





Highlights
-
- Adult L2 learners were tested either in the lab or in a web-based setting.
-
- Both groups performed a lexical decision task and a self-paced reading task.
-
- Effects of word order and plausibility were found in L2 sentence comprehension.
-
- Cognate effects emerged neither in isolation nor in L2 sentence context.
-
- Results were comparable across both the lab-based and web-based groups.
1. Introduction
Since the COVID-19 pandemic, web-based data collection has experienced an upsurge in linguistic research. Due to social distancing restrictions and other safety precautions during the pandemic, conducting (psycho)linguistic experiments in person had become almost impossible for a period of time. Therefore, more and more researchers had resorted to not only recruiting but also testing participants via the internet, and since then, the body of research on web-based data collection has grown substantially (see e.g., Gagné & Franzen, Reference Gagné and Franzen2023; Rodd, Reference Rodd2024; Sauter et al., Reference Sauter, Draschkow and Mack2020, for introductions to online behavioral data collection). Not only has the pandemic made it indispensable for many researchers to resort to online methods, but the possibility of collecting data via the web has also made accessing participants more convenient and enabled testing more diverse samples. Thus, remote testing facilitated reaching participants from wider geographical contexts or rather understudied populations (Garcia et al., Reference Garcia, Roeser and Kidd2022), and it allowed for data collection in less time compared to in-person laboratory studies. However, fundamental questions have emerged about the reliability and validity of web-based exploration of linguistic processes in behavioral experiments. To this day, many researchers still treat online data collection with caution and view the lack of control during data collection with skepticism (Sauter et al., Reference Sauter, Stefani and Mack2022). Thus, the quality of web-based data collection has been frequently questioned in terms of technical disparities and human factors possibly affecting experimental outcomes. Technical influencing factors may include differences in hardware, such as variation in response time measurements depending on the keyboard (Neath et al., Reference Neath, Earle, Hallett and Surprenant2011) or the use of different triggering devices, such as touchscreen versus keyboard (Pronk et al., Reference Pronk, Wiers, Molenkamp and Murre2020). In addition to differences in hardware, software can likewise have an impact on the course and outcome of behavioral experiments. In a mega-study by Bridges et al. (Reference Bridges, Pitiot, MacAskill and Peirce2020), the comparability of response time measurements with ten different experimental software packages in both online and offline settings was assessed. The authors found that web-based technologies provided a slightly higher variability and thus less precise measures of response times than lab-based systems. Nonetheless, the authors argue that online data collections can still be suitable, particularly when comparing participants’ response times across conditions. Similarly, Reimers and Stewart (Reference Reimers and Stewart2015) concluded that different computer systems and browser plug-ins can operate similarly regarding the detection of response time differences across conditions, and potential small effects on measured response times vanish with using within-subject designs. Assessing five widely common cognitive experimental paradigms, such as the Stroop and Flanker task, Semmelmann and Weigelt (Reference Semmelmann and Weigelt2017) compared three environmental settings: traditional lab-based testing, using web technology in the lab and regular web-based data collection. The authors included the “web in lab” setting to account for potential differences between settings induced by the use of (web) technology rather than the environmental setting. Overall, the authors found no difference in error rates regardless of the setting. However, web-based technology caused a timing offset of about 37 ms, which may be ascribed to factors inherent to JavaScript. Nevertheless, despite the timing offset, general task-specific effects were replicated in all three settings – except for the priming paradigm, which was not replicable in any of the settings (for a discussion on the absence of a priming effect, see Semmelmann & Weigelt, Reference Semmelmann and Weigelt2017). To sum up, potential confounding factors induced by differences in hardware and/or software might be of only little importance depending on the research objective and can be controlled for by focusing on differences in participants’ response times between conditions (for similar conclusions, see Anwyl-Irvine et al., Reference Anwyl-Irvine, Dalmaijer, Hodges and Evershed2021; Pronk et al., Reference Pronk, Wiers, Molenkamp and Murre2020).
Besides technical influences, human factors can similarly have an impact on web-based data collection. One main aspect that distinguishes online data collection from in-person testing in the lab is the reduced level of control in the web-based format. With web-based testing, it is more difficult to minimize or eliminate potential confounding factors such as environmental noise, to monitor the participants’ concentration, and – depending on the nature of the task – to prevent participants from using external resources during task completion. To investigate such potential issues, Germine et al. (Reference Germine, Nakayama, Duchaine, Chabris, Chatterjee and Wilmer2012) examined the comparability of data quality of web versus lab samples with a wide range of cognitive and perceptual tests. Their results contradict the previously wide-spread assumption of increased performance variability and measurement noise in web samples compared to lab samples that was assumed to be induced by a potential lack of focus and motivation in unsupervised settings: Overall, no differences in mean test performance, performance variance and internal measurement reliability between web and lab sample were observed for most measures. Although differences between the groups were evident in mean performances for two tests tapping into aspects of general intelligence, the authors argue that these differences were not systematic (i.e., mean performance differences were observed in both directions). Hence, the authors suggest these differences are derived from sample-inherent characteristics rather than general data quality. Consequently, their findings suggest that testing unsupervised participants online does not necessarily need to impede data quality but that cognitive processes can be mapped similarly well instead (for similar results, see De Leeuw & Motz, Reference De Leeuw and Motz2016, for visual search; Kochari, Reference Kochari2019, for numerical cognition; Miller et al., Reference Miller, Schmidt, Kirschbaum and Enge2018, for cognitive paradigms; Weydmann et al., Reference Weydmann, Palmieri, Simões, Centurion Cabral, Eckhardt, Tavares, Moro, Alves, Buchmann, Schmidt, Friedman and Bizarro2023, for reinforcement learning).
In line with the general trend toward an increase in use of online data collection methods for behavioral research, a growing number of psycholinguistic researchers have addressed the topic of web-based testing compared to in-person, lab-based data collection as well. Similarly, the broad consensus in this field of research is that online testing can serve as a suitable means for psycholinguistic data collection – provided that its use is always scrutinized against the backdrop of the respective research question and objective. Recent studies investigating well-established effects on first language (L1) word recognition have found that response time effects obtained in lab-based experiments could be replicated in web-based settings, including effects of word frequency (Hilbig, Reference Hilbig2016) and emotionality (Kim et al., Reference Kim, Lowder and Choi2023). Hilbig (Reference Hilbig2016) examined the word frequency effect in a lexical decision experiment in three different contexts (similar to Semmelmann & Weigelt, Reference Semmelmann and Weigelt2017): a classical lab setting with standard experimental software, a lab setting with browser-based software, and a web setting with browser-based software. The author found a large effect of word frequency in reaction times for all three contexts, with no main effect of context or significant interaction of the two parameters. This demonstrates that robust response time effects found in previous lab-based research can be replicated using web-based technology. More recently, Kim et al. (Reference Kim, Lowder and Choi2023) investigated the effect of emotion words on lexical decision times in a web-based and a lab-based setting. The authors found faster response times for positive and negative compared to neutral words in both settings. Similar to Hilbig (Reference Hilbig2016), there was no evidence of a difference between settings. Thus, the findings of both studies add to the previous literature, providing evidence of the comparability of web- and lab-based reaction time measurements.
