Introduction
Linguistic transfer in the bilingual context has traditionally focused on transfer from a bilingual's L1 to the L2. More recent developments have shown that cross-linguistic influences may work both ways, from L1 to L2 as well as from L2 to L1. This phenomenon coined bidirectional transfer (Sharwood Smith, Reference Sharwood Smith, Kellerman and Sharwood Smith1986) may be simultaneous or synchronic (Pavlenko & Jarvis, Reference Pavlenko and Jarvis2002) and when synchronic it may occur for bilinguals whose L2 is or is not the discourse community language (Brown & Gullberg, Reference Brown and Gullberg2008). In this study we explore backward linguistic transfer in late bilinguals from L2 English to L1 Finnish of Finnish natives living in Finland. Specifically, we examine the influence that spelling conventions of English compounding have on processing behavior and spelling choices in the typologically and genetically unrelated Finnish language.
In general, the literature on backward transfer shows that extensive exposure to L2 makes the L1 vulnerable for intrusion of lexical and syntactic structures of the L2 and may even lead to attrition. Most studies report instances of backward transfer on syntactic, lexical or metalinguistic levels. For instance, Liu, Bates, and Li (Reference Liu, Bates and Li1992) have found that early, proficient Chinese–English bilinguals use L2 grammatical assignment strategies during L1 processing. Similarly, Dussias and Sagarra (Reference Dussias and Sagarra2007) have found that proficient Spanish–English bilinguals with extensive L2 immersion experience in English read temporarily ambiguous constructions in Spanish using parsing strategies they would use in English. More specifically, these bilinguals interpreted the relative clause (RC) as modifying the second noun (servant) in a complex noun phrase (El policía arrestó a la hermana del criado que estaba enferma desde hacía tiempo ‘The policeman arrested the sister of the servant who had been sick for some time’). This interpretation contrasted the one given by Spanish monolinguals and Spanish–English bilinguals with limited exposure to English, who reliably attached the relative clause to the first noun (sister). It is argued that extensive exposure to syntactic preferences in English directed the proficient bilinguals towards local attachment (servant), as it may have rendered this interpretation more available.
On a lexical level, Pavlenko and Jarvis (Reference Pavlenko and Jarvis2002) found semantic extension effects of L1 words in Russian–English bilinguals in a narrative performance task. Also, degradation effects of L1 lexical representations are reported, leading to borrowings (Boyd, Reference Boyd, Hyltenstam and Viberg1993; Latomaa, Reference Latomaa1998) and lexical retrieval difficulties or reduction of lexical diversity in L1 (Laufer, Reference Laufer and Cook2003). It should be noted that backward transfer effects are not necessarily negative, as L1 processing may benefit from L2 influences in case of linguistic convergence across languages. In support of this notion, Van Hell and Dijkstra (Reference Van Hell and Dijkstra2002) found that proficient Dutch–French bilinguals responded faster in a lexical decision task to Dutch–French cognates than to non-cognates. This was not the case for less proficient bilinguals. In sum, both L1 representations and online processing of L1 words may be affected by the L2 on both a formal and semantic level.
English orthography is an outlier amongst other orthographies (Share, Reference Share2008). It is considered to be a deep orthography with many inconsistencies and complexities (Seymour, Aro & Erskine, Reference Seymour, Aro and Erskine2003). One of the complexities is the inconsistency in compound spelling, as compounds can be spaced, hyphenated or concatenated. Spacing within English compounds can cause considerable processing uncertainty during the syntactic analysis of a sentence. In a sentence like ‘Time flies like an arrow, fruit flies like bananas’ a spaced compound like ‘fruit flies’ introduces ambiguity and may induce initial misparsing, which in turn requires syntactic reanalysis. Despite this potential for ambiguity, the spaced format is by far the most common format an English compound appears in. Kuperman and Bertram (Reference Kuperman and Bertram2013) estimate the number of spaced compounds in English at roughly 75,000 types, while the type count of hyphenated (ice-cream) or concatenated (database) compounds is only 2,900 and 1,600, respectively. A further complication in English spelling patterns is that – contrary to prescriptive rules – a substantial number of compounds (2,306) occur in two or even three spelling formats (girlfriend, girl friend, and girl-friend) with different frequencies (Kuperman & Bertram, Reference Kuperman and Bertram2013). As shown in Kuperman and Bertram (Reference Kuperman and Bertram2013) and Falkauskas and Kuperman (Reference Falkauskas and Kuperman2015), orthographic uncertainty created by multiple spelling variants leads to weakening of mental representations of compound words and adds to the effort of recognizing those compounds in sentence context or in isolation (see also Rahmanian & Kuperman, Reference Rahmanian and Kuperman2017).
Intuitively, an orthographic system aggravated by this level of ambiguity and processing cost would be unlikely to be adopted by a speller of a language with a more consistent set of conventions. Yet, the English habit to space compounds has started to appear in other languages as well, including Dutch and Finnish in which spacing goes against spelling regulations (Dings, Reference Dings2010; Eerola, Reference Eerola2010; Ylikulju, Reference Ylikulju2004). We will refer to this phenomenon as “the English disease”, as one reason for this phenomenon may be a backward transfer of orthographic biases from a prestigious and in-demand L2 language like English into a speller's L1 (Eerola, Reference Eerola2010).
It is also possible that certain properties of the compounds contribute to the tendency to insert spaces into Finnish compounds. Thus, Kuperman and Bertram (Reference Kuznetsova, Brockhoff and Christensen2013) found in the 2008 corpus of English Wikipedia (including 1.2 billion tokens) that orthographic choices for English compound spelling are determined by some lexical and distributional characteristics of a compound and its constituents. For instance, compounds that have longer left constituents, higher constituent frequencies, lower whole-word frequency and greater semantic similarity across constituents are more likely to be spaced than to be concatenated.
Another reason for the emergence of spacing in Finnish compounds may be the appeal of a space as an orthographic segmentation cue. Research on spacing in English and German compounds (Cherng, Reference Cherng2008; Falkauskas & Kuperman, Reference Falkauskas and Kuperman2015; Inhoff, Radach & Heller, Reference Inhoff, Radach and Heller2000; Juhasz, Inhoff & Rayner, Reference Juhasz, Inhoff and Rayner2005) invariably shows an early processing advantage for spaced compounds in comparison to concatenated ones (note that spacing is against German spelling conventions). The proposed reason for the advantage is that the space clearly indicates the constituent boundaries and thereby facilitates segmentation of a compound into its constituent morphemes. This initial speed-up is however offset by a later processing cost during the phase in which constituent meanings are integrated into a unified representation. In general, spaced compounds are processed slower than concatenated ones (Inhoff et al., Reference Inhoff, Radach and Heller2000; Juhasz et al., Reference Juhasz, Inhoff and Rayner2005).
