



Introduction
All forms of language comprehension are complex and difficult, and it is generally agreed that people make use of prediction to help them succeed (Huettig, Reference Huettig2015; Kuperberg & Jaeger, Reference Kuperberg and Jaeger2016; Pickering & Gambi, Reference Pickering and Gambi2018). Simultaneous interpreting is particularly difficult, because interpreters have to attend to and produce utterances concurrently in two different languages. Therefore it is unsurprising that most accounts assume that simultaneous interpreters also make use of prediction during comprehension (Gerver, Reference Gerver and Brislin1976; Moser, Reference Moser, Gerver and Sinaiko1978; Seleskovitch, Reference Seleskovitch, Seleskovitch and Lederer1984). But although efforts have been made to determine when and what interpreters predict, and on what basis they make these predictions, there is no generally accepted theory of how interpreters predict.
To develop such a theory, we must take into account not only the aspects of simultaneous interpreting that occur in language processing by bilinguals but also those aspects that are unique to simultaneous interpreting. In particular, we must consider both the general nature of prediction in language comprehension and how such prediction is affected by the specific properties of simultaneous interpreting: the use of a non-native language, cross-language activation, and of course the cognitive load associated with concurrent comprehension and production.
We thus begin by briefly defining what we mean by prediction, before providing a short overview of the advantage of prediction in simultaneous interpreting and a review of traditional accounts of such prediction. We then consider accounts and evidence of prediction during comprehension in monolinguals and bilinguals and propose that comprehenders use the production mechanism to predict. We move on to look at the different aspects of simultaneous interpreting which may affect prediction before proposing a model of how interpreters predict during simultaneous interpreting.
What do we mean by prediction?
Language comprehension is very rapid (e.g., Marslen-Wilson, Reference Marslen-Wilson1973; Swinney, Reference Swinney1979; Tanenhaus, Spivey-Knowlton, Eberhard & Sedivy, Reference Tanenhaus, Spivey-Knowlton, Eberhard and Sedivy1995). Comprehenders incrementally interpret what they hear (or read) by integrating each new word into its prior context. But they do more than this – they regularly predict what they believe they are about to hear (Pickering & Gambi, Reference Pickering and Gambi2018). By prediction, we mean pre-activation of any aspect of an utterance (i.e., meaning, syntax or sound) that occurs before the comprehender hears (or reads) that utterance. For example, studies have used neuroscientific and eye-tracking measures to demonstrate prediction of meaning (e.g., Altmann & Kamide, Reference Altmann and Kamide1999; Grisoni, McCormick Miller & Pulvermüller, Reference Grisoni, McCormick Miller and Pulvermüller2017; Mani & Huettig, Reference Mani and Huettig2012; Rommers, Meyer, Praamstra & Huettig, Reference Rommers, Meyer, Praamstra and Huettig2013), syntax (e.g., Van Berkum, Brown, Zwitserlood, Kooijman & Hagoort, Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005; Otten, Nieuwland & Van Berkum, Reference Otten, Nieuwland and Van Berkum2007; Dikker, Rabagliati & Pylkkänen, Reference Dikker, Rabagliati and Pylkkänen2009), and form (DeLong, Urbach & Kutas, Reference DeLong, Urbach and Kutas2005; Ito, Corley, Pickering, Martin & Nieuwland, Reference Ito, Corley, Pickering, Martin and Nieuwland2016; Lazlo & Federmeier, Reference Lazlo and Federmeier2009).
Recent research has also demonstrated that prediction may not always take place (Huettig & Guerra, Reference Huettig and Guerra2019), that a specific word may not always be predicted (Frisson, Harvey & Staub, Reference Frisson, Harvey and Staub2017), that there may be individual differences in predictive processing (Huettig & Janse, Reference Huettig and Janse2016) and that some paradigms used to demonstrate prediction do not consistently show effects (Nieuwland, Politzer-Ahles, Heyselaar, Segaert, Darley, Kazanina, Von Grebmer Zu Wolfsthurn, Bartolozzi, Kogan, Ito, Mézière, Barr, Rousselet, Ferguson, Busch-Moreno, Fu, Tuomainen, Kulakova, Husband, Donaldson, Kohút, Rueschemeyer & Huettig, Reference Nieuwland, Politzer-Ahles, Heyselaar, Segaert, Darley, Kazanina, Von Grebmer Zu Wolfsthurn, Bartolozzi, Kogan, Ito, Mézière, Barr, Rousselet, Ferguson, Busch-Moreno, Fu, Tuomainen, Kulakova E, Husband, Donaldson, Kohút, Rueschemeyer and Huettig2017). Language comprehension does not appear to be dependent upon prediction, but the extensive evidence for prediction suggests that it is important to much comprehension.
