary size, short-term memory capacity, and general intelligence affected learning of wordlike and unwordlike items. Because vocabulary learning involves acquisition and storage of novel letter/sound sequences, we expected high memory capacity to predict overall learning success (Majerus et al., Reference Majerus, Poncelet, van der Linden and Weekes2008; Martin & Ellis, Reference Martin and Ellis2012). While nonverbal IQ has been shown to predict learning of linguistic patterns such as grammatical rules (Kempe, Brooks, & Kharkhurin, Reference Kempe, Brooks and Kharkhurin2010), its role in vocabulary learning is less clear. Finally, we expected native language vocabulary size to predict learning for wordlike items that are consistent with patterns in the native language.
METHODS
Participants
Twenty English monolinguals (12 females) at a university in the United States participated for monetary compensation or course credit. Informed consent was obtained in accordance with the university's Institutional Review Board. The mean age was 20.3 years (SD = 1.42). After the experiment, participants completed a battery of cognitive tests to assess the effects of phonological short-term memory, vocabulary size, and nonverbal intelligence on word learning performance. Assessments and standard scores were as follows: phonological short-term memory, M = 112.6, SD = 12.3, Comprehensive Test of Phonological Processing, phonological memory composite score of digit span and nonword repetition subtests (Wagner, Torgesen, & Rashotte, Reference Wagner, Torgesen and Rashotte1999); English receptive vocabulary, M = 119.3, SD = 9.9, Peabody Picture Vocabulary Test—Third Edition (Dunn, Reference Dunn1997); nonverbal IQ, M = 113.2, SD = 6.6, Wechsler Abbreviated Scale of Intelligence, block design and matrix reasoning subtests (PsychCorp, 1999).
Materials
Forty-eight orthographic consonant–vowel–consonant–consonant words were created in the novel language Colbertian (named after comedy show wordsmith Stephen Colbert to engage participants in the learning task). Half of the words were designed to have high English wordlikeness (e.g., nish or baft). These were formed by substituting one letter of an English word, and had high orthographic neighborhood sizes, segment frequency, and bigram frequency. The other half of the words were unwordlike (e.g., gofp or kowm), and were formed by substituting multiple letters from English words; these words also had low segment frequency and bigram frequency. Letter and bigram distributions in the Colbertian language perceptibly differed from English; the most frequent letters at onset were G and V, while the most frequent bigrams at offset included FT, TZ, and WM. See Table 1 for orthotactic calculations from CLEARPOND (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012), and Appendix A for a list of all stimuli.
Table 1. Stimuli characteristics

Note: Orthographic wordlike and orthographic unwordlike subsets were designed to be matched on phonological wordlikeness metrics. Segment, bigram, phoneme, and biphone metrics are total positional frequencies. Values are means (standard deviations).
*p < .05. **p < .01. ***p < .001.
Although there was no auditory component to the learning task, readers often generate pronunciations for novel written words (Johnston, McKague, & Pratt, Reference Johnston, McKague and Pratt2004), and thus all Colbertian words were also assessed for English phonological wordlikeness. Six English monolinguals (not participants in the current study) pronounced each Colbertian word, and their responses were phonologically transcribed. Responses were 70% consistent across speakers, and more variable in the unwordlike (58.7%, SD = 28.4) than the wordlike (80.7%, SD = 19.6) conditions, t (46) = 2.89, p < .01. To account for variability in responses, phonological neighborhood size, total positional phoneme frequency, and total biphone frequencies were calculated for each speaker's production (using the same procedure as the orthographic calculations); these individual speaker values were averaged to yield mean scores for each word (using the CLEARPOND database; Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012). The orthographically wordlike and unwordlike lists differed (all ps < .05) on all phonological wordlikeness metrics, ensuring that any effects of orthography on learning were not obscured by differences in phonological characteristics. In addition, a phonologically matched subset of 12 wordlike and 12 unwordlike items was created in which the two lists differed in orthographic neighborhood size, total segment frequency, and total bigram frequency (all ps < .05), but did not differ in phonological neighborhood size, phoneme frequency, or biphone frequency (all ps >.1; Table 1).
Each novel word was paired with a color line drawing from the revised Snodgrass and Vanderwart picture set (Rossion & Pourtois, Reference Rossion and Pourtois2004). Pictures were chosen to be highly recognizable (naming reliability: M = 99.1%, SD = 2.0%; Bates et al., Reference Bates, D'Amico, Jacobsen, Székely, Andonova and Devescovi2003), and did not overlap orthographically or phonologically with their paired Colbertian words (all picture-word pairings available in Appendix A). Pictures for wordlike and unwordlike items did not differ on lexical frequency, orthographic or phonological neighborhood size, or mean segment, bigram, phoneme, or biphone frequencies (CLEARPOND; Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012).
Procedure
Participants began training with a single exposure block of 48 randomized trials to familiarize them with the novel language. In each exposure trial, a picture was presented in the center of the computer screen, and the written target word in Colbertian appeared below the picture. Trials advanced automatically after 2 s. Following the exposure block, participants performed five blocks of word recognition with feedback, and five blocks of word production with feedback, alternating between the two tasks. After each block, participants were given a short self-paced break (totaling on average 69.7 s, SD = 14.6, across the experiment). The entire learning and testing procedure lasted on average 55.1 min (SD = 12.5 min).
