


Before articulation can start, speakers must, to some extent, mentally prepare (‘pre-plan’) what they are about to say. There is debate, however, over the scope of this pre-planning. How far into the to-be-produced utterance (or text) that they are about to produce must planning reach before output can be initiated? For example, recent research on language production has explored the particular conditions under which pre-planning must extend beyond the initial determiner-noun pair (Gleitman et al., Reference Gleitman, January, Nappa and Trueswell2007; Konopka & Kuchinsky, Reference Konopka and Kuchinsky2015; Konopka & Meyer, Reference Konopka and Meyer2014; Kuchinsky, Reference Kuchinsky2009; Kuchinsky et al., Reference Kuchinsky, Bock and Irwin2011). So, for a target utterance A-B, in some syntactic, semantic or lexical contexts, articulation can start as soon as A has been planned (e.g. Ferreira & Swets, Reference Ferreira and Swets2002; Griffin, Reference Griffin2001; Griffin & Bock, Reference Griffin and Bock2000). In other contexts, A-B must be planned (Allum & Wheeldon, Reference Allum and Wheeldon2009; Konopka, Reference Konopka2012; Lee et al., Reference Lee, Brown-Schmidt and Watson2013; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013). The research that we report in this article concerns how the language production system decides whether or not this more extensive pre-planning is required?
Mainstream contemporary theory of language production (often called syntax-based or hierarchical planning; e.g. Bock & Ferreira, Reference Bock, Ferreira, Goldrick, Ferreira and Miozzo2014; Chang et al., Reference Chang, Dell and Bock2006; Dell & O’Seaghdha, Reference Dell and O’Seaghdha1992; Ferreira & Dell, Reference Ferreira and Dell2000; Garrett, Reference Garrett and Bower1975) assumes that minimal pre-planing scope – and particularly the fact that in some contexts this extends beyond the initial noun – is syntactically determinedFootnote 1: Speakers (or writersFootnote 2) must pre-plan across a minimal syntactic unit before they can start outputting speech. One possibility is that before articulation can start, speakers must pre-plan the full verb-argument noun phrase (NP), at least for relatively short, simple sentences (e.g. Lee et al., Reference Lee, Brown-Schmidt and Watson2013; Martin et al., Reference Martin, Crowther, Knight, Tamborello and Yang2010, Reference Martin, Yan and Schnur2014; Roeser et al., Reference Roeser, Torrance and Baguley2019; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013). This is evidenced by, for example, the finding that articulation of sentences with coordinated subject NPs (The A and the B moved above the C) is delayed compared with sentences starting with simple subject NPs The A moved above the B and the C (e.g. Martin et al., Reference Martin, Crowther, Knight, Tamborello and Yang2010; Roeser et al., Reference Roeser, Torrance and Baguley2019; Wagner et al., Reference Wagner, Jescheniak and Schriefers2010; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013). For phrases with subordination (The A above the B), the evidence is conflicting, involving either less (Allum & Wheeldon, Reference Allum and Wheeldon2007) or more (Nottbusch et al., Reference Nottbusch, Weingarten, Sahel, Torrance, van Waes and Galbraith2007) advance planning than coordinated NPs. Lee et al. (Reference Lee, Brown-Schmidt and Watson2013) found direct evidence that the syntactic organisation of the NP mediates advance planning even when holding the words that appear in the output constant (see also Lee, Reference Lee2020).
These studies manipulated the syntactic structure of the target phrase – in terms of embedding (Allum & Wheeldon, Reference Allum and Wheeldon2007; Nottbusch et al., Reference Nottbusch, Weingarten, Sahel, Torrance, van Waes and Galbraith2007), number of head nouns (Martin et al., Reference Martin, Crowther, Knight, Tamborello and Yang2010; Smith & Wheeldon, Reference Smith and Wheeldon1999; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013), and attachment (Lee et al., Reference Lee, Brown-Schmidt and Watson2013). For example, Lee et al. (Reference Lee, Brown-Schmidt and Watson2013) investigated whether the advance planning of NPs is mediated by syntactic relations between phrase elements. In response to arrays of images, participants generated utterances in the form of instructions to the researcher, such as Click on the fork of the king that is below the apple. The image location of either the fork or the king in relation to the image of an apple changed the underlying syntactic structure of the utterance without affecting surface form (ignoring possible variation in prosody, which the authors did not study). Low attachment of the relative clause conveyed that the king is below the apple; high attachment conveyed that the fork was below the apple. The authors found longer onset latencies for high-attaching phrases and argued that this was due to the need for advance planning of the relative clause. This finding suggests that some or all of the dependencies within the NP had to be pre-planned: that is that the syntactic organisation of the initial NP determines whether or not planning extends beyond the first noun.
However, as with other studies involving the production of coordinated and subordinated NPs, Lee et al. (Reference Lee, Brown-Schmidt and Watson2013) manipulated not only grammatical form but also meaning. Thus, syntactic arrangement and semantic structure were confounded. Findings from these studies are therefore consistent with the hypothesis that the extent of advance planning is driven by syntactic processing. However, they are also consistent with the hypothesis that the extent of advance planning is semantically driven.
Semantic and syntactic processes are known to be closely intertwined during language production (Jackendoff, Reference Jackendoff1972; Konopka & Brown-Schmidt, Reference Konopka, Brown-Schmidt, Goldrick, Ferreira and Miozzo2014; Rizzi, Reference Rizzi and Haegeman1997). In particular, contrastive focus – the assignment of prominence to particular elements of a message – influences not only conceptual organisation but often also syntactic structure and prosody. Thus, planning scope may be shaped by both syntactic dependencies and semantic (referential disambiguation)/pragmatic (information structure) factors. Our study builds on this study by examining whether semantic relations alone, in the absence of syntactic structural differences, can affect the scope of pre-utterance planning.
The present experiment removes the semantic/syntactic confound in previous studies by holding syntax and lexemes constant across conditions, but manipulating meaning. We report an image-description experiment in which we manipulated referential contrast (Jackendoff, Reference Jackendoff1972) to examine the influence of semantic scope of the phrase determiner when pre-planning NPs with nominal modification while keeping syntactic structure and lexical content constant. We specifically controlled those features of the syntax tree that were manipulated in previous research, such as attachment (Lee et al., Reference Lee, Brown-Schmidt and Watson2013), number of nouns (Martin et al., Reference Martin, Crowther, Knight, Tamborello and Yang2010; Smith & Wheeldon, Reference Smith and Wheeldon1999; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013) and embedding (Allum & Wheeldon, Reference Allum and Wheeldon2007; Nottbusch et al., Reference Nottbusch, Weingarten, Sahel, Torrance, van Waes and Galbraith2007). Our study elicited phrases of the form The king’s magnet. This can express one of two different contrasts: The phrase could draw attention to one of several possessions of the king – his magnet and not, for example, his butter. The second noun in the phrase disambiguates the referential target from a competitor’s possessions. Alternatively the referent could be a specific magnet – the magnet in the possession of the king – and not, for example, the magnet owned by the sailor: There are competing referent objects for the first noun which is required for disambiguation of the possessed object/the second noun. In the first case the semantic scope of the determiner extends over both nouns: The determines magnet modified by king. In the second case the semantic scope of the determiner extends just to the first noun: The determines just king. However, importantly, there is only one legal syntactic parse for this phrase. This is shown in Figure 1a. Here The determines king, and the possessing nominal modifier king’s serves to determine magnet. The alternative shown in Figure 1b is not possible both because in this parse king lacks a determiner, which is required, and magnet is determined both by The and by king’s, which is not legal. So, at least within the syntactic conventions assumed by the existing sentence production literature that we have cited, The king’s magnet has only one possible syntactic parse and a single referent, but can communicate one of two distinct semantic contrasts.Footnote 3

Figure 1. Syntactic representations of the phrase ‘the king’s magnet’.