The advantage of prediction in simultaneous interpreting
Much evidence for prediction is comparatively recent, but the potential value of prediction for simultaneous interpreting has been apparent for a long time, and so it is not surprising that traditional accounts have also assumed a role for prediction (Gerver, Longley, Long & Lambert, Reference Gerver, Longley, Long and Lambert1984; Moser-Mercer, Frauenfelder, Casado & Künzli, Reference Moser-Mercer, Frauenfelder, Casado, Künzli, Dimitrova and Hyltenstam2000; Setton, Reference Setton, Gerzymisch-Arbogast and Van Dam2005). One reason for this is that interpreters produce utterances about 70% of the time that they are listening (Chernov, Reference Chernov, Lambert and Moser-Mercer1994). They thus need to keep pace with the speaker while planning and producing their own utterances. Prediction could allow interpreters to maintain a shorter lag (Gile, Reference Gile2009) between input and output, reducing demands on memory and allowing them to focus attention on their own production (De Groot, Reference De Groot2011) and increase self-monitoring (Chernov, Reference Chernov, Lambert and Moser-Mercer1994).
Another reason to make predictions during comprehension relates to differences in word order between the source and the target languages (Setton, Reference Setton1999; Wilss, Reference Wilss, Gerver and Sinaiko1978). Without prediction, interpreters would be unable to produce the appropriate translation of a phrase in the target language before encountering the relevant phrase in the source language. If a German-English interpreter encountered a subordinate clause with subject-object-verb (SOV) word order and interpreted it into SVO word order, then she could not produce the object in English until she heard the verb, even though the object may be preceded by a long adjectival phrase. But if she predicted the German verb, she could produce its English translation and then produce the translation of the object without delay (Seeber, Reference Seeber2011). If the interpreter were reasonably confident, then acting on the prediction would be advantageous, as it would allow her to reduce the demands on memory (the interpreter would be able to maintain a shorter lag).
Of course, simultaneous interpreters could make inaccurate predictions, and suppressing or revising these could require additional processing. Federmeier, Kutas and Schul (Reference Federmeier, Kutas and Schul2010) found evidence of processing effects (an ERP deflection) of plausible yet incorrectly predicted words in younger adults and some older adults, which might suggest additional processing. In a similar way, incorrect predictions may induce additional processing during simultaneous interpreting, as interpreters would not only have to revise their prediction, but might also have to revise their planned utterance.
However, it is not clear that erroneous predictions are costly. Frisson et al. (Reference Frisson, Harvey and Staub2017) compared the effects of predicting the wrong word with making no prediction at all and found no cost of incorrect prediction. Moreover, prediction may actually facilitate the processing of words that are semantically related to the predictable word (Frisson et al., Reference Frisson, Harvey and Staub2017; Staub, Grant, Astheimer & Cohen, Reference Staub, Grant, Astheimer and Cohen2015). The potential additional processing required following incorrect predictions may also lead to a processing advantage in the longer term: Dell and Chang (Reference Dell and Chang2014) proposed that incorrect predictions may lead to long-term changes in the comprehension system, as it could learn from the difference between the predicted and the actual utterance, thus reducing future errors in similar situations. Given the benefits of prediction in comprehension during simultaneous interpreting (Chernov, Reference Chernov, Lambert and Moser-Mercer1994, De Groot, Reference De Groot2011; Gile, Reference Gile2009), the lack of clear evidence of a processing cost for incorrect predictions (Federmeier et al., Reference Federmeier, Kutas and Schul2010; Frisson et al., Reference Frisson, Harvey and Staub2017; Staub et al., Reference Staub, Grant, Astheimer and Cohen2015), and the benefits of error-based learning (Dell & Chang, Reference Dell and Chang2014), it seems likely that the ability to make predictions and decide whether or not to act on them constitutes a processing advantage rather than disadvantage for simultaneous interpreters.
Traditional accounts of prediction in simultaneous interpreting
Prediction is an optional step in one of the first simultaneous interpreting process models (Moser, Reference Moser, Gerver and Sinaiko1978), and Setton (Reference Setton, Gerzymisch-Arbogast and Van Dam2005) suggested that the ability to predict is a prerequisite for being a successful simultaneous interpreter. Moreover, Gerver et al. (Reference Gerver, Longley, Long and Lambert1984) found that students performed better in interpretation exams if they were more likely to fill in blanked out words correctly in a passage of text. In other words, the ability to use context to determine probable words was positively related to interpreting performance (but note that students saw the entire passage at once). Seleskovitch (Reference Seleskovitch, Seleskovitch and Lederer1984) posited an even more central role for prediction, arguing that interpreters engage in ‘freewheeling anticipation’; that is, they predict constantly during comprehension and update their predictions regularly based on whether what the speaker says fits with them.
Strikingly, these accounts do not consider the locus of prediction. They do not propose whether prediction takes place in the source language (being comprehended) or in the target language (being produced). Does the comprehender predict the upcoming word in the source language or its translation in the target language (or both)?
Predictive production occurs when a simultaneous interpreter produces the translated utterance in the target language before it has been uttered in the source language (Seeber, Reference Seeber2001; Van Besien, Reference Van Besien1999; Wilss, Reference Wilss, Gerver and Sinaiko1978). It is viewed as a strategy used by interpreters working with (mis-matched) language pairs that involve a great deal of syntactic asymmetry (Van Besien, Reference Van Besien1999).