The use of web-based technologies for behavioral research has not only increased in L1 research but also in research on second language (L2) processing (e.g., Berger et al., Reference Berger, Crossley and Skalicky2019, for L2 lexical processing; Klassen et al., Reference Klassen, Kolb, Hopp and Westergaard2022, for L2 syntactic processing; Tiffin-Richards, Reference Tiffin-Richards2024, for L1 and L2 lexical and syntactic processing). However, fewer L2 studies have directly compared outcomes of web-based data collection relative to in-person lab-based testing. While there may be little reason to assume that comparing these two settings in L2 research will produce fundamentally different results compared to L1 research, findings obtained with native speakers should not automatically be generalized to L2 learners. Importantly, certain learner-intrinsic factors that impact the acquisition and processing of languages, such as target language proficiency and affective factors like motivation or anxiety, are generally assumed to be constant across L1 speakers but may differ widely across L2 learners (Ellis, Reference Ellis, Davies and Elder2004). Due to this greater variability, L2 learners may be more easily affected by external factors such as the general setting – a factor that is more difficult to control for in web-based settings. Additionally, regarding participant recruitment, there may be greater variability, particularly in L2 proficiency, in online L2 learner recruitment via platforms like MTurk (Amazon Mechanical Turk; Buhrmester et al., Reference Buhrmester, Kwang and Gosling2011) compared to online testing of a preselected group of participants, such as university students, possibly due to a larger diversity in first languages or a wider range of L2 proficiencies on participant platforms. Based on this assumption, an L2 self-paced reading study by Patterson and Nicklin (Reference Patterson and Nicklin2023) compared syntactic processing of proper versus common nouns in sentence context across three samples: a crowdsourced population tested online, a student population tested online, and in-person data collected from students in a previous study conducted in the lab. Their findings provide evidence for the overall replicability of lab-based outcomes in both online settings. However, the authors found higher L2 proficiency in their crowdsourced sample and drew attention to the overall poorer controllability of proficiency on crowdsourcing platforms. Consequently, they point out that the method of participant recruitment should always be considered with regard to the research objectives.
1.1. The present study
Against the backdrop of the rather sparse literature on comparability of behavioral data in L2 research, the present study aims to fill this gap by focusing on the direct comparison of web-based and lab-based testingFootnote 1 in two linguistic domains, namely L2 lexical and sentence processing. For this purpose, several well-established linguistic effects on both the lexical level (i.e., the word/nonword effect and the cognate facilitation effect) and sentence level (i.e., effects of word order and plausibility as well as cognate effects in sentence context) will be further examined.
With regard to L2 lexical processing, the present study aims to replicate two robust psycholinguistic findings concerning the lexicon. On the one hand, the aim is to demonstrate the well-established word/nonword effect (expressed through a delay in processing of nonwords; e.g., Stanners et al., Reference Stanners, Jastrzembski and Westbrook1975) in both experimental settings using a Lexical Decision Task (LDT; Experiment 1) in the participants’ L2. Furthermore, Experiment 1 aims at replicating language co-activation through cognates, which has been extensively demonstrated in lab-based research on lexical processing in second language learners. Cognate words are translation equivalents that share meaning and similar/identical form across languages (e.g., English banana, German Banane). There is ample evidence that cognates are processed faster and more accurately by bilinguals than noncognates, which are translation equivalents without such form overlap (e.g., English pumpkin, German Kürbis). Such a processing advantage of cognate over noncognate words (the so-called cognate facilitation effect) is considered evidence for co-activation of languages and language nonselective access in bilingual speakers (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010).
Furthermore, the present study examines L2 sentence processing in both settings. Experiment 2 aims at replicating three known effects in L2 sentence comprehension through self-paced reading (SPR): (1) lexical co-activation in sentence context, (2) the effect of word order and (3) the effect of world knowledge (plausibility). Building on Experiment 1, Experiment 2 investigates cognate processing in L2 sentence context to assess lexical co-activation during sentence processing (e.g., Hopp, Reference Hopp2017; Miller, Reference Miller2014; Tiffin-Richards, Reference Tiffin-Richards2024). Previous studies have shown that word processing can differ depending on the context in which words are presented (e.g., isolation versus sentential context; Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Lauro & Schwartz, Reference Lauro and Schwartz2017). The additional language context in sentences, bearing semantic and/or syntactic constraints, may affect or even mitigate possible lexical effects during reading (Tiffin-Richards, Reference Tiffin-Richards2024). Thus, it is warranted to more closely inspect the processing of lexical items not only out of context but also within context.
Furthermore, the SPR task examines the processing of noncanonical word orders by testing the comprehension of English subject relative clauses (SRC; (1)) compared to object relative clauses (ORC; (2)).
Previous research has found ample evidence that canonical SRC structures are processed faster and more accurately than noncanonical ORCs in both native and non-native speakers of English (Lau & Tanaka, Reference Lau and Tanaka2021; Lim & Christianson, Reference Lim and Christianson2013). A reason for processing disadvantages for English ORCs might be their greater structural complexity due to a greater distance between filler and gap position. This complexity may cause higher working memory demands compared to less complex SRCs (Gibson, Reference Gibson1998). For L1 German learners of L2 English, there is an additional difficulty: The German parse for English ORCs is ambiguous. Whereas in English, SRCs (1) and ORCs (2) are disambiguated by word order, in German, relative clause (RC) structures do not differ in verb position but are instead disambiguated via case marking for masculine nouns (SRC: 3, ORC: 5) or remain ambiguous for feminine and neuter nouns (7). Thus, these learners will have to use their L2 syntactic knowledge to parse successfully.



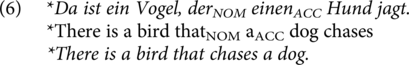

Additionally, Experiment 2 examines the impact of plausibility on L2 sentence processing. Previous research has shown that sentences that are not consistent with our world knowledge (see examples 4 and 6; asterisks indicate implausibility) are harder to process and more likely to be misinterpreted (Ferreira, Reference Ferreira2003; Lim & Christianson, Reference Lim and Christianson2013).
The present study will investigate a) the replicability of the aforementioned lexical and sentence-level effects and b) the comparability of web-based and lab-based findings. We ask the following research questions:
RQ1: Can the effects of word status (word/nonword) and cognate status (cognate/non cognate) during L2 lexical processing in isolation be replicated in web-based and lab-based settings? Does processing in the two settings differ?
RQ2: Can the cognate effect during lexical processing in L2 sentence context be replicated in web-based and lab-based settings? Does processing in the two settings differ?
RQ3: Can the effects of word order and plausibility during L2 sentence processing be replicated in web-based and lab-based settings? Does processing in the two settings differ?
These research questions will be addressed by administering a Lexical Decision Task (Experiment 1) and a Self-paced Reading Task (Experiment 2) in the participants’ L2. Both experiments assess decision accuracies as a measure of offline comprehension and response times as a measure of processing speed. We predict the replication of the previously mentioned well-established effects in both settings. Regarding the comparability of findings in the online versus laboratory setting, the present study’s exploratory aim is to test whether the absence of differences between settings observed in previous studies on L1 processing can be replicated in a population of bilingual speakers.