Word learning: Recognition
Each testing block included 48 recognition trials. In each trial, a randomly selected target picture and three distractors were displayed in the four corners of the screen, and the written target word appeared in the center of the screen. The distractors were other training items selected at random, with the constraint that each picture appeared once as a target and three times as a distractor within a single testing block. The participant was instructed to click on the correct picture, and accuracy and response time (RT) were recorded. After making a response, the three distractors disappeared, and the target picture and written word remained onscreen for 1000 ms. Because the word–picture pair remained visible during feedback, participants could use it to relearn the correct association.
Word learning: Production
In each testing block, the recognition task was followed by 48 production trials. In each trial, a randomly selected target picture was presented in the center of the screen; the participant was instructed to type the name of the picture in Colbertian, and the participant's response and RT were recorded. Errors in production were collected and analyzed separately. After making a response, the picture and the participant's answer remained on the screen, and the correct name of the target was printed below the participant's response for 1000 ms. By providing the correct answer as feedback, participants were able to improve their memory for the correct picture–word association. After completing all 48 trials, a new testing block of recognition and production began. After the fifth series of recognition and production blocks, the experiment concluded.
Data analysis
Accuracy and RT
RT analyses were performed on correct responses only in order to control for accuracy differences between blocks and conditions. Excessively long outlier RTs were identified within each combination of block and condition using a threshold of mean plus 2 SD (4.2% of all trials). Outliers were replaced with the threshold (M + 2 SD) for that combination in order to minimize noise from long trials. All analyses were repeated not omitting outliers and the same pattern of results was observed; for brevity, only results with adjusted outliers are reported.
Change across blocks in accuracy and RT in the recognition and production tasks was analyzed using growth curve analysis (Mirman, Dixon, & Magnuson, Reference Mirman, Dixon and Magnuson2008; Mirman, Magnuson, Graf Estes, & Dixon, Reference Mirman, Magnuson, Graf Estes and Dixon2008). Growth curve analysis is a form of multilevel regression that simultaneously estimates the effects of individuals and of experimental manipulations on timecourse data. Accuracy and RT data were first fit with second-order orthogonal polynomials to capture the curvilinear shape of learning gains over time. Each of the polynomial terms in these base models was then estimated in a Level 2 model that assessed the effects of wordlikeness and of participants on the parameter estimate from the base model. In these models, changes in the intercept term correspond to changes in the average height of the curve across the window of analysis (i.e., across all five testing blocks). The linear term reflects the overall slope of the curve, while the quadratic reflects its curvature. The base model included all time terms and random effects of participant and participant by condition on all time terms. Additional models were built that added a fixed effect of condition (wordlike and unwordlike items) to each time variable in turn. Significant improvements in model fit (chi-square test on the –2 log likelihood change in model fit) indicated an effect of condition on independent properties of the curve (i.e., height, slope, and curvature). To assess the effect on learning of individual differences in phonological memory, English vocabulary size, and nonverbal IQ, these individual difference predictors were added to the full model as fixed effects after recentering each predictor to zero. The change in model fit was assessed for each factor on the different time terms.
Error analysis
Production errors were analyzed to determine the influence of other languages on word recall. The distribution of incorrect single-letter substitutions can be used to isolate the effects of interference from Colbertian and English letter knowledge. Errors were analyzed at each letter position within the target word structure separately. Because all Colbertian letters were of the form consonant–vowel–consonant–consonant, and only five letters were valid in the vowel position, we restricted analyses to the three consonant positions (i.e. letter positions 1, 3, and 4). At each position, the relative frequencies with which each letter in the alphabet was used incorrectly across all items and participants was calculated in each block. As predictor variables, we calculated positional segment frequencies in the complete Colbertian vocabulary and for four-letter English words as in Vitevitch and Luce (Reference Vitevitch and Luce2004). Colbertian positional segment frequencies for each letter were calculated as the number of times that letter appeared in a Colbertian word at that position, divided by the total number of Colbertian words (because each word appeared the same number of times in the experiment, Colbertian words have equivalent token frequency, obviating the need for a log frequency transformation). English positional segment frequencies for each letter were calculated as the sum of SUBTLEX log frequencies for all four-letter words containing that letter in that position, divided by the sum of SUBTLEX log frequencies for all four-letter English words. Despite some notable differences across the two languages (e.g., the letters G and V are more common onsets in Colbertian than English), segment frequencies were distributed similarly, and no differences between the two languages were observed at any letter position (all ps > .1).
At each of the three letter positions, three linear models were constructed with letters’ error frequencies as the dependent value. The base model included a single predictor, time (i.e., testing block). The Colbertian model included both time and Colbertian positional segment frequencies as predictors, and the English model included both time and English positional segment frequency as predictors. To compare how well English and Colbertian segment frequencies predicted actual errors, three model comparisons were performed at each letter position (letters that were never produced or that had zero frequency in that position in English or Colbertian were excluded to enable model comparisons). The Colbertian model and the English model were each compared to the base model using likelihood ratio tests. Then the Colbertian model was compared to the English model using Vuong's nonnested model comparisons (Merkle, You, & Preacher, Reference Merkle, You and Preacher2015; Vuong, Reference Vuong1989).