While consequences of introducing spacing and hyphenation to compounds in languages with different spelling conventions are well understood, to our knowledge, no study has examined processing implications of borrowing spelling conventions of L2 in L1. Our paper zooms in on an orthographic backward transfer of spelling preferences in English compounds onto Finnish spelling. Spelling rules prescribe that Finnish compounds be either written in concatenated (pihajuhla ‘garden party’, kylpyhuone ‘bathroom’) or hyphenated format (ulko-ovi ‘outer door’); no spacing is allowed. Yet the prevalence of spaced compounds in Finnish (Eerola, Reference Eerola2010) invites the question whether processing such compounds is facilitated or hindered by the spelling format of their English Translation Equivalents (ETEs). We pursue this topic by selecting Finnish compounds with ETEs that vary in their spelling preferences. More specifically, we investigate whether the reading of a concatenated or illegally spaced Finnish compound is affected by the spelling (spaced or concatenated) of an ETE.
Logically, a backward transfer effect like this may unfold through at least two routesFootnote 1. First, Finnish readers may experience a direct backward transfer by applying English spelling biases to the representation and processing of respective Finnish translation equivalents. The impact of this route is likely to vary with the reader's overall English proficiency and her specific knowledge of English spelling patterns (see below for operationalization). Another possible route is indirect. English usage changes spelling preferences in the respective Finnish compounds in some parts of the Finnish-speaking community, due to the backward transfer. Productions of compounds with spaces emerge in Finnish written sources and inform the statistics of spacing in Finnish readers, regardless of their exposure to English. As argued in Rahmanian and Kuperman (Reference Rahmanian and Kuperman2017), existence of non-conventional orthographic alternatives weakens the representation and impedes the recognition of conventionally spelled word forms. Evidence for this route would come from a demonstration that the reading patterns of Finnish compounds reflect the spelling statistics of those compounds in Finnish (whether or not these statistics align with the statistics of English spelling). To anticipate the results, we found no evidence for the second route of an indirect backward transfer. In what follows, we emphasize the role of the direct backward transfer, but nevertheless examine the evidence for both routes.
In this study we presented Finnish–English bilinguals with Finnish compounds in a concatenated and spaced format such that the format was either congruent or incongruent with the preferred spelling of the ETE. The four conditions were as follows; congruent EC-FC: bathroom – kylpyhuone; incongruent EC-FS: bathroom – kylpy huone; congruent ES-FS: garden party – piha juhla; and incongruent ES-FC: garden party – pihajuhla, where E in the label stands for English, F for Finnish, C for concatenated and S for spaced. To reiterate, presenting Finnish compounds in spaced format goes against Finnish spelling regulations and should in principle generate a large processing penalty. If, however, orthographic backward transfer from L2 English to L1 Finnish takes place in this domain, one may expect that illegal spaced presentation of a Finnish compound would benefit from an ETE that is also spaced (thus piha juhla ‘garden party’ would be processed faster than kylpy huone ‘bathroom’). In addition, backward transfer should also facilitate the processing of concatenated Finnish compounds associated with a concatenated ETE in comparison to such compounds associated with a spaced ETE (hence kylpyhuone ‘bathroom’ may be processed faster than pihajuhla ‘garden party’). It is likely that the backward transfer benefit for spaced Finnish compounds would emerge against the backdrop of a more severe overall penalty for using space in violation of Finnish spelling habits. Thus, for the congruent condition the cost of using a space would be attenuated in comparison to the incongruent condition. In other words, we expect to see milder strains of the “English disease” in Finnish compounds if their ETEs are spaced in English.
Another question of interest for this study of linguistic backward transfer is the role of individual L2 proficiency. As earlier studies show, backward transfer typically occurs in proficient L2 speakers (Dussias & Sagarra, Reference Dussias and Sagarra2007; Liu et al., Reference Liu, Bates and Li1992). Hence, we expect that participants with a greater overall English skill show stronger effects of backward transfer and thus stronger effects of spelling congruency. We assess English language proficiency by using self-ratings of English proficiency, high-school grades in English, amount of use of English on a daily basis, and an English word chain test (Nevala & Lyytinen, Reference Nevala and Lyytinen2001; see description below).
Finally, the congruency effect is expected to be stronger in those compounds whose preferred English spelling is better known to Finnish readers. As Kuperman and Bertram (Reference Kuperman and Bertram2013) show, there is a lot of disagreement or uncertainty among English native speakers on how English compounds are to be spelled. It may be expected that this uncertainty is amplified for non-natives like the Finnish L2 speakers – even for those who are proficient. Hence, we assess the preferred spelling of English compounds by Finnish speakers and investigate whether or to what extent this preference interacts with the backward transfer effect.
We gauge processing costs and benefits of cross-linguistic orthographic congruency by recording eye-movements of Finnish readers while they inspect Finnish compounds in sentence contexts. By making use of an early (first fixation duration) and later first-pass reading measure (gaze duration) as well as a global reading measure (total reading time), we assess the possible impact of the backward transfer across the time course of lexical processing.
In sum, the present study investigates a) whether processing of spaced and concatenated Finnish compounds by Finnish readers is affected by the preferred spelling format of their ETEs; b) whether individual L2 proficiency in English modulates the degree of this orthographic backward transfer, and, in general, (c) what the processing consequences are for using an “illegal” space in Finnish compounds. We hypothesize that a) spaced Finnish compounds will be read faster when their ETE is thought to be spaced and that concatenated Finnish compounds will be read faster when their ETE is thought to be concatenated (as assessed by Finnish–English bilingual raters); b) these transfer effects will be modulated by English proficiency with stronger effects for more proficient L2 speakers; c) spaced compounds will initially be processed faster but overall slower than concatenated ones.