2. Experiment 1 – Lexical decision task
2.1. Participants
A total of 134 L1 German L2 English speakers participated online (n = 78) or in the lab (n = 56). All subjects were recruited from a population of students of English linguistics at TU Dortmund University. In the web-based experiment, 13 participants were excluded from further analyses due to missing data and/or technical issues. Additionally, participants were excluded because they were L1 English (2), not L1 German (1), did not study English (7) or had an eye disease (1) that impeded their participation. In the lab-based experiment, participants were excluded due to missing data (1) or previous participation in the web-based study (3). Thus, 54 online participants (43 female, 10 male, 1 nonbinary) and 52 lab participants (41 female, 8 male, nonbinary) remained for further analyses. All participants filled in a background questionnaire assessing their first language(s) and further language learning history, as well as their social background (based on the Language and Social Background Questionnaire, LSBQ; Anderson et al., Reference Anderson, Mak, Keyvani Chahi and Bialystok2018). Thirteen participants from each group reported having another L1 in addition to German. Furthermore, participants’ language proficiencies were assessed through the German and English versions of the LexTALE (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012), a vocabulary test in which participants have to distinguish words from pseudowords.Footnote 2 Participants were advanced learners of L2 English, indicated by a mean English LexTALE score above 80, which roughly corresponds to C1-level advanced learners according to the Common European Framework (CEF; see Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012, for a correlation between LexTALE scores and CEF proficiency levels). Participant characteristics are summarized in Table 1. Independent sample t-tests showed no significant differences in background measures between the groups (all ps > .33). Participation was voluntary, and participants joined the study either as part of a seminar or received a small monetary compensation. Informed consent was secured from all participants. Ethical approval was granted by the Ethics Committee of TU Dortmund University (ethics vote no. GEKTUDO_2022_38 & GEKTUDO_2022_39), and the study followed the principles of the 1964 Declaration of Helsinki.
Table 1. Participant characteristics (n = 106)

a English use was aggregated across five situations (with family, with friends, at university, using media such as movies and reading, on social media) on a 10-point rank scale (ranging from 1 = I do not use English in these situations at all. to 10 = I exclusively use English in these situations.)
b Flanker effect as a measure of inhibitory control, calculated by subtracting congruent from incongruent reaction times in the Flanker task.
2.2. Materials
The experimental stimuli consisted of 160 letter strings, including 80 words and 80 nonwords.
2.2.1. Words
The words contained 40 cognates and 40 noncognates between German and English and were matched across conditions on length, number of syllables, frequency (SUBTLEX-US log10; Brysbaert & New, Reference Brysbaert and New2009) and orthographic and phonological neighborhood size (English Lexicon Project; Balota et al., Reference Balota, Yap, Hutchison, Cortese, Kessler, Loftis, Neely, Nelson, Simpson and Treiman2007). Independent sample t-tests yielded no significant difference between conditions (all ps > .15). For cognates and noncognates, normalized orthographic Levenshtein distance (Levenshtein, Reference Levenshtein1966; Schepens et al., Reference Schepens, Dijkstra and Grootjen2012) was calculated as a proxy for overlap between languages. Cognates and noncognates differed significantly (p < .001), with cognates exhibiting more overlap than noncognates. Stimuli characteristics for target words are displayed in Table S1 (Supplementary Materials).
2.2.2. Nonwords
The nonwords consisted of 80 pseudowords created by selecting 80 English nouns (that did not serve as target words) and changing only one letter in each word. It was ensured that the newly created nonwords did not exist in German and followed the rules of English orthography and phonotactics (for a similar procedure, see Dijkstra et al., Reference Dijkstra, Van Hell and Brenders2015). Nonwords and words were exactly matched on length and number of syllables (p = 1).
2.3. Procedure
Participants performed a visual English Lexical Decision task in which they had to decide as quickly and accurately as possible whether a word presented on screen was an existing English word or not. Decisions were made by pressing one of two designated keys on the keyboard in the web-based experiment or one of two designated buttons on a MilliKey MH-5 button box in the lab-based experiment. For the online experiment, the keys “f” (for NO-presses) and “j” (for YES-presses) were chosen. These keys are comparably positioned across keyboards as they serve as the position keys for typewriting (and hence, usually have small bumps on them). Both groups were presented with on-screen instructions. The stimuli were presented in white ink (#FFFFFF), 40 px Arial font, on a black background (#000000) at the center of the screen. All stimuli were displayed in capitals to avoid language cues, as in German (unlike English), all nouns are always capitalized (see Lemhöfer et al., Reference Lemhöfer, Huestegge and Mulder2018). Each trial started with a 500 ms fixation cross at screen center. The target stimulus followed and remained on screen for a maximum of 3000 ms or until a key/button was pressed. No feedback regarding participants’ responses was provided. The experiment was presented in five blocks: a ten-trial practice block followed by four experimental blocks of 40 items each. The first three experimental blocks were followed by a short break that allowed the participants to rest until they pressed a key/button to continue. Stimuli were presented in a different randomized order per participant. The experiment took approximately 5 minutes and was programmed in OpenSesame (version 3.3.11; Mathôt et al., Reference Mathôt, Schreij and Theeuwes2012).
In addition to the Lexical Decision task and the self-paced reading experiment (see Experiment 2), the participants completed several background tasks, the results of which are not covered in this paper. The order of tasks was as follows: (1) Lexical Decision task, (2) Flanker task, (3) Self-paced Reading task, (4) German LexTALE, (5) English LexTALE, (6) Reading Span task, (7) Questionnaire. In total, the testing session took approximately 70 minutes.
2.3.1. Web-based experiment
For the web-based version of the task, OSWeb was used to ensure that the experiment could be run in a browser (Mathôt & March, Reference Mathôt and March2022). A key advantage of OSWeb is that it supports not only different operating systems, such as Windows or macOS, but also multiple browser types. The experiment was hosted on JATOS (Lange et al., Reference Lange, Kühn and Filevich2015), and participants took part with their own computer/laptop. Participation via tablets was not permitted. To make participation more accessible for a larger sample, the operating system was not restricted. In terms of browsers, specific versions for certain browsers were specified in advance to ensure the proper functioning of the online experiments. Prior to the experimental session, participants were briefed by the experimenter in a meeting via an online video conferencing tool. These meetings either took place individually or in small groups to allow for simultaneous testing. The experimenter instructed the participants to perform the study alone, in a quiet environment and to limit potential confounding factors as best as possible by, for instance, closing all nonrelevant computer applications. Although data collection was carried out online, it still took place in a semi-supervised setting: If questions arose during the session, participants could revisit the online meeting and consult the experimenter at any time, preferably not during the experimental blocks. Data collection took place during the week, either in the morning or afternoon.
2.3.2. Lab-based experiment
Participants were tested individually and under supervision of the experimenter in the lab during times equivalent to the web-based data collection.
2.4. Results
Accuracy rates and reaction times (RTs) for words/nonwords and cognates/noncognates were analyzed in R (version 4.4.0; R Core Team, Reference Team2024). One noncognate item (EN: pupil) was removed because it is a homonym with both a noncognate translation (Schüler:in) and a cognate one (Pupille) in German. For the accuracy analysis, RTs below 200 ms were coded as false alarms (web: n = 1; lab: n = 0). For the RT analysis, incorrect button presses and extreme RTs above 2000 ms (web: n = 115 [1.39%]; lab: n = 104 [1.31%]) were excluded. Table 2 lists the accuracy rates and RTs for the respective conditions.
Table 2. Mean accuracies (proportions) and reaction times (in milliseconds) by group and condition

Note: Standard deviations are in parentheses.