The present study tested the hypothesis that pre-utterance planning scope is influenced by semantic organisation of the message – in particular, the presence of contrastive referential relations – even in the absence of syntactic variation (under a specific, strict understanding of syntax as independent of semantics). Prior studies have shown that syntactic dependencies can constrain how much must be planned before utterance onset (e.g. Lee et al., Reference Lee, Brown-Schmidt and Watson2013; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013). However, because syntactic and semantic factors are often confounded, it remains unclear whether semantic structure can, in and of itself, influence planning scope. By manipulating contrastive focus while holding syntactic structure and lexical content constant, we examined whether relational semantics alone can modulate the extent of pre-planning.
We operationalised ‘pre-planning’ as the deployment of visual attention to referents prior to utterance onset, as indexed by gaze patterns. While this does not necessarily reflect full lexical or syntactic encoding, it plausibly reflects conceptual-level activation of referents (Griffin, Reference Griffin, Henderson and Ferreira2004). Specifically, we recorded eye movements on stimulus arrays depicting possession with two different levels of contrast, as illustrated in the example above. Eye movement on the stimulus array provides an effective indicator of rapid processes such as message planning (Griffin, Reference Griffin, Henderson and Ferreira2004; Griffin & Bock, Reference Griffin and Bock2000; Meyer & Lethaus, Reference Meyer, Lethaus, Henderson and Ferreira2004; Swets et al., Reference Swets, Jacovina and Gerrig2014). Data from eye tracking were necessary in the context of our experiment to understand what information provided by the visual array was used and when it became relevant (Griffin, Reference Griffin, Henderson and Ferreira2004; Meyer & Lethaus, Reference Meyer, Lethaus, Henderson and Ferreira2004); eye movements have been used as dependent variable of previous studies that manipulated contrast information (Brown-Schmidt & Hanna, Reference Brown-Schmidt and Hanna2011; Brown-Schmidt & Konopka, Reference Brown-Schmidt and Konopka2008; Brown-Schmidt & Tanenhaus, Reference Brown-Schmidt and Tanenhaus2006). We predicted earlier looks to the referent image of the second noun (magnet) in wide scope conditions (The king’s magnet contrasted with The king’s butter) compared to narrow scope conditions (The king’s magnet contrasted with The sailor’s magnet). We also measured time from stimulus display to response-onset. It is possible that differences in onset latency follow the same pattern, with longer onset latencies in the wide scope condition. However – at least in some contexts – pre-syntactic planning has been found not to directly influence planning duration (e.g. Gleitman et al., Reference Gleitman, January, Nappa and Trueswell2007; Konopka & Meyer, Reference Konopka and Meyer2014).
1. Method
In a within-subjects experiment, we used image arrays (Figure 2) to elicit noun-plus-modifier phrasesFootnote 4 in which we manipulated Noun Contrast of the first and the second noun in the target utterance (henceforth, N1 and N2, respectively), keeping lexical form and syntactic structure constantFootnote 5. We recorded eye movements to the image array. Earlier eye movements towards a contrasting but non-phrase initial image would be evidence that semantic scope affects utterance pre-planning independently of syntactic factors.

Figure 2. Example stimulus arrays. Participants produced either prenominal or postnominal phrases as indicated, uniquely identifying the circled image. This was preceded by a preview of a similar task with a specific contrast indicated in squared brackets (see Figure 3).
To eliminate alternative explanations, we incorporated two additional factors. We elicited NPs with modifiers that either preceded the head noun (a prenominal modifier; The king’s magnet) or followed the head noun (a postnominal modifier; e.g., The magnet with the king). By allowing participants to freely produce NPs with modifier location, we were able to eliminate alternative explanations related to head position (Allum & Wheeldon, Reference Allum and Wheeldon2007) and stimulus array: Head-initial phrases may allow planning of the modifier to be postponed until after production onset. A phrase-initial modifier, on the other hand, may require pre-planning across the head-noun. This was important because there is evidence that pre-planning takes into account the structural function of the phrase-initial noun (Brown-Schmidt & Konopka, Reference Brown-Schmidt and Konopka2015 but see Allum & Wheeldon, Reference Allum and Wheeldon2007).
Participants completed separate blocks of trials in which they responded by speaking – the typical output modality in previous research – and in writing (by typing on a computer keyboard). This was for the following reason: Almost all existing research on sentence production has focused on spoken utterances.Footnote 6 Comparing typed and spoken responses therefore allows us to generalise beyond one output modality: Some previous studies with spoken output might have wrongly interpreted effects related to, for example, fluency requirements as evidence for fundamental (modality-independent) pre-planning requirements (see Roeser et al., Reference Roeser, Torrance and Baguley2019). This is because in spoken production there is a pressure for fluency, whereas hesitations during written output have no communicational implications (e.g. Clark & Fox Tree, Reference Clark and Fox Tree2002).
1.1. Participants
Sample size was set a priori at 64 participants. Psychology students (57 female, 7 male, mean age = 20.4 years, SD = 5.4, range: 18–50) participated as part of a research-reward scheme. All participants were self-reported native speakers of British English, free of linguistic impairments, and had normal or corrected-to-normal vision. Five participants were replaced because of failure to follow task instructions or failure to provide well calibrated eye data.
1.2. Design and materials
Participants were presented with arrays containing two image pairs and four other images; see Figure 2. In each trial, participants were presented with an array with six cells. Image pairs were linked by a vertical line with the target image always appearing below its modifier. Participants were asked to produce a phrase that identified the highlighted image. Their response acted as instruction to the experimenter, who then clicked the phrase referent. The participant then saw the image that the experimenter had clicked. Participants were free to produce phrases with either prenominal or postnominal modification. Examples at the start of the experiment were provided for each of these options. As can be seen from Figure 2, contrast was dependent on choice of phrase structure.
To increase the salience of contrast and modifier, each target trial was preceded by a preview. This is visualised in Figure 3. In both the preview and the target trial, participants saw the same array. In the preview, participants produced an NP identifying one object (The sailor’s magnet/The magnet with the sailor in Figure 3). In the target trial, they were required to identify a different image. The first (N1) and second noun (N2) in the target utterance served the same contrastive functions in both preview and target and so NPs required to express preview and target were semantically isomorphic (and syntactically identical). This preview-target setup increased the participants’ awareness of the semantic contrast in the target referent. This is because in the preview participants had to encode the image pair (sailor-magnet in Figure 2a; king-butter in Figure 2b) that contained the semantic contrast for target phrase (i.e. king-magnet). For analysis, we used only preview-target pairs with the same NP structure (see Results section).