In a recent study, Hodzik and Williams (Reference Hodzik and Williams2017) had simultaneous interpreters and (non-interpreter) bilinguals simultaneously interpret German verb-final sentences into English. The verbs followed either a high or low constraint context, and were therefore predictable or not predictable. They found that the English verb was produced more quickly after the German verb in high constraint contexts. Moreover, participants occasionally produced the verb before they heard it (4% of interpreted sentences for interpreters and 2.4% for bilinguals), and almost all of such predictive productions (around 90%) followed the high constraint contexts. This demonstrates that prediction takes place during simultaneous interpreting. However, given that interpreters lag a few seconds behind the original speaker, and that lag may vary, there may also be instances where interpreters predict but do not predictively produce a sentence constituent. In sum, theoretical accounts and a few empirical studies suggest that prediction is part of the simultaneous interpreting process.
Prediction during comprehension of a native language
More compelling evidence of prediction during comprehension comes from the psycholinguistics literature. The most convincing evidence of prediction taking place at semantic, syntactic, and phonological levels comes from event-related (brain) potential (ERP) and eye-tracking studies using monolingual participants (see Pickering & Gambi, Reference Pickering and Gambi2018). Evidence of meaning-based prediction comes from Altmann and Kamide (Reference Altmann and Kamide1999), who presented participants with scenes containing an agent (e.g., a boy) and four objects in an eye-tracking study. Participants heard a sentence with a verb that was semantically linked to either only one or all four of the objects in the display, such as “The boy will eat the…” or “The boy will move the…”, where the objects were a cake, a train set, a toy car, and a balloon. In the “eat” condition, eye movements to the cake began before noun onset, whereas in the “move” condition they did not, indicating that information from the verb was used to predict the semantic nature of the noun. In an ERP study, Grisoni et al. (Reference Grisoni, McCormick Miller and Pulvermüller2017) showed that participants can also make meaning-based predictions in the absence of a supportive visual context. They had participants listen to highly constraining sentences related to either the hands or the face (e.g., “I take a pen and I… write”) and showed that participants pre-activated the corresponding parts of the motor cortex depending on the verb.
Van Berkum et al. (Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005) found evidence for syntactic prediction. They had participants listen to highly constraining texts in Dutch that ended in a predictable or less predictable noun preceded by an adjective agreeing in gender with the noun, for example: “The burglar had no trouble locating the secret family safe. Of course, it was situated behind… a big painting (een groot Schilderij)/a big bookcase (ein grote Boekenkast).” ERPs showed a positive deflection at the adjective agreeing in gender with the less predictable noun, indicating that participants had predicted syntactic features of the upcoming noun (see also Otten et al., Reference Otten, Nieuwland and Van Berkum2007 and Otten & Van Berkum, Reference Otten and Van Berkum2008). In a similar study (in Spanish), Wicha, Moreno and Kutas (Reference Wicha, Moreno and Kutas2004) measured ERP effects due to articles agreeing in gender (or not) with the predictable noun and found evidence for prediction of syntactic features of upcoming predictable nouns.
Meanwhile, DeLong et al. (Reference DeLong, Urbach and Kutas2005) found evidence for prediction of phonology. They had participants read sentences ending in higher or lower cloze nouns which began with either a consonant or a vowel and thus required the article to be a or an, for example, “The day was breezy so the boy went outside to fly a kite/an airplane in the park”. The N400 amplitude on the article was negatively correlated with the cloze value of the corresponding noun (here kite had a higher cloze than airplane), suggesting that phonological predictions can be formulated before noun onset. It should be noted that a multi-lab study has failed to replicate the article-elicited N400 effect demonstrated in this experiment (Nieuwland et al., Reference Nieuwland, Politzer-Ahles, Heyselaar, Segaert, Darley, Kazanina, Von Grebmer Zu Wolfsthurn, Bartolozzi, Kogan, Ito, Mézière, Barr, Rousselet, Ferguson, Busch-Moreno, Fu, Tuomainen, Kulakova E, Husband, Donaldson, Kohút, Rueschemeyer and Huettig2017).
Ito et al. (Reference Ito, Corley, Pickering, Martin and Nieuwland2016) used a different ERP paradigm to provide evidence that both form and meaning may be predicted. They had participants read highly constraining sentences (e.g., “The student is going to the library to borrow a…”) which were completed either with a predictable word (book), its phonological neighbour (hook), its semantic neighbour (page) or an unrelated word (sofa). When words were presented every 500 ms, predictable nouns and semantically related nouns elicited a reduced N400 effect compared to the unrelated word, indicating semantic prediction. When words were presented every 700 ms, the reduced N400 effect was also found for phonologically related words, indicating prediction of sound when participants have more time. In an eye-tracking experiment (described below) Ito, Pickering and Corley (Reference Ito, Pickering and Corley2018) also found evidence of prediction of phonological form in monolinguals. Taken together, these findings suggest that people can pre-activate phonological features of words.
Prediction during bilinguals’ comprehension of L2
The studies above consider prediction during comprehension of a native language. However, simultaneous interpreters typically comprehend in a non-native language (and produce in their native language). Some evidence suggests that non-native listeners predict less than native speakers of a language. In a study based on Delong et al. (Reference DeLong, Urbach and Kutas2005), Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) compared English monolingual with Spanish-English late bilingual readers. Participants read English sentences which finished with either a predictable or a less predictable noun, which was either vowel or consonant-initial, for example: “He was very tired so he sat on a chair/an armchair”. Both groups showed an N400 effect on the noun itself, showing that both monolinguals and bilinguals predict meaning. Monolinguals also showed a greater N400 amplitude for articles that were incompatible with a higher cloze noun, whereas bilinguals reading in their L2 did not, suggesting that L2 listeners do not always predict phonology.