Method
Participants
Thirty-four undergraduate students of the University of Turku participated in the experiment. All were native speakers of Finnish and had normal or corrected-to-normal vision. Six were excluded prior to analyses due to excessive data loss. The remaining 28 participants (23 males, 5 females) were on average 23 years and all had Finnish as their native language with no other language learned in the home environment. English was taught from elementary school onwards at the age of 9 years (3rd grade). Prior to the experiment proper, the students’ English language proficiency was assessed by means of a background questionnaire (see section S1 in Supplementary Materials). The following four measures were collected: high school grades in English (possible range 4–10), use of English (1–5; 1: never, 5: more than 1 hour a day), subjective ratings of English proficiency (1–7; 1: beginner, 7: outstanding) and word chain test scores (Nevala & Lyytinen, Reference Nevala and Lyytinen2001). The subjective ratings were an average of ratings on speech production, speech comprehension, reading comprehension and written production. In the word chain test the participants were asked to segment unspaced English text by means of vertical bars. The test contained two texts: in one text only spaces were taken out but semantic and grammatical coherence were preserved (see section S2 in Supplementary Materials); in the other text, spaces were taken out and words were presented in a scrambled order (see section S3 in Supplementary Materials). For each text participants started to read from the very first line and they had a three-minute time limit to perform the segmentation task. Not one single participant read the texts in its entirety; even the best participant only managed to read and segment the first 10 lines of text. The outcome variable was the number of correctly segmented words in both texts taken together. The average high school grade was 8.4 (range 6–10), the average subjective rating was 5.5 (range 2.5–7), the average usage score was 3.0 (range 1–5) and the average word chain test score was 84 (range 25–161; the maximum score of 161 amounts to the first 10 lines of text).
We opted for using the results of the word chain test as a proxy of English proficiency. This test correlated well with our other measures of proficiency (English high school grade, r =.63, p < .001; self-ratings of English proficiency, r = .60, p= .001), was normally distributed (Shapiro-Wilk test W= 0.94, p = 0.14) and has been used in several contexts for this purpose (dyslexia: e.g., Lindgrén & Laine, Reference Lindgrén and Laine2011; Sikiö, Siekkinen & Holopainen, Reference Sikiö, Siekkinen and Holopainen2016; reading development: e.g., Häikiö, Bertram, Hyönä & Niemi, Reference Häikiö, Bertram, Hyönä and Niemi2009; bilingualism: e.g., Jalali-Moghadam & Kormi-Nouri, Reference Jalali-Moghadam and Kormi-Nouri2017; Lindgrén & Laine, Reference Lindgrén and Laine2011; Sikiö et al., Reference Sikiö, Siekkinen and Holopainen2016).
Apparatus
The eye movements were recorded with an EyeLink II eye-tracker manufactured by SR Research Ltd. (Kanata, Ontario, Canada). The eye-tracker is an infrared video-based tracking system combined with hyperacuity image processing with a spatial resolution of 0.4 degrees. The eye movement cameras are mounted on a headband (one camera for each eye). Two infrared LEDs for illuminating each eye are placed next to the eye movement cameras. The headband weighs 450 g in total. The cameras sample pupil location and pupil size at the rate of 500 Hz. Recording is performed by placing the camera and the two infrared light sources 4–6 cm away from the eye; in the present study the recording was monocular. Head position with respect to the computer screen is tracked with the help of a head-tracking camera mounted on the centre of the headband at the level of the forehead. Four LEDs are attached to the corners of the computer screen, which are viewed by the head-tracking camera, once the participant faces the screen. Possible head motion is detected as movements of the four LEDs and is compensated for on-line from the eye position records. The texts were presented on a 21-inch ViewSonic P225f computer screen, which had a refresh rate of 150 Hz.
Materials
Twenty-six psychology students of the University of Turku translated 146 English compounds into Finnish. The compounds were chosen in such a way that the meanings of those compounds and of their constituents were similar across languages. Only words that were correctly translated by at least 84% of the participants were chosen as experimental items. This amounted to 108 Finnish compound words. We consulted the English Wikipedia comprising about 1 billion word-tokens to assess the spelling format of the selected compounds in English (see Kuperman & Bertram, Reference Kuperman and Bertram2013, for more detailed information). Of the 108 compounds we selected, 56 were unambiguously spaced and 52 were unambiguously concatenated in the Wikipedia database. In other words, of the 108 Finnish target compounds 56 had a spaced English Translation Equivalent (ETE, e.g., garden party), whereas 52 had a concatenated ETE (e.g., bathroom).
Lexical statistics of the compounds were extracted from the Turun Sanomat database comprising 22.7 million word forms (Laine & Virtanen, Reference Laine and Virtanen1999). The two Finnish compound types were similar on several dimensions (lemma and constituent frequencies, bigram and initial and final trigram frequencies, all ps > .1). Compounds having a spaced ETE were slightly longer and had slightly longer second constituents (Spaced ETE: whole-word length 10.98 and second constituent length 5.73 characters; Concatenated ETE: whole-word length 10.15 and second constituent length 5.15 characters; all ps < 0.05 in a two-sample t-test). These factors were nevertheless controlled in the statistical analyses.
To estimate spelling patterns that Finnish readers may be exposed to, we extracted frequencies of our target compounds from an online corpus of one of Finland's largest online social networking websites: namely, the Suomi24 forum. The version of Suomi24 we used for our analyses contains about 2 billion tokens and includes all the texts between 1.1.2001 to 24.9.2016. Frequencies were identified both for the conventionally spelled unspaced forms (kylpyhuone, ‘bathroom’) and their non-conventional spaced counterparts (kylpy huone). Ninety-four out of 108 target compounds were found in the Suomi24 database. The vast majority of these compounds were heavily biased towards the conventional spelling: the average ratio of correct spelling frequency to total compound frequency in all spelling formats was 0.946 (median 0.987). For comparability with the prior literature on orthographic alternations (Kuperman & Bertram, Reference Kuperman and Bertram2013; Rahmanian & Kuperman, Reference Rahmanian and Kuperman2017), we calculated an information-theoretic measure of entropy for each compound, which quantifies an amount of uncertainty when selecting one of the available variants given their probability distribution. Entropy is calculated as follows. The frequencies of the correct and incorrect spelling variants form a probability distribution: for instance, the word kylpyhuone is found 3186 times in its correct spelling (without a space) and only 4 times in its incorrect variant (with a space). That is, the relative frequency or probability of the correct variant out of the total frequency of that word across both variants is 99.87% (3186/(3186 + 4)), and that of the incorrect one is 0.13%. Entropy H over a probability distribution is defined as:
 $$H = -\mathop \sum \nolimits_i^n p_i\log p_i,$$
$$H = -\mathop \sum \nolimits_i^n p_i\log p_i,$$where p is the relative frequency (probability) of each spelling variant i in the summed frequency of all n variants of the word, and the log is base 2. In our example, entropy is very low: H = −(0.9987 x log 0.9987 + 0.0013 x log 0.013) = 0.014. Entropy is a non-negative measure that is low in value when one of the variants is dominant, and high when there are many variants or when available variants are of similar probabilities. For instance, the word kuukivi “moonstone” occurs 65 times in its correct format and 2 with an inserted space (97% and 3%, respectively). The incorrect variant is somewhat closer in frequency to the correct one than in the example above, and entropy of this probability distribution is one order of magnitude higher, 0.194.