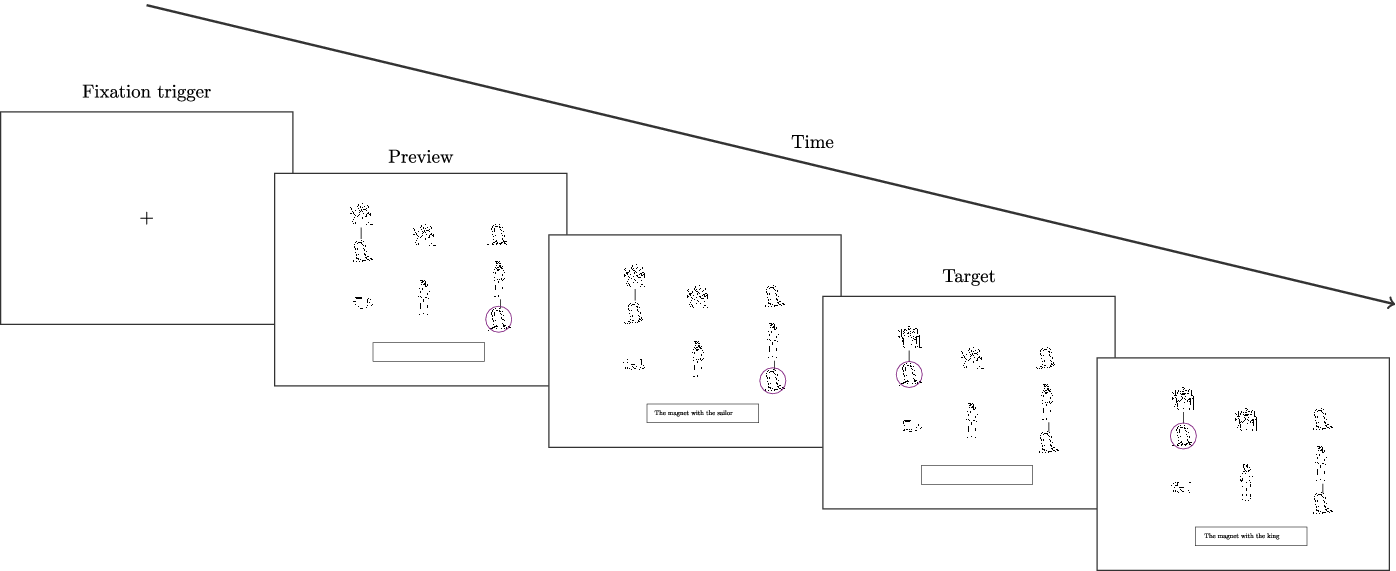
Figure 3. Example trial. Participants responded to a preview screen prior to producing an utterance for the target screen to increase their awareness of the semantic contrast. The example trial illustrates a N2 contrast condition if the participant used a postnominal phrase (‘The magnet with the king’ [and not the magnet with the sailor]) and a N1 contrast condition when the participant used a prenominal phrase (‘The king’s magnet’ [and not the sailor’s magnet]). For an example array with N1 contrast in prenominal phrases and N2 contrast in postnominal phrases, see Figure 2.
The remaining four cells of the stimulus arrays shown in Figure 2 were filled with four images that appeared in the target and the preview pair. This ensured that unique identification of the target object always required a specific noun-plus-modifier phrase.
Each participant completed a written and a spoken session. These manipulations rendered a N1 contrast/N2 contrast
 $ \times $
prenominal/postnominal
$ \times $
prenominal/postnominal
 $ \times $
written/spoken design.
$ \times $
written/spoken design.
Thirty-two arrays were createdFootnote 7. Black and white drawings were taken from the database of the International Picture Naming Project (Bates et al., Reference Bates, D’Amico, Jacobsen, Székely, Andonova, Devescovi, Herron, Lu, Pechmann and Pléh2003; Székely et al., Reference Székely, D’Amico, Devescovi, Federmeier, Herron, Iyer, Jacobsen and Bates2003, Reference Székely, Jacobsen, D’Amico, Devescovi, Andonova, Herron, Lu, Pechmann, Pléh and Wicha2004, Reference Székely, D’Amico, Devescovi, Federmeier, Herron, Iyer, Jacobsen, Anal’a, Vargha and Bates2005). Items were counterbalanced over four Latin Square lists (Contrast, Modality Type [speech, writing]). Order of modality session was counterbalanced between participants; half of the participants started with a written session and the other half with a spoken session. The location of preview and target pairs was randomised within each Latin square list. Two filler lists, each of 16 trials, were created. One filler list was used in the first session and the other in the second session. Fillers elicited structures that were different from those referred to in target trials to avoid strategic use of descriptions and anticipation of the target pair. For example, some fillers prompted the top image of image pairs, and colour (in combination with modifiers) was used for disambiguation (e.g. the cat’s green ball). Filler lists and stimuli were presented in randomised order within sessions. In total, each participant saw 64 arrays, 32 per modality (50% fillers).
To reduce the lexical variability in the response, we used pictures that were easy to name according to existing naming norms provided by the International Picture Naming Project. Summary statistics of picture naming norms are given in Appendix A (Table A1).
We recorded eye gaze to the stimulus array. To assess the time course of planning the second noun in the utterance relative to production onset and the likelihood of pre-onset planning of both noun, we calculated two variables: (1) time relative to production onset when gaze shifted from the image of N1 to N2; (2) proportion of trials for which this gaze shift happened before production onset. Gaze shift from the N1 referent to N2 was defined as the first fixation on the image of N2 after the gaze left N1 (fixation required a dwell time of at least 100 ms). These measures estimate the attention shift from the referent of the first noun to the preparation of the second noun (see e.g. Griffin, Reference Griffin, Henderson and Ferreira2004; Griffin & Bock, Reference Griffin and Bock2000; Meyer & Lethaus, Reference Meyer, Lethaus, Henderson and Ferreira2004; Roeser et al., Reference Roeser, Torrance and Baguley2019). AOIs were circular with a diameter equal to the height of the images.
1.3. Apparatus
Eye movements were recorded using an SR Research EyeLink 1000 desk-mounted eye tracker used in remote mode. Eye data were sampled at 500 Hz from just the right eye. The participant was seated 55 to 60 cm away from the lens. The experiment was built in SR Research Experiment Builder. Stimuli were displayed on a 19’ ViewSonic Graphic Series (G90fB) CRT monitor with a screen resolution of 1,280
 $ \times $
1,024 pixels and 85 Hz refresh rate using an Intel Core 2 PC. A Logitec headset and ASIO audio driver supported by a Creative SB X-Fi sound card were used for recording spoken output. An additional display and a mouse were used to allow experimenter response.
$ \times $
1,024 pixels and 85 Hz refresh rate using an Intel Core 2 PC. A Logitec headset and ASIO audio driver supported by a Creative SB X-Fi sound card were used for recording spoken output. An additional display and a mouse were used to allow experimenter response.
1.4. Procedure
Every experiment started with camera set-up, and 9-point calibration and validation. Participant and experimenter were seated at different screens unable to see each other’s screen. Each preview/target trial pair was initiated by fixating an ellipse at the centre of the screen (21
 $ \times $
21 pixels) for 200 ms. Recalibration was performed if this fixation trigger failed. The stimulus array then appeared, with a violet circle highlighting the image that was the target of the preview trial. The participants spoke or wrote NPs intended to uniquely identify the image, and then pressed enter. This activated mouse input for the experimenter who then clicked on the image identified by the participant’s utterance. For ambiguous utterances, the experimenter clicked a plausible referent image. Mouse clicks on the correct image prompted a green circle as feedback. Clicks on an incorrect image prompted a red circle. Feedback circles were shown for 250 ms to encourage participants to use unambiguous descriptions. The second image (the target) was highlighted immediately after the feedback circle disappeared. The target trial then proceeded in the same way as the preview trial. In the written condition participants were instructed to position their fingers over the keyboard at the start of the trial and to respond as quickly and accurately as soon as possible after appearance of the stimulus array. Participants were familiarised with the experimental task in 10 practice trials. The images, size 150
$ \times $
21 pixels) for 200 ms. Recalibration was performed if this fixation trigger failed. The stimulus array then appeared, with a violet circle highlighting the image that was the target of the preview trial. The participants spoke or wrote NPs intended to uniquely identify the image, and then pressed enter. This activated mouse input for the experimenter who then clicked on the image identified by the participant’s utterance. For ambiguous utterances, the experimenter clicked a plausible referent image. Mouse clicks on the correct image prompted a green circle as feedback. Clicks on an incorrect image prompted a red circle. Feedback circles were shown for 250 ms to encourage participants to use unambiguous descriptions. The second image (the target) was highlighted immediately after the feedback circle disappeared. The target trial then proceeded in the same way as the preview trial. In the written condition participants were instructed to position their fingers over the keyboard at the start of the trial and to respond as quickly and accurately as soon as possible after appearance of the stimulus array. Participants were familiarised with the experimental task in 10 practice trials. The images, size 150
 $ \times $
150 pixels, appeared around the centre of the screen. In the written condition participants gave their response in a text box (896
$ \times $
150 pixels, appeared around the centre of the screen. In the written condition participants gave their response in a text box (896
 $ \times $
50 pixels) that appeared in the centre of the screen. Participants could pause, if they wished, between trial pairs. The duration of the experiment was approximately 45 min.