Accuracy and RT data were analyzed using mixed-effects regressions with the aid of lme4 (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) and lmertest (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). Separate models were run for the analyses of word status and cognate status. For the analyses of words and nonwords, word status, setting and their interaction were entered as fixed effects. For the analyses of cognates and noncognates, nonwords were removed from the data set, and cognate status, setting, as well as their interaction, were entered as fixed effects. All two-level fixed effects were sum-coded (setting: web = 1, lab = −1; word status: nonword = 1, word = −1; cognate status: cognate = 1, noncognate = −1). To identify the maximal converging random effect structure, the “order” function in the buildmer package was used for all mixed-effect models (Voeten, Reference Voeten2021).Footnote 3 Effect sizes were calculated with the effectsize package (Ben-Shachar et al., Reference Ben-Shachar, Lüdecke and Makowski2020). Overall, accuracies were close to the ceiling, which speaks to the participants’ high L2 proficiency. For words and nonwords, the model returned a significant main effect of word status for accuracy (ß = −0.61, SE = 0.12, z = −4.94, p < .001, d = −0.96) and RT data (ß = 111.01, SE = 9.04, t = 12.28, p < .001, d = 2.4), with words being processed more accurately and faster than nonwords. Furthermore, accuracy analyses of cognates and noncognates yielded a moderate main effect of cognate status (ß = 0.32, SE = 0.12, z = 2.60, p = .009, d = 0.51), with cognates being processed more accurately than noncognates. RT analyses yielded neither main effects nor an interaction. Note that none of the models yielded a main effect of or an interaction with setting. Detailed model output is displayed in Table 3.
Table 3. LDT model outputs for word status (word versus nonword) and cognate status (cognate versus noncognate) after “buildmer” model optimization

Note: Significant effects in bold.
2.5. Discussion
Experiment 1 investigated the replicability of the word/nonword effect as well as the effect of cognate status during isolated L2 lexical processing. Besides the replicability of these well-established effects, the comparability of L2 word recognition across the two settings was examined (RQ1). For word versus nonword processing, differences in accuracies and RTs were observed between the two conditions in both settings, replicating previous lab-based results. Although participants’ decision accuracies were above 90% in both conditions, analyses still yielded a significant difference between conditions, with comparatively lower accuracies for nonwords compared to words. Similar to previous findings, RT analyses revealed a processing disadvantage for nonwords over words, with pseudowords exhibiting a delay in processing. Additionally, overall mean RTs differed by only 6 ms between settings. This confirms previous observations by Hilbig (Reference Hilbig2016) and Kim et al. (Reference Kim, Lowder and Choi2023), who likewise demonstrated no significant difference in RT effects in web-based versus lab-based lexical decision.
For cognate versus noncognate processing, analyses of participants’ decision accuracies revealed a main effect of cognate status. With overall accuracies of 98% and 99% per condition, participants’ accuracy was high across the board, thus corroborating their overall high L2 English proficiency as evidenced by their English LexTALE results. The descriptively rather small difference of 1% yielded statistical significance, providing evidence for a cognate facilitation effect. However, contrary to initial predictions, the cognate facilitation effect could not be replicated in participants’ response times. Nonetheless, this pertains to both settings and thus suggests that the null results are not setting-induced (see also Semmelmann & Weigelt, Reference Semmelmann and Weigelt2017, who reported null effects with priming across three settings). The absence of a cognate facilitation effect in RTs may be a ceiling effect caused by participants’ overall high L2 proficiency (Bultena et al., Reference Bultena, Dijkstra and Van Hell2014) or the stimuli’s lexical frequency. The cognate and noncognate nouns used in the LDT were predominantly high-frequency nouns (mean SUBTLEX-US log10 = 3.25), which may have disguised potential cognate effects (Peeters et al., Reference Peeters, Dijkstra and Grainger2013). Consequently, future studies could further explore potentially modulating factors in cognate processing and limitations to the cognate facilitation effect. Although the cognate effect could not be replicated in the present study’s RT analysis, the overall findings of Experiment 1 suggest comparability of the results obtained in both the online and laboratory settings. The lexical decision manipulation itself was successful, as evidenced by the word/nonword RT effect observed in both settings.
In summary, these findings show that with overall ceiling performance in accuracies across settings, online testing did not prove to adversely affect participants’ concentration on ultimate decision-making. Additionally, RT results did not differ across groups, neither for relative RTs between conditions nor for absolute overall mean RTs. Thus, the results expand the findings of previous research by providing comparable evidence of L2 lexical processing across both web-based and lab-based experimental settings.
3. Experiment 2 – Self-paced reading task
3.1. Participants
The same participants who took part in Experiment 1 also participated in Experiment 2.
3.2. Materials
Experimental sentences were constructed based on a 2 (Sentence type: SRC versus ORC) × 2 (Plausibility: plausible versus implausible) × 2 (Cognate status: cognate versus noncognate) design. This resulted in 40 sentence quadruplets in the cognate condition and 40 sentence quadruplets in the noncognate condition (see 8a–h for examples; slashes indicate the phrases in which the sentences were presented). Additionally, 120 plausible and implausible filler sentences were created (see Appendix S1 in Supplementary Materials for details).

3.2.1. Sentence type
All target sentences were English present-tense embedded relative clause constructions (SRC and ORC), starting with “There is …” and containing one animate and one inanimate noun, a transitive verb and a locative prepositional phrase at the end. Each noun and verb was repeated twice throughout the experiment but always in different combinations (i.e., they never appeared twice with the same verb, noun or prepositional phrase). Each participant was presented with 80 target sentences, distributed across four lists following a Latin-square design. Hence, participants saw ten items per condition and, including filler sentences, responded to 200 sentences in total.
3.2.2. Cognate status
Cognate status was manipulated for the verb in the relative clause and for both nouns in the second and third phrase for each item. This means that in cognate sentences, all of these words were cognates, while in noncognate sentences, all of these words were noncognates. The manipulated nouns were identical to the target words in Experiment 1 (see Tiffin-Richards, Reference Tiffin-Richards2024, for a similar procedure).
3.2.3. Plausibility
Sentences were either semantically plausible or implausible. Plausibility of the target sentences was manipulated by reversing the roles of the animate agent and the inanimate patient. In plausible sentences, the agent was animate, and the patient was inanimate, while in implausible sentences, the agent was inanimate, and the patient was animate. The semantic plausibility of the sentences was assessed by L2 English speakers in a separate plausibility norming study prior to the actual experiment (see Ferreira, Reference Ferreira2003, and Lim & Christianson, Reference Lim and Christianson2013, for similar procedures), which yielded a significant difference between both conditions, with plausible sentences being rated as far more plausible than implausible ones (see Appendix S2 and Table S2 in Supplementary Materials for further details).
3.3. Procedure
Subsequent to the Lexical Decision task and the Flanker task, participants performed a noncumulative self-paced reading task in which they read English sentences phrase-by-phrase and rated the plausibility of each sentence immediately after having read it. Implausibility was defined as the event described in the sentence being very unlikely or even impossible to occur. Instructions were presented on screen. Phrases were presented in white ink (#FFFFFF), 40 px Arial font, on a black background (#000000) at the center of the screen, using the stationary window method. Trials were initiated with a 500 ms fixation cross at screen center. Subsequently, the sentences were displayed in phrases of different lengths (varying from one to four words) with a maximum of six phrases. Experimental sentences always consisted of four phrases. Each phrase remained on screen until a designated key was pressed (the space bar online; a central button on the button box in the lab). The first phrase always began with a capital letter. The last phrase always ended with a full stop to indicate the end of the sentence. It was followed by a visual display of a question mark that prompted participants to judge the plausibility of the previously read sentence by pressing one of two designated keys. Online, participants pressed the “f” (for implausible) and “j” (for plausible) keys on their keyboard (see Experiment 1). In the laboratory, a MilliKey MH-5 button box was used. No feedback regarding responses was provided. The experiment was presented in six blocks: A six-trial practice block preceded five experimental blocks of 40 sentences each. The total number of 200 sentences was randomly distributed across these five blocks. The first four experimental blocks were followed by short breaks that allowed participants to rest until they pressed a key to continue the experiment. The experiment lasted approximately 15–20 minutes and was programmed in OpenSesame (version 3.3.11; Mathôt et al., Reference Mathôt, Schreij and Theeuwes2012).