The same Finnish students who translated the compounds into Finnish provided ratings as to how they would spell the English compound words from our stimulus set: the rating scale contained responses “certainly spaced”, “probably spaced”, “probably concatenated”, and “certainly concatenated”. It should be noted that these participants were from the same population (University of Turku students) and age range and of equal proficiency as the students in the eye-tracking experiment proper, as supported by independent samples t-tests (participants in the eye-tracking experiment vs participants in the translation and spelling rating task; age: M = 23.3 vs M = 23.1, p = 0.87; high school grade for English: M = 8.4 vs M = 8.8, p = 0.13; self-ratings: M = 5.5 vs M = 6.1, p = 0.30; usage: M = 3.0 vs M = 3.3, p = 0.30; word chain test: M = 84 vs M = 86, p = 0.81; female-male distribution: 23–5, 21–5). For spaced compounds, the highest score (4) was granted when the rater indicated that the compound was certainly spaced, and the lowest (1) when the rater indicated that it was certainly concatenated. For concatenated compounds, the highest score (4) was granted when the rater indicated that the compound was certainly concatenated, and the lowest (1) when the rater indicated that it was certainly spaced. Participants were reliably more accurate in their average estimates of the compounds that are invariably spaced rather than concatenated in English (M = 3.36 vs M = 3.16, t(85) = −2.57, p = 0.012). Moreover, the average ratings of spaced compounds occupied a more narrow range skewed towards higher response accuracy (spaced: range = [2.58; 3.85]; concatenated: range = [1.88; 4.00]). We explain this discrepancy by the fact that the vast majority of compounds in English are spaced (see Kuperman & Bertram, Reference Kuperman and Bertram2013). Relying on this default option is an expected behavior, which provides a higher accuracy when judging English compounds. It is important to note that for both the translations and ratings the English compounds were presented in spaced and concatenated format simultaneously in order to avoid an initial bias towards one of the spelling formats. It is also important to note that these ratings were included in all analyses reported in the results section (variable name: Spelling Accuracy, abbreviated as SpellAcc, see also Figure 1).
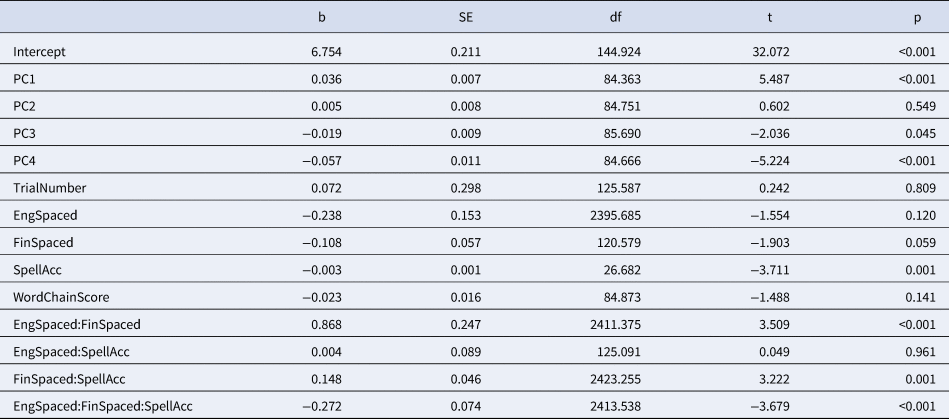
Figure 1. Interaction plots showing effects of spelling accuracy on first fixation duration (left), gaze duration (center) and total reading time (right) for Finnish compounds congruent with their ETE (English spaced, Finnish spaced, ESFS, purple lines; English concatenated, Finnish concatenated, ECFC, red lines) or incongruent with their ETE (English spaced, Finnish concatenated, ESFC, blue lines; English concatenated, Finnish spaced, ECFS, green lines). Grey areas represent 95% confidence intervals. The best-fit regression lines are based on raw data.
The 108 Finnish target compounds with either spaced or concatenated English translation equivalents were inserted in carrier sentences and presented in either spaced or concatenated format. Care was taken not to present the compounds as either the first or the last word in the sentence. All sentences were created such that they extended to the maximum of one line. All compounds appeared in either spaced or concatenated format, creating 4 conditions: ESFS (English spaced, Finnish spaced), ESFC (English spaced, Finnish concatenated), ECFS (English concatenated, Finnish spaced) and ECFC (English concatenated, Finnish concatenated). Two of these conditions (ESFS, ECFC) were congruent, i.e., the ETE format was similar to presentation format in Finnish, and two were incongruent (ESFC, ECFS) with the ETE format dissimilar to presentation format in Finnish. An example of the 4 conditions is presented below.
1. CONGRUENT, ESFS: Myöhään alkanut piha juhla yllätti … (‘garden party’)
2. INCONGRUENT, ESFC: Myöhään alkanut pihajuhla yllätti … (‘garden party’)
3. INCONGRUENT, ECFS: Suuri ja avara kylpy huone oli … (‘bathroom’)
4. CONGRUENT, ECFC: Suuri ja avara kylpyhuone oli … (‘bathroom’)
1–2. ‘The late-started garden party surprised…’
3–4. ‘The big and spacious bathroom was …’
We also conducted a norming study in which 22 students assessed the plausibility of the first constituent of the compound given the previous context (ratings 1–5; 1: not plausible; 5: very plausible; M = 3.56; SD = 1.00; range = 1.59–5.00). None of the students participated in the experiment proper or other pretests. This pretest was inspired by the study of Staub, Rayner, Pollatsek, Hyönä, and Majewski (Reference Staub, Rayner, Pollatsek, Hyönä and Majewski2007), who manipulated the preceding context of spaced compounds, such that their first constituents were more or less plausible continuations of the sentence. Consider the following two sentence alternants: a) ‘The new principal talked to the cafeteria manager at the end of the day’; b) ‘The new principal visited the cafeteria manager at the end of the day’. The first constituent ‘cafeteria’ is a less plausible continuation in sentence a) than in sentence b) and Staub et al. found that this plausibility effect is reflected in both first fixation and gaze duration. Hence we included this type of plausibility as a co-variate in the models, but it did not reach significance in any of them (neither as main effect nor in interaction with spacing). Consequently, it will not be reported further.