RESULTS
Novel word recognition
Recognition accuracy improved over time and reached an asymptote at ceiling performance, improving from 64.4% (SD = 13.1) in the first block to 97.7% (SD = 4.8) in the fifth block. The base model was fit with a second-order polynomial: linear term, change in log likelihood (∆LL) = 8.48, χ2 (1) = 16.96, p < .0001; quadratic term, ∆LL = 15.17, χ2 (1) = 30.35, p < .0001. RTs became faster over time, from 2921 ms (SD = 446) in the first block to 2102 ms (SD = 539) in the fifth block. The base RT model was fit with a second-order polynomial: linear term, ∆LL = 14.50, χ2 (1) = 27.00, p < .0001; quadratic term, ∆LL = 0.53, χ2 (1) = 1.06, p > .1.
Wordlikeness affected the shape of the learning curve for accuracy. Wordlike items rose in accuracy more steeply initially between blocks, and reached an asymptote at mastery performance earlier than unwordlike items, but there was no difference in the amount learned across the experiment. In model comparisons, there was a marginal effect of wordlikeness on the intercept, ∆LL = 1.58, χ2 (1, 17) = 3.16, p = .075, no effect on the linear term, ∆LL = 0.01, χ2 (1) = 0.02, p > .1, and a significant effect on the quadratic term, ∆LL = 2.33, χ2 (1) = 4.67, p < .05. Observed data and the fitted models for wordlike and unwordlike conditions are shown in Figure 1.

Figure 1. Novel word recognition accuracy. Dots mark observed data, and lines are best fit quadratic growth curve models. Wordlike items (solid) had significantly steeper curvature (effect of wordlikeness on the quadratic term); English vocabulary size positively affected learning rate (linear term).
Wordlikeness also increased overall speed of recognition, as pictures corresponding to wordlike items were identified faster than those corresponding to unwordlike items: intercept, ∆LL = 6.41, χ2 (1) = 12.81, p < .001. The rate at which RT improved between blocks, and the shape of the RT curve over time, however, were not affected by items’ wordlikeness: linear, ∆LL = 0.63, χ2 (1) = 1.28, p > .1; quadratic, ∆LL = 0.98, χ2 (1) = 1.96, p > .1. Observed data and the fitted models are shown in Figure 2.
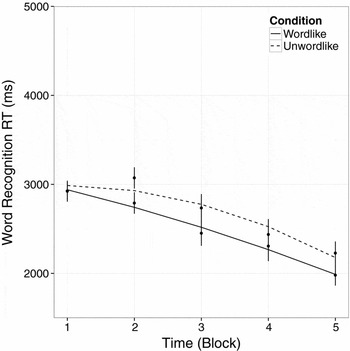
Figure 2. Novel word recognition response time for correct trials. Dots mark observed data, and lines are best fit quadratic growth curve models. Wordlike items (solid) were recognized faster (effect of wordlikeness on intercept), and higher memory capacity was associated with faster response times.
Novel word production
Production accuracy improved from 10.2% (SD = 8.9) in the first block to 73.2% (SD = 22.3) in the fifth block. The base model was fit with a second-order polynomial, and though overall accuracy increased between blocks: linear term, ∆LL = 23.37, χ2 (1) = 46.74, p < .0001, the increase was largest in earlier blocks: quadratic term, ∆LL = 3.89, χ2 (1) = 7.78, p < .01. RTs on correct trials became faster over time, improving from 3566 ms (SD = 1335) in the first block to 2907 ms (SD = 789) in the fifth block. RT was also fit with a second-order polynomial, and RT decreased between blocks: linear term, ∆LL = 2.64, χ2 (1) = 5.27, p < .05, with the largest decrease in earlier blocks: quadratic term, ∆LL = 2.48, χ2 (1) = 4.97, p < .05.
Wordlike items were produced more accurately throughout the experiment than unwordlike items, but the rate of improvement for the two types of words was comparable. Adding wordlikeness to the intercept significantly improved model fit, ∆LL = 17.88, χ2 (1) = 35.77, p < .0001, but it had no effect on the linear, ∆LL = 0.96, χ2 (1) = 1.91, p > .1, or quadratic terms, ∆LL = 1.07, χ2 (1) = 2.16, p > .1. Observed data and the fitted models are shown in Figure 3. Wordlikeness improved accuracy by 16.9%, a difference of roughly four words. The lack of an effect on either the linear or quadratic term indicates that accuracy for both types of words improved at a similar rate over time, and the relative difference between the two conditions remained the same.

Figure 3. Novel word production accuracy. Dots mark observed data, and lines are best fit quadratic growth curve models. Wordlike items (solid) were produced more accurately (effect of wordlikeness on intercept); wordlike accuracy was positively associated with English vocabulary size. Larger memory capacity was associated with faster learning rate for both item types (effect on linear term).
Similar to the recognition task, RTs were faster overall for wordlike items compared to unwordlike items, but both item types decreased at similar rates. Adding wordlikeness to the intercept significantly improved model fit, ∆LL = 9.87, χ2 (1) = 19.74, p < .0001, but it had no effect on the linear, ∆LL = 0.01, χ2 (1) = 0.01, p > .1, or quadratic terms, ∆LL = 0.03, χ2 (1) = 0.06, p > .1. Observed data and the fitted models are shown in Figure 4. Correct wordlike items were overall 480 ms faster than correct unwordlike items in the model, indicating that wordlike items were easier to produce.

Figure 4. Novel word production response time for correct trials. Dots mark observed data, and lines are best fit quadratic growth curve models. Wordlike items (solid) were recognized faster (effect of wordlikeness on intercept), and higher memory capacity was associated with faster response times.