3.3.1. Web-based and lab-based experiment versions
The general set-up for both the web-based and the lab-based implementation of the experiment was identical to Experiment 1.
3.4. Results
Plausibility judgment accuracies and reading times were analyzed in R (version 4.4.0; R Core Team, Reference Team2024). Two noncognate items that contained the noun pupil were excluded from further analyses (see Experiment 1). Additionally, one item with a low plausibility judgment accuracy of 54% was removed. The remaining items had an average accuracy of 93% (range: 77–99%). For the analyses of reading times, the focus was on two regions of interest: (i) the critical phrase containing the RC and (ii) the post-critical phrase immediately following the RC. For reading time analyses, all items with incorrect plausibility judgment were excluded. Additionally, phrases with reading times below 200 ms and above 5000 ms were removed from further analyses (see Klassen et al., Reference Klassen, Kolb, Hopp and Westergaard2022, for a similar procedure). For the critical phrase, this resulted in the removal of 44 trials (web: n = 34 [0.89%]; lab: n = 10 [0.27%]). For the post-critical phrase, 77 trials were removed (web: n = 44 [1.15%]; lab: n = 33 [0.88%]). Table 4 lists the mean plausibility judgment accuracies and reading times for the critical and post-critical phrases per condition for both groups.
Table 4. Mean plausibility judgment accuracies (proportions) and reading times (in milliseconds) for critical and post-critical phrases per condition by group

Note: Standard deviations are in parentheses.
Accuracy and reading time data were analyzed using mixed-effects regressions (lme4, Bates et al., Reference Bates, Mächler, Bolker and Walker2015; lmertest, Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). Setting, sentence type, plausibility and cognate status, as well as their interactions, were entered as fixed effects into the models. Sum-coding was applied to the two-level fixed effects (setting: web = 1, lab = −1; sentence type: SRC = 1, ORC = −1; plausibility: plausible = 1, implausible = −1; cognate status: cognate = 1, noncognate = −1). By means of the “order” function in the buildmer R-package (Voeten, Reference Voeten2021), the maximal converging random effect structure was identified. Effect sizes were calculated with the effectsize package (Ben-Shachar et al., Reference Ben-Shachar, Lüdecke and Makowski2020). Plausibility judgment accuracy was overall high across the board, suggesting that in both groups, participants were able to successfully parse L2 noncanonical sentence structures. Still, generalized linear mixed effects analyses revealed a main effect of plausibility, with implausible sentences being processed more accurately than plausible ones (ß = −0.45, SE = 0.15, z = −3.09, p = .002, d = −0.6). For reading times in the critical phrase, analyses yielded significant main effects for plausibility (ß = −74.11, SE = 8.23, t = −9.01, p < .001, d = −1.76) and sentence type (ß = −48.27, SE = 7.50, t = −6.44, p < .001, d = −1.26), indicating that in the critical RC region, plausible sentences were overall processed faster than implausible ones and SRCs faster than ORCs. Analyses of reading times in the post-critical phrase revealed main effects of plausibility (ß = 47.11, SE = 16.21, t = 2.91, p = .004, d = 0.57) and sentence type (ß = −42.50, SE = 7.34, t = −5.79, p < .001, d = −1.13) and an interaction of both fixed effects (ß = −30.00, SE = 7.04, t = −4.26, p < .001, d = −0.83). In the post-critical region, implausible sentences were processed faster than plausible sentences – opposite to processing patterns in the critical phrase. Similar to the critical phrase, SRCs were processed faster than ORCs in the region following the RC. While there was a clear advantage for SRCs over ORCs for plausible sentences, the difference between these two conditions was much smaller for implausible sentences. Neither the main effects of cognate status or setting nor interactions with these two factors were found in any of the three dependent measures. Participants’ mean reading times for the critical and post-critical phrases are plotted in Figures 1 and 2. Note that these times were collapsed across cognate status to allow for better visualization, as this factor proved not to have a significant influence. Detailed model output is displayed in Table 5.
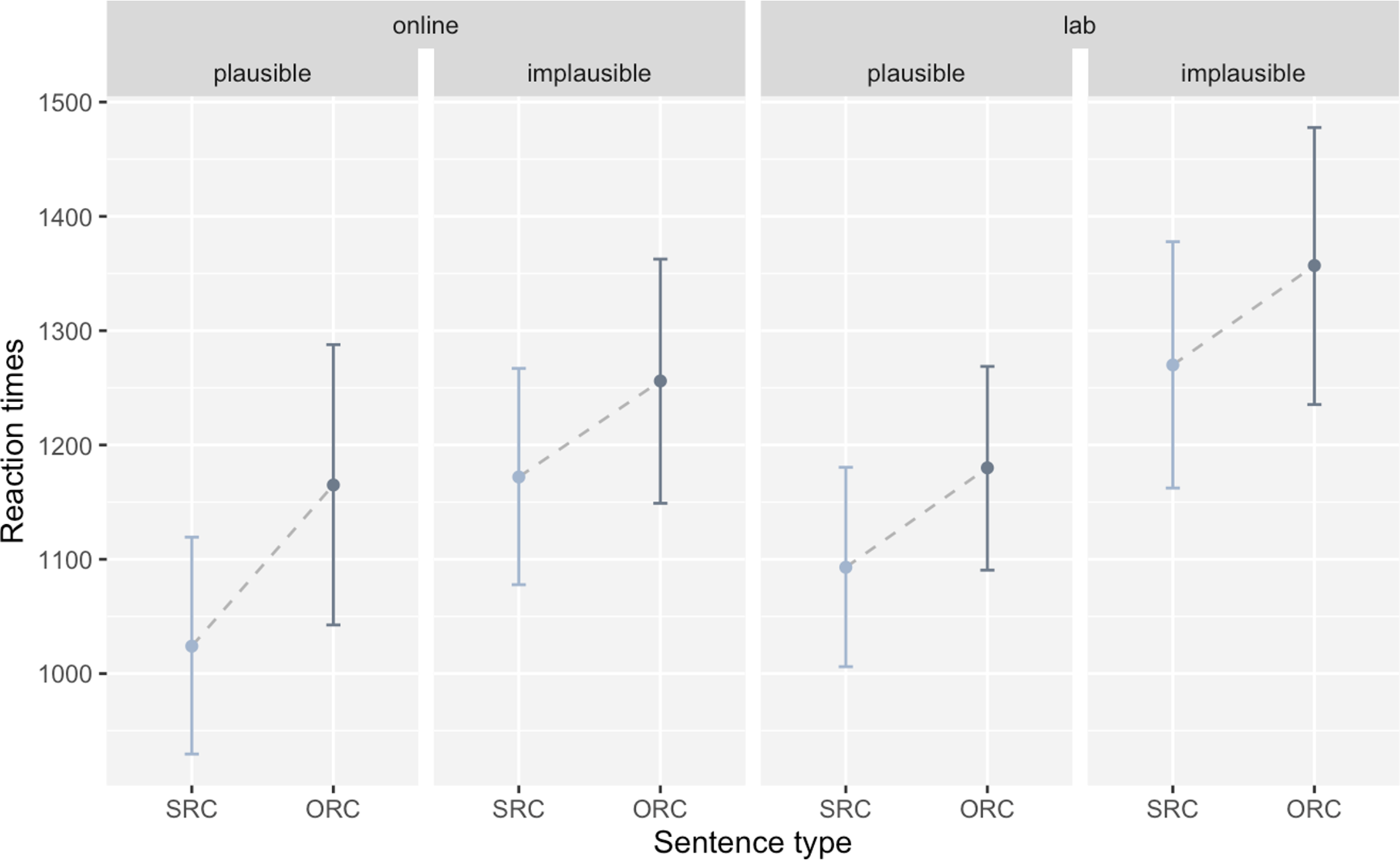
Figure 1. Mean reading times (in milliseconds) for the critical phrase by word order and by plausibility for both settings.