Similarly, Ito et al. (Reference Ito, Pickering and Corley2018) investigated the time-course of phonological prediction in English monolinguals and Japanese–English bilinguals. Participants heard sentences which contained a highly predictable word (e.g., “The tourists expected rain when the sun went behind the cloud”) while viewing a display containing an object depicting the predictable word (a cloud), an object whose English name was phonologically related to this word (a clown), an object whose Japanese name was phonologically related to the Japanese translation of this word (a bear, whose Japanese name kuma is related to kumo, meaning cloud), or an unrelated object. Both participant groups tended to look at the image of the predictable word, again demonstrating prediction of meaning by non-native speakers. However, English monolinguals also tended to look predictively towards objects whose phonological form in English was related to the predictable word, whereas Japanese speakers did not.
Nonetheless, it is possible that prediction in non-native speakers is more similar to prediction in native speakers when the two languages are closely related. Foucart, Martin, Moreno and Costa (Reference Foucart, Martin, Moreno and Costa2014) found evidence of syntactic prediction by French–Spanish late bilinguals reading in Spanish. Three groups of participants (Spanish monolinguals, L1 Spanish–L2 Catalan early bilinguals and L1 French–L2 Spanish late bilinguals) read Spanish sentences which concluded with either a highly predictable or a less predictable noun differing in gender from the highly predictable noun, for example “El pirata tenia el mapa secreto, pero nunca encontro el tesero (masc)/la gruta (fem) que buscaba” (translation: “The pirate had the secret map, but he never found the treasure/the cave he was looking for”). The critical nouns had the same gender in French and Spanish (the Catalan–Spanish group was included to see whether bilingualism affected prediction when listening to L1). An increased N400 amplitude was elicited at the less predictable article and noun in all three participant groups. The effect at the article suggests that where their two languages are similar (such as French and Spanish), late bilinguals can make syntactic predictions as well as semantic predictions in their non-native language, just as monolinguals do.
These studies show that bilinguals listening in their L2 may predict semantic content (Ito et al., Reference Ito, Pickering and Corley2018, Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) and, where their two languages are similar, syntactic content (Foucart et al., Reference Foucart, Martin, Moreno and Costa2014), just as monolinguals do. However, they may not predict phonology (Ito et al., Reference Ito, Pickering and Corley2018; Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013).
Prediction-by-production in a native language
There are different accounts of prediction. Many of these accounts (e.g., Kukona, Fang, Aicher, Chen & Magnuson, Reference Kukona, Fang, Aicher, Chen and Magnuson2011; Metusalem, Kutas, Urbach, Hare, McRae & Elman, Reference Metusalem, Kutas, Urbach, Hare, McRae and Elman2012) assume the pre-activation of words or concepts that are primed by the linguistic context but need not reflect what is likely to occur next. We, however, are interested in how simultaneous interpreters may form directed predictions – that is, predictions that are likely to reflect what the speaker will say next so that they can plan their translation of the utterance.
Other accounts assume that comprehenders tend to be rather more accurate in their predictions. Kuperberg (Reference Kuperberg2016) proposed that they actively generate predictions based on top-down hypotheses, and that these hypotheses are updated following prediction errors. She proposed that either semantic or syntactic information is prioritized, depending on which type of cue appears to be most reliable. Huettig (Reference Huettig2015) suggested that predictive processing is too complex to be ascribed to just one mechanism, and that, depending on the situational context, different mechanisms may be combined to different extents to generate predictions (for example, event knowledge may be combined with use of the production mechanism) but only in certain scenarios. These accounts suggest that comprehenders may predict what the speaker is likely to say, but may not.
In contrast, we argue that prediction during comprehension is primarily and routinely a consequence of what we term prediction-by-production – the comprehender uses her production mechanism to predict sequentially, roughly as though she were completing the speaker's utterance herself, but making adjustments for differences between herself and the speaker. In this section we explain the basis for this theory, as proposed in Pickering and Garrod (Reference Pickering and Garrod2007, Reference Pickering and Garrod2013) and Pickering and Gambi (Reference Pickering and Gambi2018).
According to this theory, prediction during comprehension exhibits the same stages as speech planning during production. In accord with most accounts of production, we assume that speakers first construct a message that they wish to convey, then convert that representation into one or more syntactic representations, and then construct sound-based representations before they articulate (e.g., Bock & Levelt, Reference Bock, Levelt and Gernsbacher1994). As part of this sequential process, they access lexical items, which have components concerned with meaning, syntax, and sound (Levelt, Roelofs & Meyer, Reference Levelt, Roelofs and Meyer1999); see Pickering and Gambi (Reference Pickering and Gambi2018) for discussion in relation to prediction.
We propose that, in order to predict, the comprehender uses her production mechanism to work through the same stages, in the same order: from meaning, to syntax, to sound, but without articulating. In other words, the comprehender changes comprehension representations into covert production representations. This allows her to predict what the speaker is about to say in the same way that she would plan her own upcoming utterance (making adjustments for differences between herself and the speaker).