$ \times $
50 pixels) that appeared in the centre of the screen. Participants could pause, if they wished, between trial pairs. The duration of the experiment was approximately 45 min.
1.5. Data analysis
We used Bayesian mixed-effects models (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2014) for statistical inference.Footnote 8 All models were fitted with maximal random effects structure, that is random intercepts for participants and items and by-participant and by-item slope adjustments for all predictors (Baayen et al., Reference Baayen, Davidson and Bates2008; Barr et al., Reference Barr, Levy, Scheepers and Tily2013; Bates et al., Reference Bates, Kliegl, Vasishth and Baayen2015). Predictors were sum-coded (Brehm & Alday, Reference Brehm and Alday2022; Schad et al., Reference Schad, Vasishth, Hohenstein and Kliegl2020) and reported as posterior estimates with 95% probability interval (95% PIFootnote 9).
To assess the strength of support for the effects of interest over the null hypothesis, Bayes Factors (BF) were calculated using the Savage-Dickey method (see Dickey et al., Reference Dickey and Lientz1970; Nicenboim & Vasishth, Reference Nicenboim and Vasishth2016; Wagenmakers et al., Reference Wagenmakers, Lodewyckx, Kuriyal and Grasman2010). BF = 2, for example, indicates that the alternative hypothesis is twice as likely compared to the null hypothesis given the data. BFs >3 indicate weak evidence, >8 moderate evidence, and >32 strong evidence for a statistically meaningful effect (see e.g. Baguley, Reference Baguley2012; Jeffreys, Reference Jeffreys1961; Lee & Wagenmakers, Reference Lee and Wagenmakers2014).
2. Results
Prior to analysis, we removed trials in which the participant paused for
 $ > $
2.5 secs at any point after production onset, trials where they self-corrected, and trials where the response did not unambiguously reference the target image (9.9% of trials in total). Trials in which participants gave different modifier positions in response to preview and target (5.6%) were also excluded, as were trials with onset latencies
$ > $
2.5 secs at any point after production onset, trials where they self-corrected, and trials where the response did not unambiguously reference the target image (9.9% of trials in total). Trials in which participants gave different modifier positions in response to preview and target (5.6%) were also excluded, as were trials with onset latencies
 $ > $
10 s (0.3%). Trials in which participants produced an utterance that contained neither prenominal nor postnominal modification were removed (speech: 0.9%, writing: 3.4%). For analysis of eye data, we removed a further 2.4% of the trials which had more than 75% of the eye fixations away from any of the images in the array, before production onset.
$ > $
10 s (0.3%). Trials in which participants produced an utterance that contained neither prenominal nor postnominal modification were removed (speech: 0.9%, writing: 3.4%). For analysis of eye data, we removed a further 2.4% of the trials which had more than 75% of the eye fixations away from any of the images in the array, before production onset.
As can be seen from Table 1, participant choice of modifier-position (prenominal or postnominal) was independent of Contrast: A full-factorial Bayesian logistic mixed-effects model found negligible evidence for a Contrast effect on Modifier-position choice (BF = 1.3) or any by-Contrast interactions (BFs
 $ < $
0.6). Participants were roughly equally likely to choose prenominal and postnominal constructions in the written modality, but showed a greater tendency towards postnominals when speaking (BF
$ < $
0.6). Participants were roughly equally likely to choose prenominal and postnominal constructions in the written modality, but showed a greater tendency towards postnominals when speaking (BF
 $ > $
100 for the main effect of modality). Model coefficients are summarised in Appendix B (Table B1).
$ > $
100 for the main effect of modality). Model coefficients are summarised in Appendix B (Table B1).
Table 1. Modifier choice

Note. Proportion of target trials in which participants produced a postnominal modifier (‘The king with the magnet’) instead of a prenominal modifier (‘The king’s magnet’) represented as model estimate with 95% PIs in brackets and empirical mean with standard error (SE).
We established the effect of Contrast on each of three dependent variables. From the eye data, we calculated the time relative to production onset when gaze shifted from the image representing the first noun to the image representing the second noun. We interpreted this as an indication of attention shift from the first to the second referent. We then evaluated the probability that this shift occurred prior to the participant starting to output the phrase. For completeness, we provide the posterior of the fixation time-course for the eye data in Appendix C for the time window prior to production onset. Last, we calculated onset latency – time from appearance of the circle prompt to output onset.
Gaze shift and onset latency were log-transformed; probability of gaze shift before output onset was analysed with a logistic model. All models were fitted with main effects and all interactions of Modality (written, spoken), preview/target, Modifier position (prenominal, postnominal), and Contrast (N1, N2). We then conducted a series of eight planned comparisons, based on posteriors from these models, to test for evidence of advance planning in the N2 contrast condition, relative to N1 contrast within each cell of the Modality by Modifier position by preview/target interaction.
We present findings from the overall model first. Then, for clarity, we report effects in just target trials, first in the written modality, then in the spoken modality. An overview of all fixed effects coefficients can be found in Appendix D (Table D1).Footnote 10
Findings from the main model were as follows: We found strong evidence for a main effect of Contrast (BF
 $ > $
100) showing earlier gaze divergence for N2 contrast. The evidence for all by-Contrast interactions was at best very weak (BF
$ > $
100) showing earlier gaze divergence for N2 contrast. The evidence for all by-Contrast interactions was at best very weak (BF
 $ < $
2). The analysis of the probability that gaze shift to the N2 referent occurred before production onset provided moderate evidence of a Contrast by Modifier-position by Modality interaction (BF = 8.5) and strong evidence of a Contrast by preview/target interaction (BF
$ < $
2). The analysis of the probability that gaze shift to the N2 referent occurred before production onset provided moderate evidence of a Contrast by Modifier-position by Modality interaction (BF = 8.5) and strong evidence of a Contrast by preview/target interaction (BF
 $ > $
100). These effects are unpacked below. In response onset latency, we found strong evidence for a main effect of Contrast (BF = 68), and substantial support for a Modifier-position by Contrast interaction (BF = 3.5). There was little or no evidence for other effects (BF
$ > $
100). These effects are unpacked below. In response onset latency, we found strong evidence for a main effect of Contrast (BF = 68), and substantial support for a Modifier-position by Contrast interaction (BF = 3.5). There was little or no evidence for other effects (BF
 $ < $
2) across any of the three dependent variables.
$ < $
2) across any of the three dependent variables.