Relationship between recognition and production
To determine whether word recognition and production performance were affected by a common set of lexical representations in the novel language, correlations between accuracy and RT in the two tasks were conducted. For accuracy, recognition and production were strongly correlated in each testing block, Block 1: r (18) = .65, p < .01; Block 2: r (18) = .79, p < .001; Block 3: r (18) = .77, p < .001; Block 4: r (18) = .76, p < .001; and Block 5: r (18) = .71, p < .001, suggesting that participants accessed common representations in the two tasks. RTs were not correlated in the first four testing blocks, Block 1: r (18) = .31, p > .1; Block 2: r (18) = .37, p > .1; Block 3: r (18) = .26, p > .1; and Block 4: r (18) = .09, p > .1, but in the final testing block, there was a moderate correlation between the two tasks, r (18) = .47, p < .05. The lack of correlation until participants became most fluent in the novel language reflects the large difference in response type between the two tasks (point and click for recognition versus typing a word in production).
Phonological control
To control for the effect of phonological wordlikeness on performance, analyses were run on a subset of wordlike and unwordlike trials closely matched for phonological similarity. For word production accuracy, adding orthographic wordlikeness to the intercept significantly improved model fit, ∆LL = 7.16, χ2 (1) = 14.31, p < .0001, but it had no effect on the linear, ∆LL = 0.64, χ2 (1) = 1.27, p > .1, or quadratic, ∆LL = 0.22, χ2 (1) = 0.45, p > .1, terms. The overall curve height was increased by wordlikeness (estimate = 9.6, SE = 2.1, p < .001), though the size of this increase is lower than that observed in the full analysis. For word production RTs, adding orthographic wordlikeness to the intercept significantly improved model fit, ∆LL = 2.02, χ2 (1) = 4.04, p < .05, but it did not affect the linear, ∆LL = .01, χ2 (1) = 0.01, p > .1, or quadratic, ∆LL = 0.11, χ2 (1) = 0.22, p > .1, terms. Wordlikeness reduced the overall curve height (estimate = –224.8, SE = 112.6, p < .05), to a lesser degree than in the full analysis.
For word recognition, orthographic wordlikeness did not improve model fit for recognition accuracy, intercept model: ∆LL = 0.36, χ2 (1) = 0.73, p > .1; linear model: ∆LL = 0.44, χ2 (1) = 0.89, p > .1; quadratic model ∆LL = 0.19, χ2 (1) = 0.37, p > .1, or recognition RT: intercept model: ∆LL = 0.21, χ2 (1) = 0.41, p > .1; linear model: ∆LL = 1.23, χ2 (1) = 2.47, p > .1; quadratic model ∆LL = 0.30, χ2 (1) = 0.61, p > .1. The effect of wordlikeness on performance in the recognition task was small in the overall analysis, and the subset analysis shows that orthographic similarity alone did not yield a detectable effect.
Bigram legality
Because the unwordlike item set varied in whether they contained any bigrams that were illegal in English (e.g., the bigram FP in gofp), we conducted a secondary analysis comparing wordlike (N = 24), legal-unwordlike (N = 9), and illegal-unwordlike (N = 15) items. In all analyses, the legal-unwordlike condition was used as the reference level. For accuracy on the production task, adding condition to the intercept significantly improved model fit, ∆LL = 22.07, χ2 (2) = 44.14, p < .001. Illegal items were learned less overall than legal-unwordlike items (intercept estimate = –7.0, SD = 2.3, p < .01), and wordlike items were learned better overall (intercept estimate = 12.6, SD = 2.3, p < .001). For RT on the production task, adding condition to the intercept significantly improved model fit, ∆LL = 11.94, χ2 (2) = 23.88, p < .001. Illegal items were produced slower overall than legal-unwordlike items (estimate = 541, SD = 140, p < .001), but there was no difference between legal and wordlike items (estimate = –160, SD = 122, p > .1). This pattern of results suggests that items containing novel bigrams were especially difficult to recall and produce. Low similarity while not violating English orthotactic rules (i.e., the legal-unwordlike condition) still led to a large drop in accuracy compared to high English similarity, but did not affect speed.
For recognition accuracy, there were marginal effects of condition on the intercept, ∆LL = 2.6, χ2 (2) = 5.19, p < .1, and quadratic terms, ∆LL = 2.5, χ2 (2) = 5.01, p < .1, and a significant effect of condition on the linear term, ∆LL = 5.5, χ2 (2) = 10.90, p < .01. The illegal items were learned less overall (estimate = –2.9, SD = 1.3, p < .05) and had a shallower slope (estimate = 8.8, SD = 2.6, p < .001) than the legal-unwordlike condition. In contrast, the wordlike items were learned faster (estimate = 8.4, SD = 2.6, p < .01) and reached ceiling performance earlier (quadratic term: estimate = –6.2, SD = 2.8, p < .05). This pattern of results was caused by higher initial accuracy for the legal- unwordlike condition compared to wordlike items, followed by shallower learning gains (thus the lack of an intercept effect). For recognition RTs, there were significant effects of adding condition to the intercept, ∆LL = 10.74, χ2 (2) = 21.48, p < .001, and linear terms, ∆LL = 5.34, χ2 (2) = 10.67, p < .01. Illegal items were slower overall than the legal-unwordlike condition (estimate = 249, SD = 540, p < .001). The legal-unwordlike items had a shallower slope than both the illegal items (estimate = –325, SD = 108, p < .01) and the wordlike items (estimate = –300, SD = 108, p < .01). This pattern of results was caused by the legal-unwordlike items being responded to faster in the initial testing block, followed by smaller speed increases between blocks compared to the other two conditions.