Several studies provide indirect evidence of the involvement of the production mechanism in prediction. Adank (Reference Adank2012) showed the activation of production-related brain areas during comprehension (which of course shows just that the production system is used during comprehension). Adank, Hagoort and Bekkering (Reference Adank, Hagoort and Bekkering2010) found that imitation aids comprehension, and Drake and Corley (Reference Drake and Corley2015) found that predictive tongue movements are made during comprehension. In addition, Mani and Huettig (Reference Mani and Huettig2012) showed that children's prediction skills were significantly correlated with their production skills rather than with their comprehension skills.
Strong evidence of the effect of production on prediction comes from a study by Martin, Branzi and Bar (Reference Martin, Branzi and Bar2018). They had participants read highly constrained Spanish sentences that concluded in a predictable or less predictable noun preceded by a gender-marked article. Participants engaged in either a non-verbal or verbal secondary task (“syllable listening”, “tongue tapping” or “syllable production”). N400 effects at the article (but not at the noun) were reduced for the syllable production group (who produced /ta/ as they read) as compared to the two other groups, suggesting that occupying the production mechanism may limit prediction. Together, these findings (Adank, Reference Adank2012; Adank et al., Reference Adank, Hagoort and Bekkering2010; Drake & Corley, Reference Drake and Corley2015; Mani & Huettig, Reference Mani and Huettig2012; Martin et al., Reference Martin, Branzi and Bar2018) support a theory according to which people make semantic, syntactic and phonological predictions using the production mechanism during comprehension.
Prediction-by-production in bilinguals listening to their L2
Now consider how prediction-by-production might take place across languages in bilinguals (for now, ignoring whether they are trained interpreters). De Bot's (Reference De Bot1992) theory of bilingual language production assumes that production mechanisms are essentially the same for native and non-native languages, and that bilinguals make use of two essentially equivalent production systems (formulators), choosing the language of production after conceptualising their utterance.
However, this is a simplification because there is good evidence for some sharing between languages, both on a syntactic level (Hartsuiker, Pickering & Veltkamp, Reference Hartsuiker, Pickering and Veltkamp2004) and a lexical level (Costa, Caramazza & Sebastian-Galles, Reference Costa, Caramazza and Sebastian-Galles2000; Jared & Kroll, Reference Jared and Kroll2001). Sharing between languages during production has implications for our model of prediction-by-production in bilinguals listening in their L2. If both languages are activated during production, then both could be activated during prediction-by-production, meaning that predictions could be made in either or both of a bilingual's languages. But in Ito et al. (Reference Ito, Pickering and Corley2018), Japanese native speakers did not look towards either the Japanese phonological competitor or the English phonological competitor. It is possible that linguistic distance between the two languages prevented cross-language activation (or the study may have failed to detect small effects).
We have seen that both monolinguals and bilinguals predict (Altmann & Kamide, Reference Altmann and Kamide1999; Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005). Further, we have seen that while predictions may sometimes be less complete in bilinguals listening in their L2 (Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013; Ito et al., Reference Ito, Pickering and Corley2018), L1 and L2 listeners are more likely to show similar patterns of prediction when the two languages are more closely related (Foucart et al., Reference Foucart, Martin, Moreno and Costa2014). We have reviewed evidence that such prediction involves the production mechanism, and that production mechanisms are similar for native and non-native languages. Based on this evidence, we posit that bilinguals also use the production mechanism to predict, working through the same stages and in the same order: from meaning, to syntax, to sound.
Cognitive load
We now consider whether such predictions take place under increased cognitive load, such as may be present in simultaneous interpreting. Simultaneous interpreting is more complex than monolingual comprehension, not just because it involves comprehension in a bilingual's L2 (most interpreters working in international organisations and institutions in Europe produce in their L1), but also because it requires multi-tasking. As noted above, predictive processing may not be as complete in L2 comprehension as in L1 comprehension. This could be because L2 comprehension is associated with greater cognitive load as it requires more attentional control (whereas L1 comprehension takes place with less effort) (Segalowitz & Hulstijn, Reference Segalowitz, Hulstijn, Kroll and De Groot2009), and cognitive resources are required for prediction (Ito, Corley & Pickering, Reference Ito, Corley and Pickering2017).
As evidence for this last point, Ito et al. (Reference Ito, Corley and Pickering2017) demonstrated that predictive eye movements require cognitive resources in a study involving L1 and L2 speakers of English. As in Altmann and Kamide (Reference Altmann and Kamide1999), participants viewed a visual display containing four objects and made predictive looks to the object semantically linked to the verb they heard. Both L1 and L2 speakers looked predictively towards critical objects. Importantly, predictive looks by both L1 and L2 speakers were delayed when they had to remember words (a cognitive load). This suggests that cognitive load slows down prediction similarly for L1 and L2 speakers.