We created two lists such that each participant saw a given Finnish compound in one format only. It is important to note that we made no direct reference to English in the experiment, so this study examines the effects of cross-linguistic backward transfer in an experiment with Finnish participants reading Finnish compounds only, albeit some compounds were presented in a spelling format that did not follow Finnish spelling regulations.
The sentences were presented in Courier font size 14 so that each character position was of equal width. With a viewing distance of about 60 cm, three character spaces subtended approximately 1 degree of visual angle. With respect to the vertical axis, sentences were always presented halfway between the top and the middle of the screen. Sentences were all single-line sentences with a maximum of 79 characters on a line.
Procedure
Prior to the experiment proper, the eye-tracker was calibrated using a three-point horizontal calibration grid that extended over the entire computer screen. Before each sentence the participant had to fixate on a calibration point at the left side between the top and the middle of the screen. When the participant was fixating the calibration point, the experimenter pushed a button, which caused the sentence to appear on the screen starting at the same position as where initially the calibration was presented.
Participants were instructed to read sentences silently for comprehension at their own pace. They were further told that after varying intervals they would be presented with a statement about the sentence, to which they had to answer yes/no by pressing a corresponding button on a game-pad. There were 36 statements in total. A practice session containing six sentences preceded the experiment and the 108 experimental sentences were intertwined with 54 filler sentences without any spelling violations. The experiment took a maximum of 35 minutes.
Dependent variables
Three dependent eye movement variables were considered: first fixation duration, gaze duration and total reading time. First fixation duration gives insight into the early stages of processing the compounds. Typically, the compounds elicited 2 fixations (average 1.85), which is quite usual for compounds around 10 letters long (see Bertram & Hyönä, Reference Bertram and Hyönä2003). Gaze duration includes all fixations during first-pass reading and gives a good insight into processing the whole compound. Total reading time also includes later stages of processing and may indicate how well a word can be integrated into the sentence context, more difficult integration leading to more regressions and rereadings and hence leading to longer total reading times.
Lexical variables
Our primary variables of interest were two two-level factors representing two spelling formats in Finnish compounds (FinSpaced: levels FS and FC) and the spelling format in their ETEs (EngSpaced: levels ES and FC) – see examples above. We applied principal components analysis to the set of six inter-correlated control variables that are known to influence compound recognition effort: compound length; first constituent length; compound frequency; and first and second constituent frequency and family size. Only four of the principal components each explained over 5% of the total variance: together they explained 93% of variance. The four principal components were included as covariates in all regression models. Table 1 reports the loadings of individual predictors on the principal components solution and the proportion of variance that each principal component explains, as well as the cumulative proportion of variance.
Table 1. The principal components analysis of compound frequency and length measures.
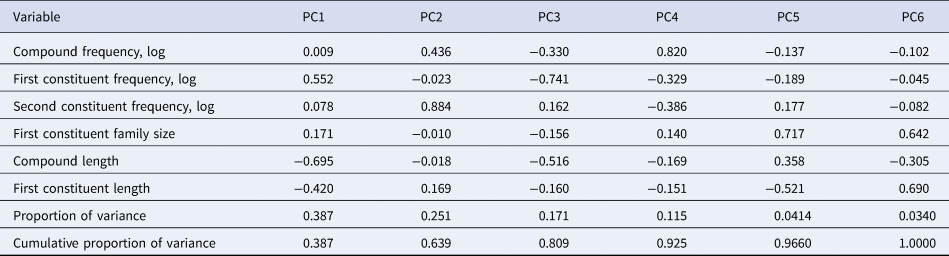
PC: Principal Component
The greatest loadings on PC1 were associated with length of the whole compound; PC2 with frequency of the second constituent; PC3 with frequency of the first constituent; and PC4 with frequency of compound occurrence. We used these four components as predictors in our models.
Other variables
We considered the ordinal trial number in the experiment as a covariate, to account for possible effects of fatigue or short-term learning during the experiment. For the participant-level variable English proficiency, see the Participants section above.
Statistical considerations
All continuous dependent variables were log-transformed to attenuate the influence of outliers, as indicated by the Box-Cox power transformation (Box & Cox, Reference Box and Cox1964). The plots presented in Figure 1 depict values of dependent variables (in ms) to ensure interpretability. Table 2 reports descriptive statistics for the dependent and independent variables.
Table 2. Descriptive Statistics of the Dependent and Independent Variables Entered into the Models (before and after Transformation).
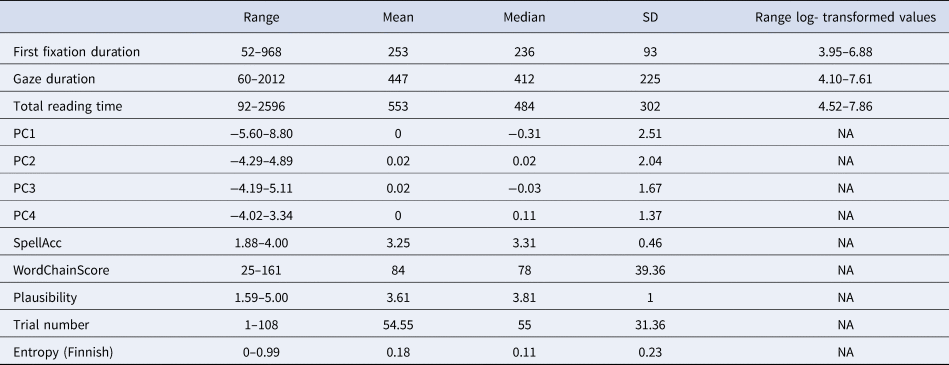
PC: Principal Component
Linear mixed-effects multiple regression models were used for this study with participant and word as random effects with the Gaussian (for continuous predictors) or binominal (for binary predictors) underlying distributions (Baayen, Reference Baayen2008; Baayen, Davidson & Bates, Reference Baayen, Davidson and Bates2008; Pinheiro & Bates, Reference Pinheiro and Bates2000). Packages lme4 v 1.1-6 (Bates, Maechler, Bolker & Walker, Reference Bates, Maechler, Bolker and Walker2015) and lmerTest package v. 2.0 (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2013) in the R statistical software 3.2.1 (R Core Team, 2015) were used. Stepwise backward elimination of non-significant fixed effects was performed. Only the fixed effects that reached the 5% significance level of p-values (obtained using the Satterthwaite's approximation for degrees of freedom) are reported below, unless stated otherwise. While the full random effect structure was tested, only those random effects were retained which significantly improved the performance of the models. An improvement was indicated by a significantly higher log likelihood estimate of the model when a given random effect was included, compared to when that random effect was not included (all ps < 0.05 using likelihood ratio tests). We used a single label (e.g., foot + ball) to represent random effects associated with both spaced and concatenated variants of the same Finnish compound (football, foot ball). Nesting the spelling variance under this label did not lead to an improved model in any of the analyses. After fitting a model, we removed outliers if they were outside of the range of -2.5 to 2.5 units of standard deviation away from the residual error of the model. The model was then refitted to the trimmed data set. No model showed a large degree of collinearity, as indicated by medium condition numbers below or equal to 13.