Note: Error bars show the 95% confidence interval.
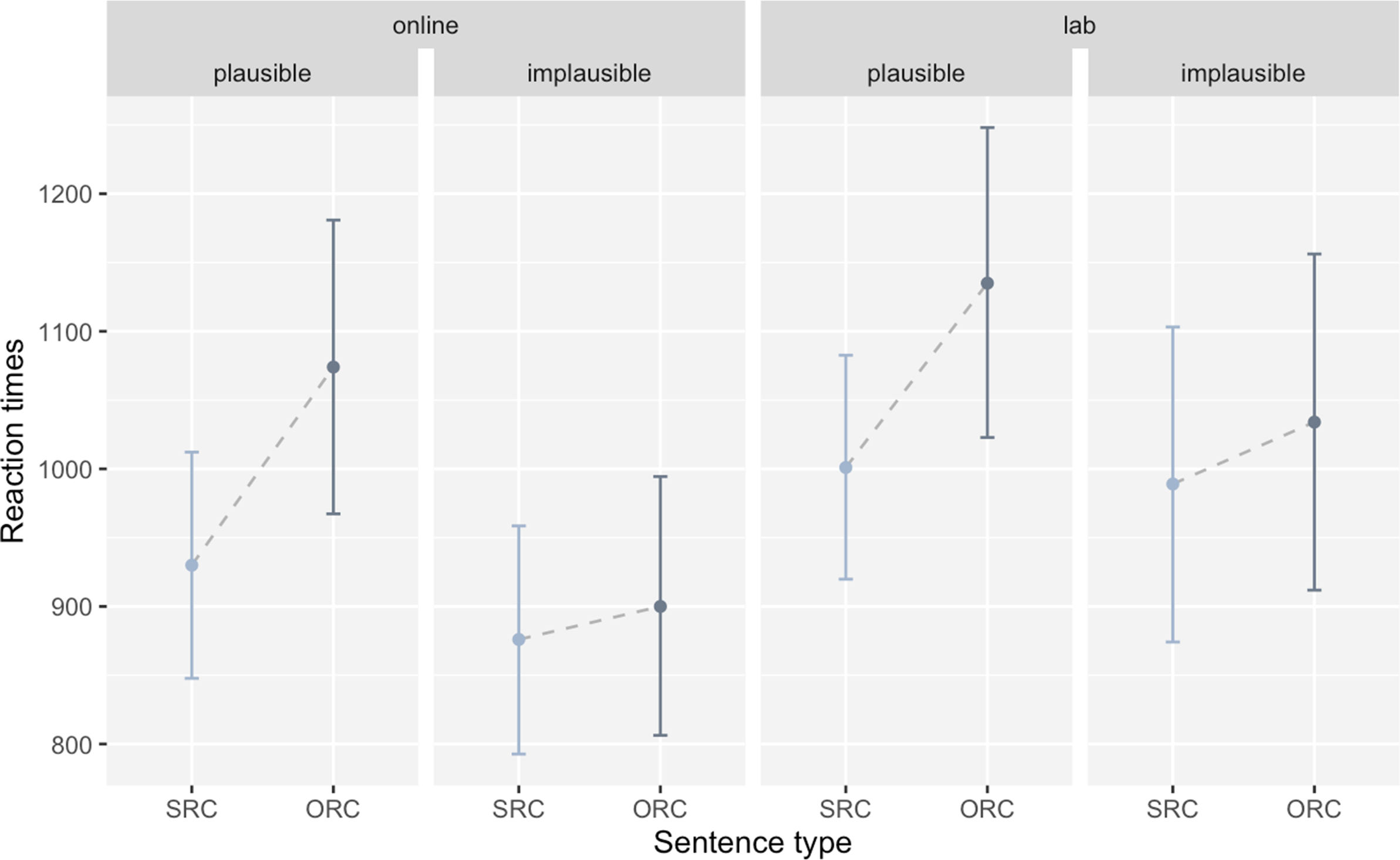
Figure 2. Mean reading times (in milliseconds) for the post-critical phrase by word order and by plausibility for both settings.
Note: Error bars show the 95% confidence interval.
Table 5. SPR model outputs after “buildmer” model optimization
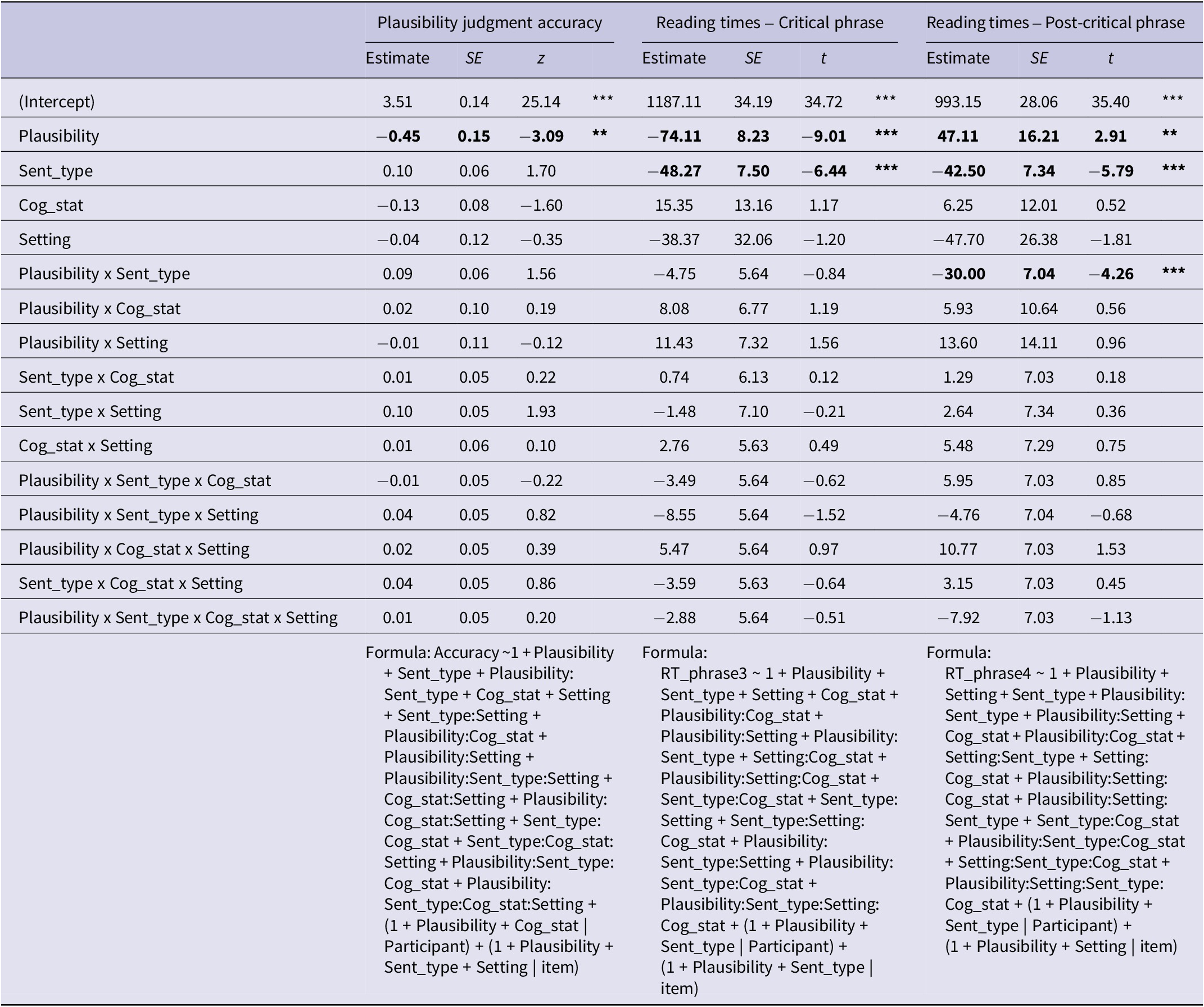
Note: Significant effects in bold.