Error analysis
Error production by block and letter position was analyzed with a 5 (block) × 4 (letter position) within-subjects analysis of variance; mean errors for each combination are provided in Table 2. Errors decreased over time: main effect of block, F (4, 76) = 105.6, p < .001, with each block containing fewer errors than the preceding block (all ps < .05, Holm correction). In addition, errors were unevenly distributed across letter positions in a word: main effect of letter-position, F (3, 57) = 27.69, p < .001. All letter positions were significantly different from each other (all ps < .05, Holm correction), with error percentage increasing from the vowel, to the first consonant, the second consonant, and the final consonant in order. The low vowel error rate reflects the smaller inventory of only five letters at that position, compared to 14–15 possible consonants at the other positions. In addition, an interaction of block and position, F (12, 228) = 2.98, p < .001, captured a change in consonant error from uniformly high in block one (all comparisons p > .1) to more nuanced with increased training, including a sharp decrease in first-consonant errors.
Table 2. Percentage errors by letter-position and block
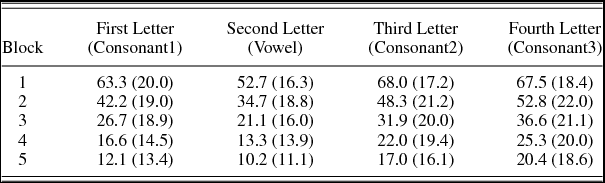
Note: Values are participant means (standard deviations).
To examine participants’ ability to extract Colbertian regularities, the effects of Colbertian and English letter frequencies on the distribution of incorrect single-letter substitutions was examined. At each of the three consonant positions within a word, three linear models were created with the frequency of errors for individual letters as the dependent variable, a base linear model containing only time (testing block) as a predictor, and two language models that included either Colbertian segment frequencies or English segment frequencies as an additional predictor.
In the first consonant position, both Colbertian segment frequency and English segment frequency significantly improved fit compared to the base model (Colbertian model: likelihood ratio [LR] = 28.95, p < .001; English model: LR = 11.48, p < .001). However, the Colbertian model was a significantly better fit to the data than the English model (Vuong's nonnested model comparison z = 1.65, p < .05). In the second consonant position, only Colbertian segment frequency improved model fit (Colbertian model: LR = 42.78, p < .001; English model: LR = 17.93, p > .1). Accordingly, the Colbertian model provided significantly better fit than the English model (z = 2.24, p < .05). In the final consonant position, both Colbertian and English segment frequencies improved model fit (Colbertian model: LR = 34.33, p < .01; English model: LR = 22.06, p < .05); however, in this position there was no difference in model fit between the two languages (z = 1.23, p > .1).
Whereas the frequency with which letters appeared in the Colbertian vocabulary predicted the types of errors participants made at all consonant positions in a word, English frequency was only related to errors at word onset and offset. In addition, Colbertian was a better predictor of errors than English for two letter positions, and as good a predictor as English for the remaining position. These results indicate that even when participants were unable to completely retrieve a target item, they filled in gaps in their recollection based on their knowledge of sublexical letter patterns, especially those patterns present in Colbertian. This specific sensitivity to letter frequencies in Colbertian suggests that as participants attempted to learn whole words, they were also able to identify regularities in the input and used this language-general knowledge to supplement their memory for individual words.
Individual differences
The effects of English vocabulary size, phonological memory capacity, and nonverbal intelligence on accuracy and RT was explored in both the recognition and production tasks. For accuracy on the recognition task, adding English vocabulary size to the model had a significant effect on the linear term, ∆LL = 3.29, χ2 (1, 12) = 6.58, p < .05, suggesting that a large native language vocabulary can improve the rate of learning novel words’ meanings. This effect on the linear term was present for both wordlike, ∆LL = 2.75, χ2 (1, 12) = 5.50, p < .05, and unwordlike, ∆LL = 2.18, χ2 (1, 12) = 4.35, p < .05, items analyzed separately, indicating that the effect of vocabulary size was not dependent on novel words’ orthographic structure.
Adding phonological memory capacity to the model for RT in the recognition task significantly improved estimation of the intercept, ∆LL = 4.30, χ2 (1, 11) = 8.60, p < .05, indicating that individuals with larger memory capacity identified correct word–picture associations faster than individuals with lower memory capacity throughout training. The absence of an effect of memory on the linear or quadratic terms indicates that the improvements in RT that were observed over training did not depend on memory capacity. In addition, the effect of memory on the intercept was observed for both wordlike, ∆LL = 2.42, χ2 (1, 11) = 4.83, p < .05, and unwordlike, ∆LL = 4.56, χ2 (1, 11) = 9.13, p < .01, items analyzed separately; larger memory capacity improved RTs for both types of words. Nonverbal IQ had no effect on accuracy or RT in the recognition task.