2.1. Written output modality
Estimated mean time of gaze shift from the N1-referent to the N2-referent in the written condition, in Figure 4a, shows earlier gaze on N2 under N2 contrast for both modifier types (evidence for effect of contrast: prenominal BF = 15; postnominal BF = 23). In fact, for postnominal modifiers gaze shift in the N2 contrast condition tended to occur before production onset but not in the N1 contrast condition. For prenominal modifiers, gaze shift was observed after production onset but earlier for the N2 contrast condition.

Figure 4. Written production results. Estimates from full-factorial Modality
 $ \times $
preview/target
$ \times $
preview/target
 $ \times $
Modifier position
$ \times $
Modifier position
 $ \times $
Contrast Bayesian mixed-effects models. Error bars represent 95% PIs.
$ \times $
Contrast Bayesian mixed-effects models. Error bars represent 95% PIs.
The probability of gaze shift to occur before production onset followed the same pattern. Estimated probability was greater in the N2 contrast condition for both modifier types (prenominal: N1-contrast = .19, 95% PI [.13, .26], N2-contrast = .39, 95% PI [.31, .5], BF = 95; postnominal: N1-contrast = .27, 95% PI [.19, .35], N2-contrast = .55, 95% PI [.45, .65], BF
 $ > $
100).
$ > $
100).
The inferred cell means for the onset latency are visualised in Figure 4b. The results show that production onset latency was shorter under N2 contrast for postnominal modifiers (BF = 12) but not for prenominal modifiers (BF
 $ < $
0.05).
$ < $
0.05).
2.2. Spoken output modality
Estimated time of gaze shift from the N1 to the N2 referent in the spoken condition is shown in Figure 5a. Although parameter estimates suggest earlier gaze-shift for N2 contrast for postnominal modifiers, we found evidence for no effect in either modifier position (BF
 $ < $
0.08).
$ < $
0.08).
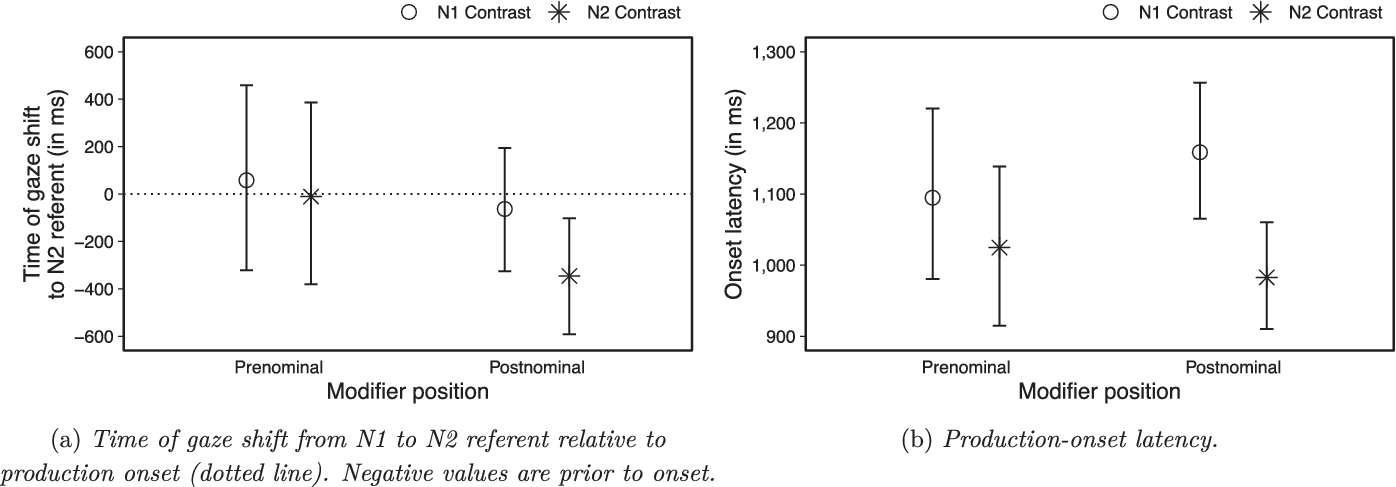
Figure 5. Spoken production results. Estimates from full-factorial Modality
 $ \times $
preview/target
$ \times $
preview/target
 $ \times $
Modifier position
$ \times $
Modifier position
 $ \times $
Contrast mixed-effects models. Error bars represent 95% PIs.
$ \times $
Contrast mixed-effects models. Error bars represent 95% PIs.
We found strong evidence indicating that the probability of pre-onset gaze-shift from N1 to N2 referent was greater in the N2-contrast condition in postnominals (N1-contrast: .51, 95% PI [.42, .6], N2-contrast: .81, 95% PI [.74, .87], BF
 $ > $
100) but not in prenominals (N1 contrast: .4, 95% PI [.29, .52], N2 contrast: .5, 95% PI [.38, .63], BF
$ > $
100) but not in prenominals (N1 contrast: .4, 95% PI [.29, .52], N2 contrast: .5, 95% PI [.38, .63], BF
 $ < $
0.8). These findings therefore reproduce Contrast effects found in written production for phrases with postnominal modifiers but not for prenominals.
$ < $
0.8). These findings therefore reproduce Contrast effects found in written production for phrases with postnominal modifiers but not for prenominals.
As can be seen from Figure 5b, we found strong evidence that production onset occurred sooner under N2 contrast when participants produced phrases with postnominal modifiers (BF = 26) but not when modifiers were prenominal (BF = 0.11). This is the same pattern as was found for written production.
3. Discussion
Our results support the hypothesis that conceptual-level semantic structure, particularly contrastive focus, affects scope of planning prior to utterance onset even in the absence of morpho-lexical and syntactic variation. Participants in our study directed attention to the second noun earlier when it served a contrastive function in utterances/texts in which surface syntax and word-forms were identical. Our results therefore demonstrate that contrastive focus – typically viewed as operating at the syntax-semantics interface – can impact pre-utterance planning independently of syntactic differences. These findings extend prior study showing syntactic effects on planning (e.g. Lee et al., Reference Lee, Brown-Schmidt and Watson2013) by demonstrating that semantic relations can drive early planning even in the absence of structural variation. Our findings clearly are not evidence against syntactic structure playing a role in shaping planning scope. They are, however, evidence against planning scope determination being exclusively driven by syntax. They also point to the possibility that the previous studies in which researchers have claimed syntax as the driver for variation in planning scope might in fact be observing effects of semantic structure.
Before we discuss the implications of these findings, we want to address three potential caveats. First, we did not find evidence that response latency was longer in N2 contrast conditions. Although this is perhaps surprising, it is consistent with findings of some previous studies (Griffin, Reference Griffin, Henderson and Ferreira2004; Swets et al., Reference Swets, Jacovina and Gerrig2014; but see Ferreira & Engelhardt, Reference Ferreira, Engelhardt, Traxler and Gernsbacher2006; Fodor, Reference Fodor1983; Kempen & Hoenkamp, Reference Kempen and Hoenkamp1987). In the postnominal condition, response latency was in fact reliably shorter where N2 was contrastive. This is likely to have been because the lexical name of the phrase-initial noun was pre-activated in the N2 contrast condition (in contrast to pre-activation of the N2 referent for N1 Contrast), allowing for quick response onsets. That we observed no such speed-up effect in the prenominal condition is likely because for prenominals, both nouns had to be lexically retrieved before production onset. Indeed, the time-course data in Figure C1 suggest that in the prenominal condition but not in the postnominal condition, participants attended to both phrase referents before production onset. Therefore, as both nouns in the prenominal condition had to be pre-planned, there was no timing advantage to be gained from a pre-activation of either noun. In contrast, that we observe the speed-up effect for onset latencies in postnominal phrases suggests that earlier looks to the N2 referent did not cascade into lexical retrieval, as lexical retrieval is known to be time-consuming (Griffin, Reference Griffin2001; Konopka & Bock, Reference Konopka and Bock2009; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013). Instead, it is possible that the postnominal modifier noun was retrieved after production onset, in parallel to production (Griffin, Reference Griffin2003).