Finally, the overall mean reading speed was compared between settings. Mean reading speed was calculated across the sum of reading times of all phrases for both experimental and filler sentences. Incorrect trials were excluded from further analyses, and extreme values above 10000 ms were considered outliers and thus removed. The fixed factor setting was sum-coded. Whereas the two groups differed descriptively by about 200 ms, with the online group (M = 3005 ms) being faster than the lab group (M = 3212 ms), linear mixed effects analysisFootnote 4 on overall mean reading speed revealed no significant impact of setting on overall reading times (ß = −103.08, SE = 68.51, t = −1.51, p = .132, d = −0.29).
3.5. Discussion
Experiment 2 examined the replicability of cognate effects in L2 sentence context (RQ2) and that of word order and plausibility effects during L2 sentence processing (RQ3). Moreover, the comparability of online and laboratory testing was further investigated based on these linguistic phenomena. Whereas lexical co-activation through cognates as observed in prior studies could not be replicated, the present study observed effects of both word order and plausibility on sentence processing. Importantly, the study found similar results for both settings in the accuracy of sentence final judgments as well as two reading time measures, suggesting the comparability of both testing contexts. In the following, we will first discuss the absence of cross-linguistic lexical effects induced by cognates during L2 sentence processing and then review the effects of word order and plausibility on L2 sentence comprehension. Both research questions (RQ2 and RQ3) will be considered against the methodological backdrop of the testing environment.
In view of RQ2 concerning lexical processing in L2 sentence context, the results resemble the null findings for RTs obtained in Experiment 1. Similarly, no effect of cognate status was found in plausibility judgment accuracies or reading times of either the critical or the post-critical phrase in either of the two settings. Thus, in contrast to previous studies (Hopp, Reference Hopp2017; Miller, Reference Miller2014), a cognate facilitation effect during L2 sentence processing could not be replicated. Instead, descriptively, critical phrases containing cognate words were processed more slowly than those containing noncognate words across all conditions. While this cognate disadvantage was not statistically significant, it is a pattern that can be observed across both groups. The fact that results from both settings showed similar descriptive and inferential results provides further evidence of the comparability of the web-based and lab-based settings. Regarding linguistic implications, it can neither be confirmed nor ruled out whether syntactic or semantic context or cross-linguistic syntactic L1 interference induced the absence of cognate facilitation (Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Lauro & Schwartz, Reference Lauro and Schwartz2017). In fact, the syntactic environment is rather unlikely to have caused the null findings since no cognate facilitation was found for these words out of context either (see Experiment 1). Further research is needed to better understand the interplay of lexical and syntactic L1 activation and its influence on L2 sentence processing.
With respect to RQ3, the present study identified the impacts of word order and plausibility on L2 English relative clause processing. In general, accuracies for plausibility judgment were high across the board in all conditions for both groups, reflecting participants’ advanced L2 sentence comprehension. Nevertheless, the plausibility judgment accuracies revealed that implausible sentences were processed more accurately than plausible ones, contradicting the assumption of a processing advantage for semantically plausible sentences. The disadvantage of plausible sentences was particularly evident in the processing of plausible ORCs by the online group, with comparatively lower accuracies in this condition (M = 88%). A possible explanation could lie in thematic roles and positing a somewhat enhanced agent-first preference in these learners. Such a preference is characterized by the first-mentioned noun phrase (NP) of a sentence being more likely to be interpreted as the agent (and not patient) of a transitive event (Bever, Reference Bever and Hayes1970; VanPatten, Reference VanPatten, VanPatten and Williams2015). Applying this to plausible ORCs (first NP is patient and not agent), the initial interpretation tends to be implausible. However, with target-like syntactic parsing, the initial implausible interpretation needs to be overcome, forcing learners to reanalyze the sentence to allow successful interpretation. In this case, it seemed more difficult to judge a sentence that had already been assessed implausible as still plausible than vice versa (i.e., judging a sentence that had been assessed plausible as implausible, e.g., when erroneously applying the agent-first strategy to implausible ORCs that start with the patient). Applying such a processing heuristic thus leads to more revision difficulties when the sentence has already been discarded. However, this descriptive disadvantage for plausible ORC accuracies is only present in the online group. This might indicate a general speed–accuracy trade-off in web-based participants’ reading times: The online group may have failed in reanalyzing the initially seemingly implausible sentence as plausible slightly more often than the lab-based group because they were reading descriptively faster, which applies to both overall reading times and to RTs in the critical and post-critical phrase.
With regard to reading times of the critical phrase, analyses revealed main effects of plausibility and sentence type. The present study thus replicated previous in-person research by demonstrating processing advantages for plausible sentences over implausible ones and advantages for SRCs over ORCs in both settings (for similar findings, see Lim & Christianson, Reference Lim and Christianson2013). No significant difference in RTs between settings was found.
With regard to reading times of the post-critical phrase, analyses yielded main effects of plausibility and sentence type as well as an interaction of the two factors. Overall, implausible sentences were processed faster than plausible ones. This processing advantage for implausible sentences contrasts with the pattern observed in the critical phrase, which is most likely due to the nature of the plausibility judgment task itself. As soon as an implausible sentence has been deemed implausible, for which participants already have sufficient information in the critical phrase, there is no reason to pay further attention to subsequent regions. Thus, in this case, readers are more likely to skim-read or even skip the post-critical phrase. In contrast, a plausible sentence may turn into an implausible one at any moment depending on incoming information. This may provide a general advantage for implausible sentences on final sentence segments (for similar task effects, see Williams, Reference Williams2006). Additionally, similarly to the critical phrase, SRCs were processed faster than ORCs. This is driven mostly by the plausible sentences, expressed by the two-way interaction, and thus (again) reflecting plausible ORCs as the most difficult condition. As suggested above, the particular difficulty of plausible ORCs is likely due to these sentences initially seeming implausible when following a heuristic agent-first strategy, and this initial judgment needs to be revised to correctly judge these sentences as plausible. As for the group, mixed effects analyses once more revealed no differences across settings and no interaction with any of the experimental manipulations.
With respect to the reading times of both the critical and post-critical phrases and the mean reading speed across all phrases, the web-based group demonstrated descriptively faster RTs than the lab-based group. Note, however, that this difference in absolute RTs only appeared descriptively, and neither a main effect of setting nor an interaction with it was found in any of the abovementioned analyses. Since significant effects of word order and plausibility were found for all three dependent measures in both settings, it can be concluded that the self-paced reading data collected online is on par with the data collected in the lab.