For accuracy on the production task, adding phonological memory to the model had a significant effect on the linear term, ∆LL = 4.95, χ2 (1, 12) = 10.07, p < .01, indicating that higher memory capacity improved word learning rate. This effect of memory was found for both wordlike, ∆LL= 6.05, χ2 (1, 12) = 12.09, p < .001, and unwordlike, ∆LL = 1.90, χ2 (1, 12) = 3.81, p = .05, items analyzed separately, suggesting that the effect of memory was not affected by the words’ similarity to existing lexical forms. English vocabulary size, however, had a significant effect on the intercept term, ∆LL = 2.96, χ2 (1, 11) = 5.91, p < .05, suggesting that a large English vocabulary increased the number of words a participant was able to learn. However, this effect was observed only for wordlike items, ∆LL = 2.40, χ2 (1, 11) = 4.79, p < .05, and did not hold for the unwordlike items analyzed separately, ∆LL = 1.59, χ2 (1, 11) = 3.18, p > .1, indicating that larger English vocabulary size conferred a specific advantage to learning the novel words that resembled English.
Reaction times in the production task were affected by phonological memory in a similar manner to the recognition task; adding phonological memory to the intercept term significantly improved model fit, ∆LL = 20.9, χ2 (1, 11) = 40.23, p < .0001, an effect observed for both wordlike, 17.148, χ2 (1, 11) = 34.30, p < .0001, and unwordlike, ∆LL = 9.34, χ2 (1, 11) = 18.70, p < .0001, items. These results suggest that learners with larger memory capacity more quickly retrieved novel words’ forms, but training improved RTs for all learners at a similar rate. Nonverbal IQ had no effect on accuracy or RT in the production task.
DISCUSSION
The current study investigated how orthographic typicality in the L1 and L2 affects the rate and amount of learning of written L2 words, and explored the relative contributions of memory, vocabulary, and nonverbal intelligence to vocabulary learning. As expected, accuracy and RT improved with training, both for recognizing novel words’ matching pictures and for producing the novel words when cued with the meaning. Of critical importance, we found that high similarity to existing English words (based on both high neighborhood density and high segment/phoneme and bigram/biphone frequencies) improved learning of both novel words’ forms and their meanings. After controlling for phonological similarity, orthographic wordlikeness significantly improved word production, but was not sufficient to affect word recognition alone. Learners also successfully extracted and utilized regularities in the novel language, leading to a characteristic pattern of overgeneralization errors. In addition, higher phonological memory capacity was associated with better form and meaning learning regardless of English similarity. High vocabulary size also provided a general benefit to meaning acquisition (picture–word correspondences), but for word form acquisition, it selectively improved items with high similarity to English. Results of the current study support the view that word similarity can assist L2 vocabulary learning by scaffolding on overlapping structures in the native language.
After 1 hr of study involving repeated retrieval attempts with feedback, learners were able to produce about 35 of the 48 words (73%) correctly, given only a picture as a cue to the novel word's meaning. These results highlight the effectiveness of repeated testing as an instructional tool (Roediger & Karpicke, Reference Roediger and Karpicke2006) given the rapid gains in performance. The persistence of these single-session learning benefits, however, depends on successful transition from their representation in initial episodic memory traces to stable lexical representations, as described in the complementary systems account of word learning (Davis & Gaskell, Reference Davis and Gaskell2009; Dumay & Gaskell, Reference Dumay and Gaskell2007).
Within this period of initial learning, we have shown that form similarity in the absence of meaning overlap can accelerate learning. Words that overlap in both form and meaning across languages (i.e., cognates) are valuable teaching tools and are easier to learn than noncognates (De Groot & Keijzer, Reference De Groot and Keijzer2000; Lotto & De Groot, Reference Lotto and De Groot1998; Rogers et al., Reference Rogers, Webb and Nakata2014). In the current study, participants mastered the picture–word associations for wordlike items faster than unwordlike items, and successfully produced more wordlike items over the course of training. In addition, RTs for both word recognition and production were faster overall for wordlike than for unwordlike items. These results corroborate existing studies of vocabulary acquisition using nonwords in the auditory domain showing that phonological neighborhood size and phonotactic probability influence learning outcomes (Frisch et al., Reference Frisch, Large and Pisoni2000; Luce & Large, Reference Luce and Large2001; Roodenrys & Hinton, Reference Roodenrys and Hinton2002; Storkel et al., Reference Storkel, Armbrüster and Hogan2006; Thorn & Frankish, Reference Thorn and Frankish2005).
Orthographic similarity, as manipulated in the current study, can affect phonological processing through lexical and sublexical structures (Ziegler, Muneax, & Grainger, Reference Ziegler, Muneaux and Grainger2003), making orthography an important component for understanding vocabulary learning. Because of the close link between orthography and phonology, we conducted a secondary analysis on a subset of items matched for phonological wordlikeness (phonological neighborhood size, phoneme frequency, and biphone frequency) in order to isolate the effect of orthographic similarity alone. In the production task, orthographic wordlikeness increased accuracy and decreased RT (although to a lesser extent than the full analysis), but no effect of orthographic wordlikeness alone was observed for word recognition. These results suggest the contribution of both a general wordlike effect on recognition and production as well as independent effects of orthography and phonology on word production. The additive effects of orthographic and phonological wordlikeness may occur through a dual coding advantage due to participants generating phonological forms of the novel written words. The contribution of phonological knowledge is particularly likely given the observation that participants’ phonological memory performance affected learning performance for both word recognition and production. To precisely account for orthographic and phonological effects during learning would require assessing acquisition of novel words fully crossed for orthographic and phonological wordlikeness.