Nonlinearities were explored for all predictors and, where warranted by the increase in the model performance, modelled with the restricted cubic splines function with three knots. The body of the paper reports regression coefficients for simple main effects and interactive terms if predictors in question entered into an interaction, and regression coefficients for main effects of predictors if no interaction was observed. Full specifications of regression models are provided in the Appendix.
Results and discussion
The eye-movement record for target words consisted of 3,024 data points. We removed trials in which the compound was skipped or the first fixation duration was shorter than 50 ms. The resulting data pool consisted of 2,921 data points or 97% of the original data pool. In what follows, we organize the reporting of results by the main questions posited in the Introduction
Critical interaction of English spelling, Finnish spelling, and spelling accuracy
The main hypothesis of this study is that the preferred spelling of English Translation Equivalents (ETEs) affects recognition of Finnish compounds, even though the conventional spelling for the latter is always concatenated. Thus we presented Finnish compounds in concatenated and spaced format, and expected them to be recognized with less effort if their English counterpart was congruent in preferred spelling to the presented format (bathroom – kylpyhyone; garden party – piha juhla), in comparison to the incongruent conditions (bathroom – kylpy hyone; garden party – pihajuhla). This pattern of results was indeed found. It is important to point out though that the congruency effect pertained to the preferred spelling format of Finnish–English bilinguals: that is, the congruency effect was modulated by the accuracy with which a cohort of Finnish students identified the correct spelling of the English compound in a separate norming study.
The easiest way to present the interaction is to consider each condition separately. Consider the ESFS condition (purple line, Figure 1). In all three measures (FFD, Gaze, Total reading time), durations on spaced Finnish compounds become shorter the more Finnish L2 speakers are convinced that the ETE is spaced as well. In contrast, the ECFS condition (green line, Figure 1) elicited longer durations in first fixation duration and total reading times on Finnish spaced compounds the more Finnish L2 speakers are convinced that the ETE is concatenated. Yet when Finnish speakers (wrongly) believe that the ETE is spaced in this condition (i.e., the ratings of spelling accuracy approximate 2.0), durations become much shorter in first fixation duration and total reading time. For the ESFC condition (blue line, Figure 1), longer durations emerge when reading concatenated Finnish compounds, the more Finnish L2 speakers are convinced that the ETE is spaced. Finally, for the ECFC condition (red line, Figure 1), durations on concatenated Finnish compounds become shorter the surer Finnish L2 speakers are that the ETE is concatenated too. In sum, the more Finnish L2 speakers were convinced that a spaced ETE is really spaced or a concatenated ETE is really concatenated, the less time they took to process their congruent Finnish counterparts and the more time they took to process the incongruent Finnish counterparts.
This pattern of results is reflected in a critical three-way interaction of English spelling (ES vs EC), Finnish spelling (FS vs FC), and the average accuracy of English spelling (SpellAcc) as presented in Figure 1. The interaction was reliably present in all three measures (first fixation duration: b = −0.107, SE = 0.051, t = −2.117, p = 0.034; gaze duration: b = −0.267, SE = 0.071, t = −3.754, p < 0.001; and total reading times: b = −0.272, SE = 0.074, t = −3.679, p < 0.001; see Tables B1-3 for the full models). To summarize, the English translation equivalents that were correctly identified as typically spaced led to faster processing of Finnish compounds presented (illegally) in spaced format. The opposite effect was observed in the incongruent condition where Finnish concatenated compounds had spaced English translation equivalents (ESFC): being more confident about the preferred spaced format of the English compound led to inflated durations.
These data patterns are particularly compelling given that the experiment was conducted in Finnish, with Finnish stimuli and without any reference to the English lexical system. We conclude that the data supported our hypothesis of the direct backward transfer effect of English spelling on comprehension of Finnish compounds, and the modulating role of individual awareness of the distributional patterns in English orthography. In order to assess whether frequency and/or length characteristics did not interfere with the observed transfer effects, we also ran the analyses in which we interacted the four principal components with our critical three-way interaction and its two-way subparts. None of these interactions came out significant. So, we are reasonably confident that the frequency/length characteristics are accounted for and do not interfere with our critical results.
Main effect of English proficiency
The word chain score reflecting individual English proficiency showed consistent facilitatory effects across cumulative eye-movement measures. Higher proficiency correlated with shorter gaze durations [b = −0.04, SE = 0.001, t = −3.258, p = 0.003] and total reading times [b = −0.003, SE = 0.001, t = −3.711, p < 0.001, see Table B2 and B3]. Against the expectation, English proficiency did not modulate the congruency effect.
Main effect of spacing in Finnish compounds
All Finnish compounds in our study were presented in both a spaced and concatenated format. The presence of a space led to a processing advantage in the early processing stage as indicated by shorter first fixations in the spaced compared to the concatenated format [b = −0.031; SE = 0.011; t = −2.771, p = 0.006, model not shown]. This advantage is however reversed in later measures, where concatenated compounds came with shorter gaze durations [b = 0.196, SE = 0.015, t = 12.887, p < 0.001] and total reading times [b = 0.222, SE = 0.015, t = 14.590, p < 0.001, models not shown]. The observed tendency for an early speed-up followed by the later cost of semantic integration is in line with prior reports on the eye-movement behavior in spaced compounds (Juhasz et al., Reference Juhasz, Inhoff and Rayner2005).