Of course, simultaneous interpreting is more complex than listening in an L2. Simultaneous interpreters must comprehend, plan and articulate utterances at the same time. Producing a word can slow performance in a concurrent task (Ferreira & Pashler, Reference Ferreira and Pashler2002). Planning utterances is associated with greater cognitive load than speech monitoring and articulating (Boiteau, Malone, Peters & Almor, Reference Boiteau, Malone, Peters and Almor2014; Sjerps & Meyer, Reference Sjerps and Meyer2015). This concurrent speech planning and production load in simultaneous interpreting may reduce resources available for prediction during comprehension.
At the same time, production and comprehension are closely related during simultaneous interpreting – the interpreter produces the same content as the original speech at a typically short lag (though note that this ear-voice span does vary; Setton, Reference Setton1999). In other words, the tasks carried out during simultaneous interpreting are not unrelated load tasks. The same stream of meaning is being comprehended and produced. Further, the overlap between the content that is comprehended and produced may lead to automatic activation of syntactic structures and translation equivalents through cross-language activation. Additionally, if comprehension takes place more rapidly, the interpreter can focus more resources on production.
Most researchers assume that cross-language activation takes place even in one-language settings (Dijkstra, Grainger & van Heuven, Reference Dijkstra, Grainger and van Heuven1999; Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002; Marian & Spivey, Reference Marian and Spivey2003; Mercier, Pivneva & Titone, Reference Mercier, Pivneva and Titone2014; Thierry & Wu, Reference Thierry and Wu2007). There is some debate about this, and about whether such effects could be due to learning (see Costa, Pannunzi, Deco & Pickering, Reference Costa, Pannunzi, Deco and Pickering2017). However, there is no doubt that cross-language activation occurs when a bilingual uses both languages. For example, Hatzidaki, Branigan, and Pickering (Reference Hatzidaki, Branigan and Pickering2011) found evidence for cross-language activation of syntax in a two-language setting. Simultaneous interpreting is an example of a setting in which both languages are in constant, concurrent use. Cross-language activation could make cross-language predictions possible. Further, the automatic activation of the target language could reduce the cognitive load involved in speech planning and production.
Individual differences in processing speed and working memory may also affect predictive processing. Huettig and Janse (Reference Huettig and Janse2016) found that working memory and processing speed were positively correlated with predictive eye movements to predictable objects. Other factors which may influence predictive ability include age (older adults may not predict as much as younger adults; Federmeier et al., Reference Federmeier, Kutas and Schul2010), verbal fluency (speed in generating words in a specific semantic category; Federmeier, McLennan, Ochoa & Kutas, Reference Federmeier, McLennan, De Ochoa and Kutas2002), level of literacy (Mishra, Singh, Pandey & Huettig, Reference Mishra, Singh, Pandey and Huettig2012) and size of vocabulary (as assessed in young children; Mani & Huettig, Reference Mani and Huettig2012). We posit that the bilingual's level of automaticity in second-language processing may also affect predictive processing.
It is therefore possible that prediction by simultaneous interpreters is limited by cognitive load. However, it is likely that simultaneous interpreters will routinely make predictions given: the advantageous nature of prediction in simultaneous interpreting (Christoffels & De Groot, Reference Christoffels, De Groot, Kroll and De Groot2009); supportive cross-language activation; the likelihood that interpreters are individuals who have a high level of automaticity in their second-language processing; and the possibility that interpreters have above average verbal fluency and vocabulary size.
A model of prediction-by-production in simultaneous interpreting
We have reviewed evidence showing that comprehenders predict during comprehension and that the production system could be involved in the formulation of these predictions. Evidence from bilingual language processing suggests that although non-native speakers may not always form predictive representations to the same extent as native speakers (Ito et al., Reference Ito, Pickering and Corley2018; Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013), their predictive patterns may mirror those of native speakers (Ito et al., Reference Ito, Corley, Pickering, Martin and Nieuwland2016), particularly where the two languages are closely related (Foucart et al., Reference Foucart, Martin, Moreno and Costa2014). To date, there is no evidence of between-language prediction in bilinguals (e.g., predicting in the native language while attending to the non-native language). However, no study has investigated whether such between-language prediction may occur in a situation in which both languages are used – and we know that such situations do lead to both languages being strongly activated (Hatzidaki et al., Reference Hatzidaki, Branigan and Pickering2011; Friesen, Whitford, Titone & Jared, Reference Friesen, Whitford, Titone and Jared2019).
We therefore propose that between-language predictions occur in such situations. A good example of such a situation is of course found in simultaneous interpreting – a situation that in addition maximizes the value of prediction, and specifically prediction-by-production, because prediction-by-production can lead to highly specific predictions that interpreters may use as a basis for planning their own utterances. We suggest that this prediction takes place using the production mechanism. This means that interpreters covertly imitate the speaker to derive a precise speaker intention.
By our account, the speaker intention is first derived in the source language. Interpreters concurrently produce a translation in the target language. The extent of prediction depends on various factors including cognitive load, understanding of L2, and predictability of the speaker's utterance. We propose that where interpreters can, they use their production mechanism to make predictions at the semantic, syntactic, and phonological levels in order to comprehend the speaker as rapidly and precisely as possible.
We now develop our account in relation to languages that are either syntactically matched or not matched with respect to the construction in question, and assume a proficient simultaneous interpreter. The account is based on Pickering and Gambi (Reference Pickering and Gambi2018), and applied to cross-linguistic prediction in the context of simultaneous interpreting.