In summary, the self-paced reading results complement the findings from lexical decision (Experiment 1) and extend previous research demonstrating comparable findings of behavioral data collections conducted via the web and in the lab (Hilbig, Reference Hilbig2016; Kim et al., Reference Kim, Lowder and Choi2023; Patterson & Nicklin, Reference Patterson and Nicklin2023). The results of Experiment 2 revealed that the linguistic effects of sentence plausibility and sentence structure obtained in the lab can be replicated via online data collection. Methodological consequences resulting from the decision to conduct web-based research and important aspects that need to be considered for the preparation and implementation of online testing will be discussed in more detail below.
4. General discussion and directions for future web-based research
The present study assessed possible differences and similarities in second language processing between traditional in-person laboratory testing and the collection of experimental data via the web. For this purpose, we utilized two well-established linguistic paradigms – lexical decision and self-paced reading – to examine L2 word recognition and sentence comprehension and, by these means, aimed to determine whether the testing environment affects (behavioral) measurements, specifically decision accuracies and response latencies. Participants in both groups were recruited from the same population (i.e., students at the same university) and corresponded in background measures, such as age, age of English acquisition, length of immersion in an English study program and their proficiency in German and English. For L2 word recognition, the present study replicated the expected word/nonword effect in both groups. A cognate effect could be demonstrated in participants’ decision accuracies but not in RTs. This pattern was consistent across both settings. Similarly, no cognate effect was found in L2 sentence reading in either group. Regarding the processing of canonical and noncanonical L2 sentence structures, the present study replicated word order and plausibility effects in both settings. Thus, the consistent processing patterns found across groups suggest comparable evidence of web-based and lab-based data collection and support that remote testing is a viable option for behavioral psycholinguistic L2 research despite potentially higher variability in L2 compared to L1 populations.
Notwithstanding the overarching comparability, there is one aspect in which the groups did differ: The online group was characterized by a higher dropout/exclusion rate for participants. This is generally in line with previous research demonstrating increased dropout rates among online participants (Yetano & Royo, Reference Yetano and Royo2017). To prevent higher dropout rates and subsequently incomplete data sets in advance, the duration of online experiments should be kept as short as possible. Recent studies recommend overall study durations of a maximum 45 minutes (Gagné & Franzen, Reference Gagné and Franzen2023) or even less than 30 minutes (Sauter et al., Reference Sauter, Draschkow and Mack2020). Increased duration, in contrast, might lead to a drop in participants’ motivation and concentration, resulting in tasks being skipped or the entire study being terminated prematurely. The threshold to abort the experiment is much lower in online testing compared to lab-based testing as, during the latter, the experimenter is present, and the risk of distraction can be mitigated. Moreover, it should be noted that the likelihood of technical challenges, such as unstable internet connections, to occur is much higher when testing online. In the present study, almost 17% of the web participants needed to be removed from further analyses due to missing data and/or technical problems. Additionally, around 9% had to be excluded as they did not meet the participation requirements (i.e., studying English). Thus, increasing the sample size for online data collection is recommended.
Besides the higher dropout rate in the web-based setting, the present study has demonstrated that online and laboratory testing can be comparable. Particularly since online participation was not limited to a specific operating system and different browser systems were used, this finding is encouraging for future web-based research. It suggests that behavioral online studies can be implemented without imposing a specific operating system and browser, which facilitates implementation and makes participation considerably more accessible. Note, however, that technologies are subject to constant change and, in most cases, improvement. It is thus crucial for future research to keep pace with technical progress and regularly reassess the data quality of web-based behavioral data collection as technical development moves forward.
Overall, there are further aspects that researchers should bear in mind when collecting data online: to attenuate potential confounding factors, participants should be provided with precise guidelines prior to the experimental session, including detailed information on the technical setup (e.g., allowed hardware, i.e., laptops/computer versus tablets) but also the general framework (e.g., participation in a quiet environment). Additionally, even during online data collection, the experimenter should be available at any time during the experimental session in case questions arise. Therefore, it is advisable to schedule fixed testing appointments, ideally preceded by a brief online meeting prior to the actual experiments, to guide participants through the testing procedure and to which they can return in case questions arise during the testing session. Moreover, to probe the risk of increased distraction or a potential lack of focus in web-based experiments, it is advisable to implement attention checks into online experiments to better monitor participants’ concentration (Gagné & Franzen, Reference Gagné and Franzen2023). Furthermore, it is recommended to pilot experiments on different operating systems and various browsers to preempt potential technical issues during data collection. Whereas the present study’s findings from lexical decision and self-paced reading were comparable across both groups, other tasks might be less suitable for online data collection. These include working memory experiments such as Digit Span tasks, which may be more prone to participants using illicit means such as noting down digits for easier later recall. Nevertheless, such issues can at least partially be prevented by including time-outs in tasks. Moreover, tasks eliciting speech production, in turn, imply other challenges (but see He et al., Reference He, Meyer, Creemers and Brehm2021, for recommendations for web-based spoken language production research). With regard to the studied population, web-based data collection comprises two sides of the same coin. On the one hand, online testing is a helpful means to increase access to comparatively understudied populations (Garcia et al., Reference Garcia, Roeser and Kidd2022). On the other hand, certain populations might not have access to the means for online data collection, for example, due to their socioeconomic background. For this study’s population of university students, online data collection was a suitable means as the participants had access to the necessary technical resources. In contrast, other populations might not have such access or are not as technically inclined and may therefore have more difficulty with performing experiments online (see van der Ploeg et al., Reference van der Ploeg, Lowie and Keijzer2023, for limitations of web-based research with older adults).
Notwithstanding these potential problems, online research provides benefits compared to in-lab testing. Online testing enables broader access to participants and may thus lead to larger sample sizes. Relatedly, it also provides a smaller threshold to participate than travelling to a lab, and online participants may experience increased anonymity through remoteness as a perk. Additionally, the use of online testing can free up experimenters’ resources by not having to rely on lab resources, and concomitantly, the online format can save researchers’ time, since participants can be tested simultaneously.
5. Conclusion
In summary, the present study’s findings add to the literature advocating for the comparability of web-based and lab-based behavioral data collections. More specifically, the study provides new insights into the comparability of research across these settings with a population of adult second language learners and expands the current literature by directly comparing the groups on L2 word recognition and sentence comprehension. The present study replicated effects of word order (RC processing) and plausibility for L2 sentence reading and the word/nonword effect for L2 lexical comprehension across both settings. Although cognate effects have been extensively demonstrated in previous lab-based research, the current study was not able to replicate these in reaction times, both for words within and without context. Nevertheless, these results were consistent across groups, suggesting that they were not setting-induced but instead more likely to be attributed to other factors such as learners’ advanced L2 proficiency or the frequency of the target words. Future studies should thus further investigate potential modulating factors in cognate processing. With respect to methodological implications, future research should keep an eye on technical progress and its consequences for web-based data collection. Nonetheless, this study has demonstrated that even today, online data collection can be a viable and reliable means to collect behavioral data remotely, yet it needs to be prepared with great care. It is crucial to try to best anticipate contingently upcoming issues so that they can be prevented beforehand (such as uncertainties regarding the instructions), and it is vital to always make decisions with the research objective in mind. If these aspects are considered, web-based data collection can serve as a suitable option for psycholinguistic research on not just first but also second language processing.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S136672892510028X.
Data availability statement
Materials, data, and code used in this study can be accessed via OSF (https://osf.io/j86m9/). Further information can be obtained by contacting the corresponding author.
Acknowlegements
This work was supported by the German Research Foundation (DFG; grant no. 436221639) and was conducted while Freya Gastmann and Sarah Schimke were at TU Dortmund University. We thank the student assistants at TU Dortmund University for their help with lab-based data collection and all students who participated in this study.
Competing interests
The authors declare none.










 Open access
Open access