Spelling entropy in Finnish
One possibility for the backward transfer from English spelling patterns to Finnish reading behavior is an indirect route, whereby Finnish spelling patterns change under the influence of English and change statistical preferences of Finnish readers who get exposed to non-conventional spelling regardless of their familiarity with English. We tested this possibility by considering spelling entropy of Finnish compounds as a potential variable affecting reading times (see motivation in the Introduction). More specifically, we fitted a set of models to a subset of eye-movements that represented 94 compounds (out of 108) that we had the corpus-based spelling statistics for (2,568 data points): dependent variables were first fixation duration, gaze duration and total reading time. None of the models (not shown) revealed a reliable main effect of spelling entropy on reading times; nor did we observe a reliable two-way or three-way interaction of spelling entropy with the preferred spelling of the English translation equivalent, the spelling format in which the Finnish compound was presented, individual English proficiency, or familiarity with the preferred English spellings for compound words. We conclude that – for the present set of Finnish compounds and the present cohort – critical reading behaviors that emerged in different experimental conditions (Figure 1) did not originate from the spelling preferences of those Finnish compounds. Instead, they are likely to reflect a more direct backward transfer of English spelling biases, unmediated by the Finnish spelling choices.
Finally, we did observe an effect of trial number in the regression model for total reading time: compounds towards the end of the experiment were processed faster, probably due to habituation to the task.
General discussion
The focus of the present paper is a linguistic phenomenon of borrowing orthographic conventions of English spelling in Finnish, and the implications of this phenomenon for processing behavior. As outlined in the Introduction, the prescriptive spelling of compound words in Finnish only allows concatenated (unspaced) and hyphenated formats, but spaced spelling has become common in Finnish, arguably due to the availability and dominance of this spelling format in English (Eerola, Reference Eerola2010). Our goal was to test how the English-to-Finnish backward transfer of spelling conventions affects online Finnish compound processing. To this end, we registered eye movements of Finnish–English bilinguals reading Finnish compounds in concatenated and (illegally) spaced format. Critically, the compounds were selected to have English Translation Equivalents (ETEs) that show a strong bias towards either a concatenated or spaced format in L1 speakers of English (see examples in the Introduction). We expected a decrease in effort if the Finnish spelling format was congruent, rather than incongruent, with a preferred spelling format of its ETE. In other words, we expected to observe the congruency effect not only for spaced Finnish compounds linked to spaced ETEs, but also in the case of concatenated Finnish compounds linked to concatenated ETEs. We argued that such congruency effects would be equivalent to demonstrating the presence of a backward orthographic transfer. We expected the congruency effects to be particularly pronounced in Finnish participants with a greater proficiency in English, and in compounds whose spelling preferences in English are more familiar to an average Finnish speaker. In other words, we hypothesized that the backward transfer would be especially strong in situations that afford better familiarity with a pattern being back-transferred from an L2 to an L1. Finally, we hypothesized that a spaced format would lead to an initial benefit but an overall inflation of the recognition effort, as reported in previous cross-linguistic work.
All but one of our hypotheses was confirmed. First, the critical three-way interaction of Finnish spelling, English spelling and Spelling accuracy was reliable in all reading measures (first fixation duration, gaze duration and total reading time, see Tables B1-B3 in the Appendix). The interaction reflected that spaced Finnish compounds were read faster when their ETE was thought to be spaced and concatenated Finnish compounds when their ETE was thought to be concatenated (as assessed by Finnish–English bilingual raters). We examined the hypothesis that the backward transfer does not proceed directly from individual familiarity with English spelling preferences but is rather mediated by the English-induced changes that Finnish spelling conventions for compounds have been undergoing (Eerola, Reference Eerola2010). We found no support for the mediated route: that is, entropy of the spelling patterns attested for Finnish target compounds in a large unedited corpus of Finnish showed no influence on how much cognitive effort those compounds gave rise to during sentence reading. Yet there is the possibility that a different selection of Finnish compounds – i.e., one that offers a broader range of the incidence of illegal spacing – might demonstrate a systematic relationship between the entropy of a compound's spelling patterns and the time it takes to recognize that compound even in its conventional form (see examples in Falkauskas & Kuperman, Reference Falkauskas and Kuperman2015; Kuperman & Bertram, Reference Kuperman and Bertram2013; Rahmanian & Kuperman, Reference Rahmanian and Kuperman2017).
The hypothesis that the transfer effects would be modulated by individual proficiency of Finnish participants in English was not confirmed: that is, English proficiency did not enter into interactions with spelling formats of Finnish compounds or their ETEs. Apparently, all Finnish L2 speakers were proficient enough in English to be susceptible to backward transfer influences. Indeed, all of the participants were reasonably or even highly proficient L2 speakers of English (see Methods). Hence it is quite possible that a wider range of proficiency and a larger sample size might have shown a modifying role for individual proficiency on the transfer effect.
However, there was enough variation in English proficiency to generate a main effect in reading times; higher English proficiency corresponded with shorter Finnish compound reading times. This may seem surprising as the experiment exclusively presents Finnish sentences to Finnish participants. However, other bilingual studies also show that L1 proficiency is related to L2 proficiency. For instance, developmental reading studies showed that knowledge of L1 spelling-sound correspondences is a predictor of L2 word reading ability and L1 vocabulary and grammatical skills are found to be related to L2 reading comprehension (see Jared, Reference Jared, Pollatsek and Treiman2015, for a survey). These studies suggest that the development of metalinguistic awareness through L1 may facilitate L2 language processing. In the field of speech fluency, several studies have shown a strong relationship between L1 and L2 fluency (see De Jong, Groenhout, Schoonen & Hulstijn, Reference De Jong, Groenhout, Schoonen and Hulstijn2015, for a survey). De Jong et al. (p. 239) noted that “it would be futile for an L2 speaker to strive for using very few filled pauses in his L2 when he tends to be an ‘uhm’-er in his L1.” In other words, a fluent speaker in L1 is more likely to be a fluent speaker in L2 as well. Thus L2 language proficiency is quite naturally related to L1 language proficiency, not only in the domain of reading. In our case we suggest that better proficiency in English is indicative of better language skills in general, allowing for faster processing of the Finnish sentences as well.
In accordance with our third hypothesis, we observed that illegally spelled spaced Finnish compounds were initially processed faster than their concatenated counterparts, but that in later measures the effect reversed. This was found in earlier studies as well (Inhoff et al., Reference Inhoff, Radach and Heller2000; Juhasz et al., Reference Juhasz, Inhoff and Rayner2005) and supports the idea that spaces are salient segmentation cues, allowing readers to quickly determine word boundaries and process the first constituent. Yet, as in the previous studies, the presence of spaces slows down later processes to the extent that, overall, concatenated compounds are read faster than spaced ones. Inhoff et al. (Reference Inhoff, Radach and Heller2000) argued that longer durations in later processing measures reflect that constituents of spaced compounds are more difficult to integrate into the unfolding sentence representation. That is, spaces between constituents make the reader unsure whether the constituents belong to a compound word or are independent linguistic units. In addition, attentional allocation extends further to the right and is more likely to extend over two lexical units when they are spatially unified rather than separated (Häikiö, Bertram & Hyönä, Reference Häikiö, Bertram, Hyönä and Niemi2010). In the case of spaced compounds, initial visual attention is typically allocated to the first constituent only, facilitating early processes like segmentation but delaying later processes like second constituent processing and constituent integration.