Second, reviewers of a previous version of this article suggested that priming from the preview task may explain the contrast effect. This is plausible, although in principle there is no reason why pre-activation of the first noun should lead to pre-planning of the second noun. Some research suggests that pre-activation leads to faster speech onsets but not necessarily more advance planning (Hardy et al., Reference Hardy, Segaert and Wheeldon2020; Smith & Wheeldon, Reference Smith and Wheeldon1999; Wheeldon et al., Reference Wheeldon, Smith and Apperly2011, Reference Wheeldon, Ohlson, Ashby and Gator2013). Our preview task was identical in form to the experimental task. Therefore, a direct test of whether priming explains our eye movement findings would be to establish whether or not the same effects are present during preview. This analysis can be found in Appendix E: We again found higher probability of pre-onset gaze shifts under N2 Contrast in phrases with postnominal modification (N1 Contrast = .65, 95% PI [.56, .74], N2 Contrast = .78, 95% PI [.71, .85], BF = 6.78) although not in phrases with prenominal modification (N1 Contrast = .45, 95% PI [.33, .58], N2 Contrast = .5, 95% PI [.36, .63], BF < 0.4). This effect cannot be explained on the basis of lexical pre-activation.
Third, although throughout this article we have talked in terms of planning in advance of production onset, gaze shift to N2 in the written condition tended, in both contrast conditions, to be after the participant’s first keypress of the determiner. In the spoken condition, gaze shift was earlier, and tended to be at times equal to or earlier than determiner onset. Note that in all cases, the determiner was the same word (The) and therefore entirely predictable. Written output is both slower and unlike speech is not associated with expectation for output fluency (e.g. Clark & Fox Tree, Reference Clark and Fox Tree2002). This means both that there is more time available for planning in parallel with output (Damian & Stadthagen-Gonzalez, Reference Damian and Stadthagen-Gonzalez2009; Roeser et al., Reference Roeser, Conijn, Chukharev, Ofstad and Torrance2025), and that there is minimal pressure for participants to avoid hesitation between the determiner and N1. In contrast, speakers must balance between mental buffering of pre-planned items and intra-utterance pausing (Levelt & Meyer, Reference Levelt and Meyer2000; Meyer, Reference Meyer1997). To reduce pre-planning demands, and to maintain output fluency, speakers may assess the possibility of lexical retrieval in parallel with articulation (Griffin, Reference Griffin2003), and then delay output until the determiner and N1 can be produced without an intervening hesitation. This is particularly likely to be the case in the present study, given that the person to whom they were communicating was physically present.Footnote 11
Our findings, therefore, present a relatively complex picture of the mechanisms underlying phrase planning in writing and in speech. However, taken together, we believe they provide clear evidence that, at least in some contexts, semantic dependency alone determines the minimum obligatory unit of pre-planning: Meaning-level representation of the referent impacts the size of the minimum linguistic unit that must be prepared prior to output-onset. This conclusion is non-trivial. Under a lexical-incremental understanding of pre-planning (for review see Bock, Reference Bock and Ellis1987; Bock & Ferreira, Reference Bock, Ferreira, Goldrick, Ferreira and Miozzo2014; Wheeldon & Konopka, Reference Wheeldon and Konopka2023), in order to start language output, only the initial referent needs to be identified and lexically retrieved. Any additional planning introduced by the contrast manipulation could in principle be postponed until after production onset. Under a hierarchical view (Dell & O’Seaghdha, Reference Dell and O’Seaghdha1992; Ferreira & Dell, Reference Ferreira and Dell2000; Garrett, Reference Garrett and Bower1975), the order of planning is syntactically determined. If planning has a phrasal scope that determines the order in which nouns are planned (but not necessarily the timing), we would expect no difference across contrast conditions. This is, however, not what we found. Contrast modulated attention allocation to a non-sentence initial noun referent before production onset. This is evidence that the pre-planning demands obligated by the language production system can be determined by semantic features of the message. This is in line with Konopka and Meyer (Reference Konopka and Meyer2014), who proposed a horse-race process in which, on the semantic level, both a relational or non-relational route are available to guide planning.
The convergence of results across spoken and written production reinforces the view that semantic structure can independently shape early stages of language production. Our central findings – that semantic contrast influences the scope of pre-utterance planning – were replicated across both modalities. We believe, therefore, that the observed effects reflect a modality-general planning mechanism, operating at the level of message formulation or conceptual encoding, rather than modality-specific articulation or motor execution. While writing introduces variability in typing fluency and error correction, these differences are unlikely to affect the conceptual planning processes that drive gaze allocation and referent access prior to output (at least in the context of our experiment, but for an alternative view, see Rønneberg et al., Reference Rønneberg, Torrance, Uppstad and Johansson2022).
Our overall conclusion is consistent with three different ways of understanding the role of syntax in determining obligatory planning scope in phrase (and presumably also sentence) production. In, we think, all previous studies that have argued that planning must scope over the initial verb-argument NP, dependencies within the semantics of the intended message provide a potential alternative explanation. Minimally, we have demonstrated that semantic relationships contribute to planning scope even when syntactic structure – understood in terms of Universal Dependency Grammar or similar formalisms that have been assumed in previous research was held constant. Under Dependency Grammar, syntactic structure was constant across the contrast conditions in our study. Under a Generative Grammar analysis and for other syntacto-semantic formalisms that explicitly encode information that is interpreted semantically, that would not be the case. An alternative framing of our findings, therefore, is that the structures that determine planning scope are not captured by a strongly meaning-independent parse of the target utterance structure.
Following from this, there are two stronger interpretations that our findings are consistent with, though do not provide direct support for; both of which represent worthwhile targets for future research. First, it is possible that the language production system makes use of meaning-independent syntactic representations but that these are not implicated in determining planning scope. Second, and most strongly, it might be that representations of syntax (as distinct from syntacto-semantics) play no role in planning spoken or written production. These positions are consistent with recent arguments against abstract representations of syntax playing a role in language production (Nielsen & Christiansen, Reference Nielsen and Christiansen2025)Footnote 12. Also, these interpretations are consistent with various forms of construction grammar which assume that speakers (and writers) build mental representations that do not separate semantic and syntax representations (see Croft & Cruse, Reference Croft and Cruse2004; Fried & Nikiforidou, Reference Fried and Nikiforidou2025) and large language models that do not represent syntax at all (see Mahowald et al., Reference Mahowald, Ivanova, Blank, Kanwisher, Tenenbaum and Fedorenko2024; Piantadosi, Reference Piantadosi, Gibson and Poliak2024; Ramscar, Reference Ramscar2021).