In this example of syntactically matched languages (Figure 1), the interpreter hears the utterance (English) at t 0 (start time) and covertly imitates the speaker using the production mechanism at the same time (t 0). At this point, the interpreter could make self-other adjustments between herself and the speaker (who in this scenario could be the chair of a meeting in a large international organisation). Shared background or extralinguistic information – for example, seeing that the delegates all have nameplates and knowing the standard procedures in this type of meeting – provide context that helps make predictions more accurate. The interpreter comprehends and covertly imitates the speaker's utterance, thereby generating production representations with the production mechanism and using these to derive the speaker intention at t 1, covertly producing the predictable word “nameplate” before it is uttered by the speaker (at t 2). This prediction-by-production takes place in the source language (English).

Fig. 1. An illustration of a simultaneous interpreter predicting using the production mechanism while interpreting from English into French (a syntactically matched language pair). Boxes with solid lines refer to mandatory processes; boxes with dashed lines represent optional processes. Greyed-out boxes refer to key simultaneous interpreting processes ongoing from the start of the speaker's utterance until the utterance of the predictable word. t0 represents the start time. The intention is then derived at t1. The interpreter simultaneously produces the start of the utterance in French at t1. At t2, the speaker then produces the predictable utterance, which the interpreter has already predicted in the source language at t1. Based either on the predicted utterance in French (produced at t2), or else on the speaker's utterance, also uttered at t2, the interpreter produces the word “pancarte” at t3. This involves either both selecting the lemma and articulating (if the interpreter bases the translation on the speaker's utterance), or else articulating directly (if the interpreter has already predicted the French translation of the predictable word). The interpreter now produces the translation at t3. Both production and comprehension mechanisms are processing English and French simultaneously.
Simultaneously, once the interpreter has heard enough of the utterance to begin to plan and formulate her own utterance (here, for example, the interpreter might start interpreting after hearing: “If you wish to take the floor”), she begins overt production in the target language (French). During this overt production, she continues covert imitation of the speaker. The production system is in dual use during simultaneous interpreting, both for planning and producing the interpreter's own speech and for predicting sentence constituents in the source speech, just as the comprehension system is used dually for both comprehension of the original speech and self-monitoring of the interpreter's own utterances (see De Groot, Reference De Groot2011). Such dual use is manageable because the two uses of the system are closely related to each other.
Prediction is advantageous because the interpreter comprehends more rapidly, allowing her to focus her attention on planning her own utterance and monitoring her own production. Subsequently, the production representation of the predictable word automatically activates its translation equivalent in French, or the interpreter selects the French translation for the predictable word. This happens as the speaker utters the predictable word in English. Production of the word in question (here, pancarte, meaning nameplate in this context) is not predictive. The interpreter may produce her utterance (at t3) based on the predictive production representations generated in French at t2, in which case she will articulate the production representation generated during covert predictive production. Alternatively, she may produce her utterance based on the overt speaker utterance also produced at t2, in which case she will select the French lemma before articulation.
The production intention in the syntactically mis-matched pair (Figure 2) is derived as in the matched language pair, using prediction-by-production. In this case, the interpreter could derive the speaker's intention to produce the verb eintragen (to add).
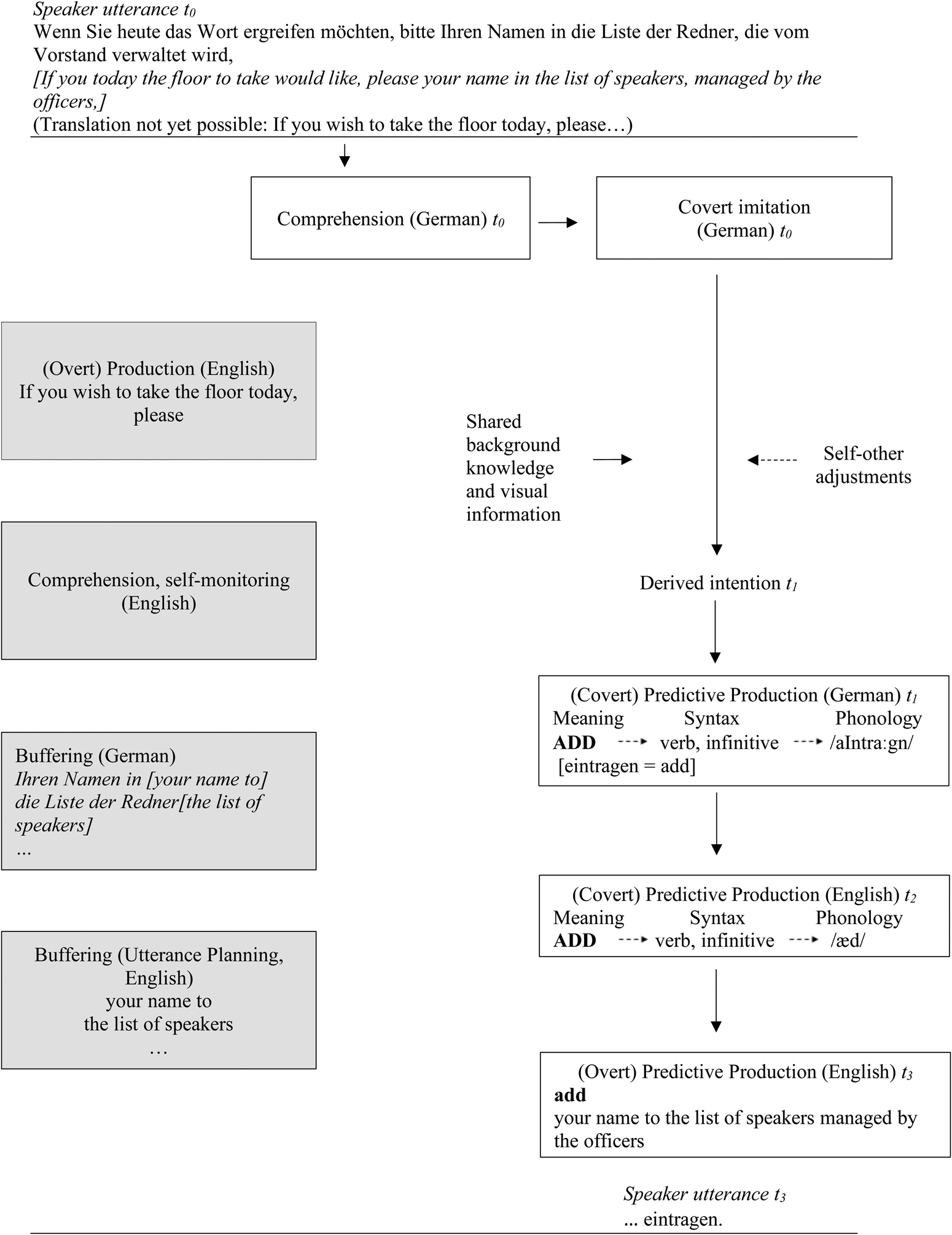