Theoretical embedding and implications of the current study
Our study is in line with single-word recognition studies that have shown that bilinguals activate representations in both L1 and L2 when performing a task in either of them. Most relevant for the current study are experiments that have found cross-language effects of translation equivalents. For instance, Grainger & Frenck-Mestre (Reference Grainger and Frenck-Mestre1998) found that English target word recognition of English–French bilinguals was facilitated by non-cognate translation equivalent primes in French (e.g., arbre–tree). The translation priming effects were observed with very brief prime exposures (29–43 ms) and were signicantly stronger in a semantic categorisation task than in a lexical decision task. These results also suggest that the cross-linguistic lexical activation is immediate and strongly mediated by semantic representations. Similarly, Duñabeitia, Carreiras, and Perea (Reference Duñabeitia, Perea and Carreiras2010) showed a significant masked translation priming effect for both cognates and noncognates with Spanish–Basque bilinguals. It should be noted that these translation effects are typically obtained with highly fluent bilinguals; for less fluent bilinguals L2-to-L1 effects are small or non-existing (see Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010, for a survey on translation equivalent priming studies). However, as the priming effects Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2010) found are similar in both directions, they came to the conclusion that highly fluent bilinguals develop symmetrical between-language links.
Bice and Kroll (Reference Bice and Kroll2015) showed that the lexical network of an L1 may already change during early stages of second language learning. In their EEG study they found an emerging N400 cognate effect in L1 English for beginning learners of Spanish. However, the cognate effect was not found in the lexical decision latencies. Whitford and Titone (Reference Whitford and Titone2015) showed that frequent exposure to an L2 may affect L1 processing at a behavioral level as well, even when the bilinguals have L1 as the dominant language. In their study English–French bilinguals with high versus low current L2 exposure exhibited increased L2 reading fluency (faster reading rates, shorter forward fixation durations), but decreased L1 reading fluency (slower reading rates, longer forward fixation durations). Moreover bilinguals with high L2 exposure had a larger perceptual span (the area from which useful information for reading is extracted during a fixation) in L2 and a smaller perceptual span in L1 than bilinguals with relatively low L2 exposure. The bilinguals in our study also had high L2 exposure: that is, they have been extensively exposed to English through their school education, popular culture, and, currently, in the academic environment; as practically all study course books are in English and several lecturers teach in English. As a consequence, they have been frequently exposed to spaced and concatenated English compounds as well.
In sum, this study presents novel evidence that the intensity and success of backward transfer is contingent (a) on the distributional patterns of the transferred phenomenon in L1 (i.e., the bias towards spacing in English compounds among English speakers), and (b) on the level of familiarity that speakers of L2 have with this specific phenomenon. We have used the term ‘disease’, because – as several studies showed, and this study is no exception – compounds are processed faster and more efficiently when they are spelled in concatenated rather than spaced format. The crosstalk between Finnish and English compounds in this study indicates that exposure to the orthographic format of English compounds leaves traces that have implications for Finnish compound processing and supports the view that a well-established L2 may mediate lexical processing in L1 at an orthographic level. This adds to the evidence that cross-linguistic influences are bidirectional, even in case L2 acquisition has been sequential.
Author ORCIDs
Victor Kuperman, 0000-0001-8961-3767
Acknowledgements
This study was financially supported by the Ministery of Science and Higher Education of the Russian Federation (grant No. 14.Y26.31.0014.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728919000312
Appendix: Linear mixed-effects multiple regression models
Table B1. Model fitted to log-transformed first fixation duration (N = 2623, after trimming N = 2554). Random by-compound intercepts SD = 0.047, random by-participant intercepts SD = 0.097, random by-participant slopes of SpellAcc SD = 0.027. Residual SD = 0.244. Reference levels of English (Eng) and Finnish (Fin) spelling are Concatenated. PC1-4 represent principal components of the lexical variables. Reported are the estimated regression coefficient, standard error, degrees of freedom and the t- and p-value for each predictor and interaction term.

Table B2. Model fitted to log-transformed gaze duration (N = 2623, after trimming N = 2570). Random by-compound intercepts SD = 0.090, random by-participant intercepts SD = 0.228. Residual SD = 0.345. Reference levels for English (Eng) and Finnish (Fin) spelling are Concatenated. PC1-4 represent principal components of the lexical variables. Reported are the estimated regression coefficient, standard error, degrees of freedom and the t- and p-value for each predictor and interaction term.
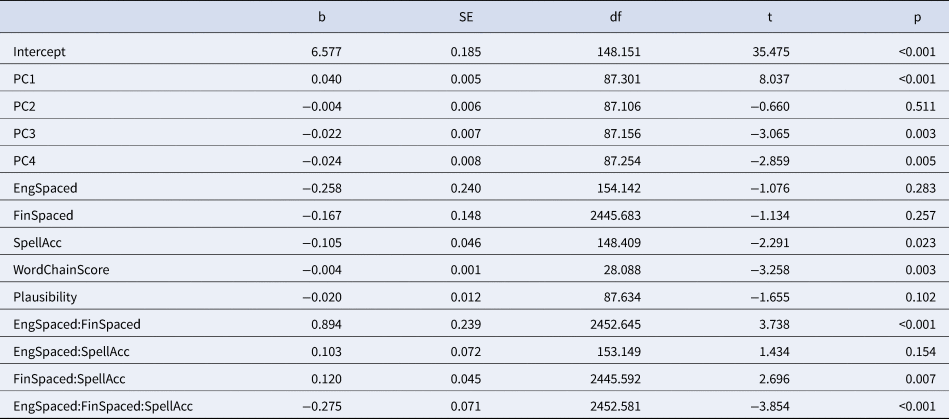
Table B3. Model fitted to log-transformed total reading time (N = 2623, after trimming N = 2571). Random by-compound intercepts SD = 0.128, random by-participant intercepts SD = 0.123, random by-participant slopes of SpellAcc SD = 0.053. Residual SD = 0.361. Reference levels for English (Eng) and Finnish (Fin) spelling are Concatenated. PC1-4 represent principal components of the lexical variables. Reported are the estimated regression coefficient, standard error, degrees of freedom and the t- and p-value for each predictor and interaction term.