Finally, we acknowledge two potential confounding factors raised by reviewers of a previous version of this article. First, our contrast manipulation is associated with prosodic variations. In English, contrast can be marked prosodically (Selkirk, Reference Selkirk and Godsmith1995)Footnote 13. Although, in the written modality, it was not possible to use prosody to convey referential contrast, participants might still have implicitly prepared the prosody of the utterance. Therefore, our findings could in principle be the result of a need to encode surface-level phonological representations (Fuchs et al., Reference Fuchs, Petrone, Krivokapić and Hoole2013; Fuchs & Krivokapić, Reference Fuchs and Krivokapić2016). We believe that it is relatively unlikely that the effects of semantic dependency – similar to the syntactic planning-scope effects we cited in the introductionFootnote 14 – were entirely mediated by prosody. To rule out a phonological interpretation, future research would need to assess to what extent planning-scope effects can be reproduced in contexts where phonological/prosodical planning was experimentally controlled; for example, by using articulatory suppression (repeatedly saying, the, the, e.g. Richardson & Baddeley, Reference Richardson and Baddeley1975) while preparing and executing utterances in writing.
Second, our task conditions minimised syntactic variability, including the use of repeated phrase structures and a focus on phrase planning rather than full sentence production. Specifically, our design used a preview/target structure in which the syntactic frame of the target phrase was highly predictable, and in the vast majority of trials (94.4%), participants reused the same syntactic form as used in the preview trial. Structural repetition is likely to have minimised the need for active syntactic planning, and may not reflect naturalistic language production. This was, however, intentional: by reducing syntactic variability, we were able to examine whether semantic structure, in the absence of syntactic uncertainty, influences planning scope. Specifically, we tested whether semantics is sufficient to drive pre-planning when syntax is controlled.
In summary, we report evidence that demonstrates, for the first time, variation in whether or not a written or spoken phrase is pre-planned beyond the first noun just as a result of semantic dependency, in a context where all other features of the target production (with the exception of prosody in the spoken modality) are held constant. We found that the semantic organisation of the phrase affects pre-planning beyond the first noun. While prior study proposed that syntactic factors constrain the scope of pre-planning (e.g. Lee et al., Reference Lee, Brown-Schmidt and Watson2013; Wagner et al., Reference Wagner, Jescheniak and Schriefers2010; Wheeldon et al., Reference Wheeldon, Ohlson, Ashby and Gator2013), our findings suggest that semantic factors such as contrastive focus can drive early referent access, even when syntactic and lexical structure are controlled.
Open Practices Statement
The data and materials for all experiments are available at https://osf.io/wst3a (Roeser et al., Reference Roeser, Torrance and Baguley2022). The experiment was not preregistered.
Appendix A
Picture-naming data
Picture naming norms were taken from the International Picture Naming Project (e.g. Bates et al., Reference Bates, D’Amico, Jacobsen, Székely, Andonova, Devescovi, Herron, Lu, Pechmann and Pléh2003).
Table A1. Picture-naming data
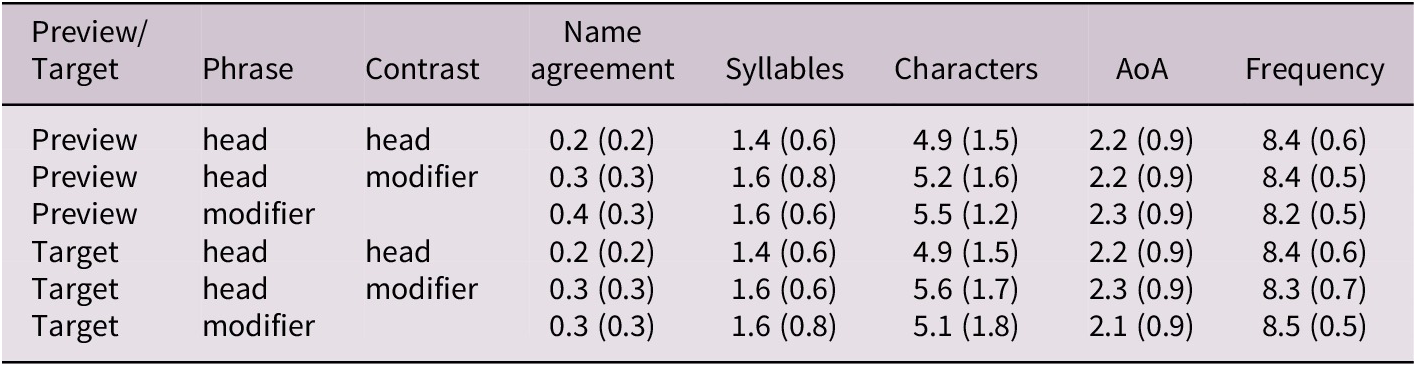
Note. AoA = Age of acquisition based on MacArthur Communicative Development Inventories (Fenson et al., Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994); Name agreement = 0 indicates perfect agreement; values
 $ > $
0 indicate lower agreement (see Snodgrass & Vanderwart, Reference Snodgrass and Vanderwart1980); Frequency = log frequency based on British National Corpus. Means and standard deviations (in parentheses) by ‘Phrase’ indicating the location of the picture in the phrase, and ‘Contrast’ indicating the phrase location of the contrasting picture.
$ > $
0 indicate lower agreement (see Snodgrass & Vanderwart, Reference Snodgrass and Vanderwart1980); Frequency = log frequency based on British National Corpus. Means and standard deviations (in parentheses) by ‘Phrase’ indicating the location of the picture in the phrase, and ‘Contrast’ indicating the phrase location of the contrasting picture.
Appendix B
Fixed-effects summary of modifier-choice data
Table B1. Modifier choice

Note. Fixed effects for proportion of trials in which participants produced a postnominal modifier (‘The king with the magnet’) instead of a prenominal modifier (‘The king’s magnet’). Shown are main effects and interactions on logit scale. 95% PIs are shown in brackets.
Abbreviations: BF = evidence in favour of the alternative hypothesis over the null hypothesis (Bayes Factor); PI = probability interval; ‘:’ = interaction.
Appendix C
Eye data of target trials
For an overview of the eye-movement data, we modelled the time-course of eye-movement. The model included gaze data to the four AOIs of the preview (for the preview trials see Appendix E) and target trials that correspond to the two nouns in each target utterance. Data from pictures that were not part of either the preview or target utterance were not included in the analysis as only a negligible proportion of eye samples were on either of these four AOIs (all means = .02, SEs = .02).
The proportion of eye samples was converted to empirical logits and modelled in Bayesian mixed-effects models with three orthogonal polynomials for the time-course predictor (see Barr, Reference Barr2008; Mirman et al., Reference Mirman, Dixon and Magnuson2008) and main effects and interactions of AOIs, preview/target, Modifier position and Contrast. The time axis was scaled between 0 (stimulus onset) and 1 (response onset) to account for by-trial differences in the time-to-onset duration.
The modelled time-course data can be found in Figure C1. As can be seen, looks to the referents of the preview utterance were rare (referent of the modifier noun, e.g. ‘king’/‘sailor’: mean = .06, SE = .03; head-noun referent, e.g. ‘magnet’/‘butter’: mean = .1, SE = .04) and mainly preceded the gaze switch to the referents of the target utterance. Thus, these looks are mainly an artifact of attention re-allocation from preview to target referents.