The effects of wordlikeness on different components of novel word learning were identified in the recognition and production tasks. The recognition task probed participants’ ability to forge a link between a novel word and an existing semantic concept, whereas the production task assessed memory for the novel written form itself. To emulate an SLA context, the novel written words were paired with pictures of familiar objects (e.g., airplane or cat). In the recognition task, the participants’ goal was to identify the matching picture from four alternatives when presented with one of the novel words, which served to minimize memory demands for word forms and isolate knowledge of the word–meaning link itself. Accuracy for wordlike items was slightly lower than for unwordlike items in the first testing block, but wordlike accuracy increased at a faster rate. This pattern was only observed for the novel items that had low similarity, yet still contained entirely legal English bigrams; words that contained illegal bigrams (e.g., the FP in gofp) were learned worse overall. This pattern conforms to models of word learning, whereby unwordlike items trigger learning better, because their novelty is more salient than wordlike items (Gupta & MacWhinney, Reference Gupta and MacWhinney1997; Storkel et al., Reference Storkel, Armbrüster and Hogan2006). Wordlike items are advantaged with additional training, because they are easier to associate with existing vocabulary. In postexperiment debriefings, participants commonly reported that they learned the novel words by creating visual associations (e.g., “The chained dog moaned and howled” to remember that the novel word mowl means chain), similar to the successful keyword learning method (Shapiro & Waters, Reference Shapiro and Waters2005). It is possible that participants found it easier to generate useful, robust associations for wordlike items, accelerating learning of these words’ meanings. Providing learners with sample keyword associations could be more beneficial for unwordlike items, for which strong associations are more difficult to self-generate due to their further distance from existing vocabulary. Whether or not this effect of wordlikeness generalizes to word classes beyond the highly imageable nouns used in the current study is yet to be determined. Keyword method learning techniques are generally less successful when used with low imageability concepts, like liberty (Shapiro & Waters, Reference Shapiro and Waters2005), and it is possible that wordlikeness affects learning differently for words relating to abstract concepts. While keyword learning is an effective tool for the initial stages of vocabulary learning, full lexical consolidation requires abstraction of a word's form and meaning from specific episodic memories (Davis & Gaskell, Reference Davis and Gaskell2009), at which point the role of the keyword in recall will be diminished.
In contrast to the recognition task's assessment of semantic learning, the production task directly assessed memory for the novel written word forms. Although production and recognition accuracy were highly correlated, production accuracy lagged substantially behind recognition accuracy. Even when participants had acquired word–meaning links, they continued to experience difficulty retrieving the exact form. Production was much more sensitive to the effect of wordlikeness than recognition, with an effect equivalent to roughly a four-word difference between conditions. This large effect of wordlikeness supports the idea that as newly learned words begin to decay in short-term memory, they can be reconstructed based on a combination of lexical similarity to known words (i.e., neighbors) or sublexical sequence typicality (i.e., segment and bigram frequencies).
While similarity to English had a notable effect on accuracy, there were also indications that letter frequencies within the novel language itself influenced word production. There is a strong bias for spontaneous errors during speech production to adhere to learned phonotactic rules, and the types of errors one produces is susceptible to short-term training (Dell, Reed, Adams, & Meyer, Reference Dell, Reed, Adams and Meyer2000). In the current study, the novel language's orthotactic structure diverged in several ways from English, with certain letters occurring more or less frequently at different positions within a word. In correct responses, it is not possible to separate correct retrievals of an individual word versus successful gap-filling utilizing letter patterns. However, overgeneralization of these patterns within the novel language leads to a characteristic pattern of errors. Positional segment frequency in the novel language was a better predictor than English positional segment frequency for the types of single-letter errors that participants made in their responses, indicating that learners had already begun to extract statistical regularities in the vocabulary of the novel language, and used this general language knowledge to supplement their memory for individual words.
Successful use of a L2 not only requires a large vocabulary but also depends on fluency. Fluency is especially important for L2 communication in time-sensitive contexts, and slow responses impede L2 utility in interpersonal and vocational settings. Participants in the current study correctly produced wordlike items 10%–15% faster than unwordlike items throughout training, equivalent to roughly half a second. Response fluency is a skill that can be effectively trained in instructional settings (Snellings & van Gelderen, Reference Snellings and van Gelderen2002; van Gelderen, Oostdam, & van Schooten, Reference van Gelderen, Oostdam and van Schooten2011), and these results suggest that unwordlike items may be more effective targets for fluency training during L2 instruction, as RTs continue to lag behind wordlike items. However, overall RTs were relatively slow compared to the rate needed for fully fluent speech. The nature of the task, involving focused, effortful recall with no time penalty, may not directly translate to advantages in natural speech production.
While the characteristics of the novel words (i.e., neighborhood size and segment/bigram frequencies) had clear and dramatic effects on learning, there were also effects of the learners’ cognitive and linguistic backgrounds. Larger phonological memory capacity improved recognition and production RT for both types of words and the rate of learning for the novel word forms. Larger English vocabulary size improved recognition learning rate and interacted with wordlikeness on word production. Nonverbal intelligence, however, was not associated with any individual differences in learning accuracy or RT.
Phonological memory capacity was assessed using the digit span and nonword repetition subtests of the Comprehensive Test of Phonological Processing, which score accuracy for oral repetition of auditorily presented number or nonword sequences. Higher scores indicate increased short-term memory for an ordered list, and participants with high memory capacity may have been able to maintain the novel words’ picture associations and written forms in working memory long enough to encode a robust, easily retrieved memory.