Fig. 2. An illustration of a simultaneous interpreter predicting using the production mechanism while interpreting from German into English (a syntactically mis-matched language pair). Boxes in solid lines represent mandatory processes, dashed arrows represent optional processing. Greyed-out boxes refer to key simultaneous interpreting processes ongoing from the start of the speaker's utterance until the utterance of the predictable word. t0 represents the start time. The intention is derived at t1. At t2 the interpreter covertly predictively produces the English equivalent. The interpreter overtly produces the verb at t3, either just before or just after the speaker produces the verb (also at t3).
Once the interpreter has heard enough of the utterance to begin formulating her own utterance, she begins overt production in the target language (English). Here, for example, the interpreter might hear Wenn Sie heute das Wort ergreifen möchten (If you wish to take the floor today), before uttering the translation of the relative clause. However, she will not be able to plan the rest of her utterance in English (translation of the main clause) without first predicting the German verb, which comes at the end of the clause because of the syntactic constraints of German.
She will have to buffer some of the information she has covertly imitated in German. Subsequently, she will have to buffer the planned utterance in English. Buffering increases cognitive load as the interpreter retains pieces of information while planning and producing the start of her utterance and comprehending new information.
If the interpreter derives, with precision, the speaker's intention, she will be able to plan and perhaps produce her utterance earlier (as shown in Figure 2). This will reduce cognitive load because buffering time is reduced. Even if the interpreter does not predictively produce the verb, if the utterance is planned before the interpreter hears the verb, she will be able to produce the translation without delay. Without prediction, the interpreter would be unable to plan her own utterance before hearing the verb.
It would therefore be advantageous to predict the verb of the German utterance. Although cognitive resources would be required to formulate the prediction, the cognitive load would be greater if no prediction were formed. If the interpreter is relatively confident about her prediction, it would be advantageous to predictively produce the verb add before the verb eintragen is uttered. As in the matched language pair, cross-language prediction takes place, as the interpreter predicts the word in the source language and then activates its translation in English before hearing it in the source language. Unlike in the matched pair, predictive production may take place.
Conclusion
We propose that prediction is key to rapid language comprehension, and that predicting using the production mechanism allows comprehenders to make rapid predictions at the levels of semantics, syntax and phonology. Simultaneous interpreting is an ecological context in which prediction during comprehension is highly advantageous, as interpreters must simultaneously plan their own upcoming utterances based on the speech to which they are attending. The greater the accuracy with which they are able to predict the completion of an upcoming utterance, the better they can plan their own utterance, even in some cases predictively producing the translation of a word in the target language before hearing it uttered in the source language. However, this prediction could be affected by a number of factors: cognitive load, proficiency in the non-native language, the level of cross-activation possible between the two languages used, and the degree of syntactic symmetry across the two languages. Future research could explore how some of these factors affect prediction during simultaneous interpreting. It could also explore whether predictions are made in the source or target language (with predictions made in the source language supporting our account). Another avenue for research would be to consider whether training – for example, in quickly producing utterances in the L2, or on how to use preparation materials so that content is predictable – influences the way in which predictive processing is used in simultaneous interpreting.
Acknowledgements
Rhona Amos is a PhD candidate at the University of Geneva funded by the Département de l'Instruction Publique, Geneva, Switzerland. Thanks are extended to the team at the Department of Interpreting of the University of Geneva for their feedback on the first draft of this article.