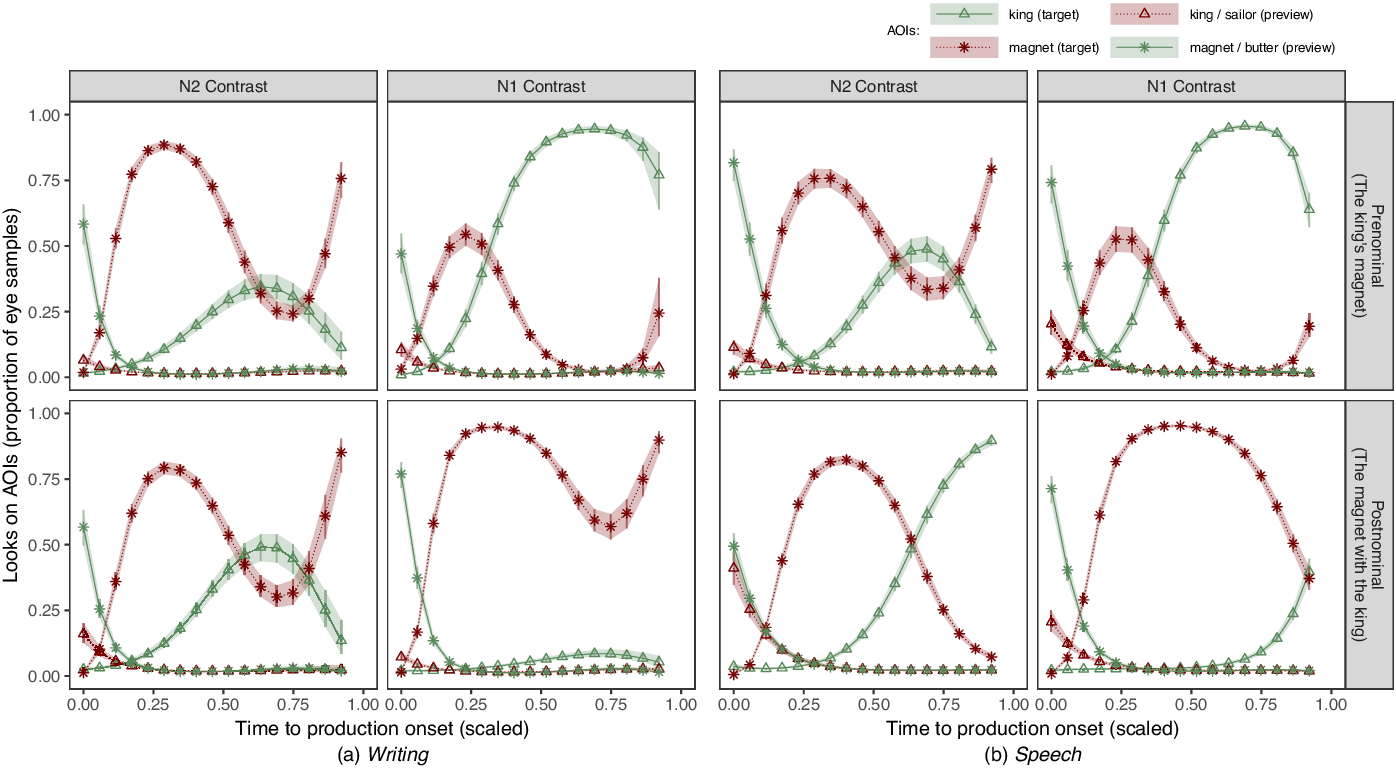
Figure C1. Gaze time-course of target trial. Displayed are the proportion of eye samples to the AOIs corresponding to noun referents in the target and preview trials (as indicated in legend keys) before production onset. Lines represent population estimate and error bars show 95% PIs.
Appendix D
Fixed-effects summary of eye data and onset latency
Table D1. Fixed effects for eye and response-latency data

Note. Estimates are shown for all main effects and interactions. Time-to-gaze-divergence and onset latency are shown on the log scale and the probability of pre-onset gaze divergence on the logit scale. 95% PIs are shown in brackets.
Abbreviations: BF = evidence in favour of the alternative hypothesis over the null hypothesis (Bayes Factor); PI = probability interval; ‘:’ = interaction.
Appendix E
Results of preview trials
This section summarises the results for preview trials extracted from the models reported in the main text. Figure E1a shows the estimates of the posterior parameter values for the time of gaze shift from N1 to N2 in the written session. Evidence for scope effects was negligible (BF
 $ < $
0.06). Similarly, the probability of gaze shift to occur before production onset showed negligible evidence for a contrast effect (BF
$ < $
0.06). Similarly, the probability of gaze shift to occur before production onset showed negligible evidence for a contrast effect (BF
 $ < $
0.6). The estimated probability of gaze-shift was similar in the N2 contrast condition both modifier types (prenominal: N1 contrast = .44, 95% PI [.34, .54], N2 contrast = .52, 95% PI [.41, .62]; postnominal: N1 contrast = .52, 95% PI [.42, .63], N2 contrast = .5, 95% PI [.4, .61]). The inferred parameter values for the response-onset latency can be found in Figure E1b. Evidence for contrast effects was negligible (BF
$ < $
0.6). The estimated probability of gaze-shift was similar in the N2 contrast condition both modifier types (prenominal: N1 contrast = .44, 95% PI [.34, .54], N2 contrast = .52, 95% PI [.41, .62]; postnominal: N1 contrast = .52, 95% PI [.42, .63], N2 contrast = .5, 95% PI [.4, .61]). The inferred parameter values for the response-onset latency can be found in Figure E1b. Evidence for contrast effects was negligible (BF
 $ < $
0.2).
$ < $
0.2).

Figure E1. Written production. Estimates from full-factorial Modality × preview/target × Modifier position × Contrast linear mixed-effects models. Error bars represent 95% PIs.
For the spoken responses, the posterior parameter values for the time of gaze shift from N1 to N2 relative to the production onset can be found in Figure E2a. Evidence for noun contrast effects was negligible (BF
 $ < $
0.08). Although we found negligible evidence for a noun contrast effect in the gaze-shift timing data, we observed evidence for a larger probability for gaze shift to happen before production onset under N2 contrast in phrases with postnominal modification but not for phrases with prenominal modification (prenominal: N1 contrast = .45, 95% PI [.33, .58], N2 contrast = .5, 95% PI [.36, .63], BF
$ < $
0.08). Although we found negligible evidence for a noun contrast effect in the gaze-shift timing data, we observed evidence for a larger probability for gaze shift to happen before production onset under N2 contrast in phrases with postnominal modification but not for phrases with prenominal modification (prenominal: N1 contrast = .45, 95% PI [.33, .58], N2 contrast = .5, 95% PI [.36, .63], BF
 $ < $
0.4; postnominal: N1 contrast = .65, 95% PI [.56, .74], N2 contrast = .78, 95% PI [.71, .85], BF = 6.78). The inferred parameter values for the onset latency can be found in Figure E2b. Evidence for noun-contrast effects was negligible (BF
$ < $
0.4; postnominal: N1 contrast = .65, 95% PI [.56, .74], N2 contrast = .78, 95% PI [.71, .85], BF = 6.78). The inferred parameter values for the onset latency can be found in Figure E2b. Evidence for noun-contrast effects was negligible (BF
 $ < $
0.09).
$ < $
0.09).

Figure E2. Spoken production. Mean gaze shift and production onset latencies. Error bars represent 95% PIs. Parameter estimates from full-factorial Modality × preview/target × Modifier-position × Contrast linear mixed-effects models.
The time-course data, modelled as described in Appendix C, are shown in Figure E3. As can be seen, looks to the referents of target-trial utterances that followed the preview were rare (referent of the modifier noun, e.g. ‘king’: mean = .03, SE = .02; head-noun referent, e.g. ‘magnet’: mean = .04, SE = .03). These were non-different from looks to any of the other four AOIs (all means = .02, SEs = .02).

Figure E3. Gaze time-course of preview trial. Displayed are the proportion of eye samples to the AOIs corresponding to noun referents in the target and preview trials (as indicated in legend keys) before production onset. Lines represent population estimate and error bars show 95% PIs.





















 Open access
Open access