In terms of accuracy, English vocabulary size was associated with learning rate for picture–word associations in the recognition task. As discussed earlier, a commonly reported learning strategy in this task was to build an arbitrary mental association linking the novel word and the picture. Learners with larger vocabularies may have been able to generate more distinctive associations, because they had more words of lower frequency available to form links. Alternatively, because a large vocabulary is evidence of robust word learning skills in the L1, unmeasured predictors of learning skills such as motivation, attention, or inhibition could have affected both English vocabulary size and novel word recognition performance. In addition, individual differences in vocabulary size may change the relative frequencies of different letter sequences. Individuals’ vocabularies vary widely at lower frequencies (Keuleers, Stevens, Mandera, & Brysbaert, Reference Keuleers, Stevens, Mandera and Brysbaert2015), and the effects of these unique differences on language learning is a promising area of future research.
Memory for word forms on the production task was improved by both phonological memory capacity and English vocabulary size, although the two had distinct effects. Larger phonological memory capacity resulted in a faster learning rate for both sets of words, but did not affect the overall number of words learned. Each production test was separated by an intervening word recognition task, and thus learned word forms had to be stored for several minutes before being tested again (average time between the end of one production test and the start of the next was 4.22 min, SD = 0.73). Higher phonological memory capacity predictably resulted in larger gains from block to block, by increasing the amount of new information learned each time. Although there was no auditory component to the task used in the current study, people typically automatically generate phonological forms for written words (Johnston et al., Reference Johnston, McKague and Pratt2004). These self-generated phonological forms provide a mechanism for the observed influence of phonological memory capacity on written word learning. When English phonological similarity was controlled for, the effect of wordlikeness on learning was reduced, suggesting that phonological forms played an important role during learning.
In contrast, larger vocabulary size improved the total number of words learned instead of the rate, but only for the wordlike item set. This effect of vocabulary on wordlike items reinforces the idea that partially remembered items may be reconstructed based on existing language knowledge, and that this strategy is more effective for items with higher similarity to the learner's native language. Note that while vocabulary size improved wordlike learning, it did not negatively impact unwordlike learning. That is, the benefit for wordlike items did not come at the expense of memory for unwordlike items. When novel words differ from existing language patterns, they can still be learned through other available mechanisms.
The final individual difference assessed in the current study, nonverbal intelligence, failed to predict changes in accuracy or RT in either task. IQ has previously been shown to affect aspects of SLA that require decision making or pattern recognition, such as listening comprehension (Andringa, Olsthoorn, van Beuningen, Schoonen, & Hulstijn, Reference Andringa, Olsthoorn, van Beuningen, Schoonen and Hulstijn2012) or grammar learning (Kempe et al., Reference Kempe, Brooks and Kharkhurin2010; Kempe & Brooks, Reference Kempe and Brooks2011). In contrast, the current study's vocabulary learning task relies heavily on memory and prior vocabulary knowledge, but does not tap into the skills that contribute to nonverbal IQ.
In conclusion, our results show that acquisition of novel written words is affected by their lexical characteristics, as well as by the cognitive and linguistic profile of the learner. Wordlikeness, which involved a manipulation of orthographic neighborhood size, segment frequency, and bigram frequency, had a pronounced effect on both the formation of word–meaning links and the acquisition of novel word forms. In addition, regularities within the novel language were accessible to learners and influenced their responses, as evident in overgeneralization patterns leading to response errors. Both phonological memory capacity and native-language vocabulary size predicted learning, but while vocabulary effects were more extensive for items with wordlike forms, memory capacity benefited learning for words of all types. Vocabulary learning is an especially important part of SLA, because it provides a salient benchmark to the learner of their progress, helping to increase confidence and motivation. The vocabulary hurdle is highest at the onset of learning, and improving performance at this stage is vital to afford the learner a framework on which to build further easy and difficult words alike. These results suggest that learners may accelerate vocabulary acquisition at early stages by capitalizing on words that resemble their native language, allowing them to rapidly build their L2 framework.
APPENDIX A
Table A.1. Stimuli list
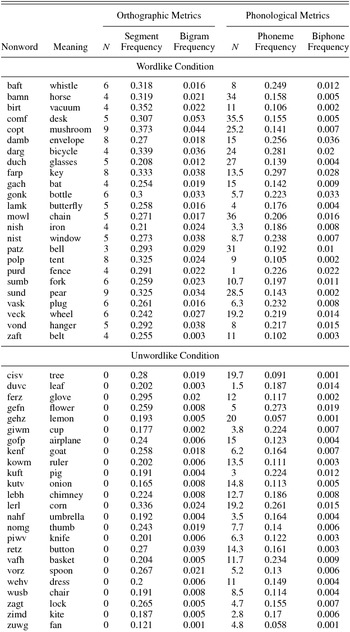
Table A.2. Errors at the first letter position (first consonant)

Table A.3. Errors in the second letter position (vowel)

Table A.4. Errors in the third letter position (second consonant)
Table A.5. Errors in the fourth letter position (third consonant)

ACKNOWLEGMENTS
This research was supported in part by NICHD Grants R01 HD059858, NIH R01 DC008333, and T32 NS 47987–8. The authors thank Sana Ali for help testing participants and the members of the Northwestern University Bilingualism and Psycholinguistics Research Group for comments on this work.











