Refine search
Actions for selected content:
251 results
Measuring joint attention in co-creation through automatic human activity recognition
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 12 August 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the Role of Artificial Intelligence in Aerospace Engineering: Current State of the Art and Future Trajectories
-
- Journal:
- The Aeronautical Journal , First View
- Published online by Cambridge University Press:
- 11 August 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tree semantic segmentation from aerial image time series
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 29 July 2025, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Deep learning–based automated weed coverage estimation for herbicide efficacy assessment and turfgrass management
-
- Journal:
- Weed Science / Volume 73 / Issue 1 / 2025
- Published online by Cambridge University Press:
- 28 July 2025, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The pipelines of deep learning-based plant image processing
-
- Journal:
- Quantitative Plant Biology / Volume 6 / 2025
- Published online by Cambridge University Press:
- 25 July 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MoTiF: a self-supervised model for multi-source forecasting with application to tropical cyclones
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 23 July 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can artificial intelligence support Bactrian camel conservation? Testing machine learning on aerial imagery in Mongolia’s Gobi Desert
-
- Journal:
- Environmental Conservation , First View
- Published online by Cambridge University Press:
- 18 July 2025, pp. 1-8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Semantic Segmentation of Archaeological Features on Public Lands: Case Study of Historical Cotton Terraces within the Piedmont National Wildlife Refuge, Georgia, USA
-
- Journal:
- Advances in Archaeological Practice , First View
- Published online by Cambridge University Press:
- 08 July 2025, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Efficient Phase Locking in Massive Laser Arrays with Deep Learning from Structured Data
-
- Journal:
- High Power Laser Science and Engineering / Accepted manuscript
- Published online by Cambridge University Press:
- 30 June 2025, pp. 1-12
-
- Article
-
- You have access
- Open access
- Export citation
Classification of carrier-based aircraft pilot mental workloads based on feature-level fusion and decision-level fusion of PPG and EEG signals
-
- Journal:
- The Aeronautical Journal , First View
- Published online by Cambridge University Press:
- 13 June 2025, pp. 1-20
-
- Article
- Export citation
1 - Previous Research on Language Readability
-
- Book:
- Multilingual Environmental Communications
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 1-22
-
- Chapter
- Export citation

The Art of Inpainting
- Mathematical Methods for the Virtual Restoration of Illuminated Manuscripts
-
- Published online:
- 22 May 2025
- Print publication:
- 22 May 2025
4 - Deep Learning Inpainting Methods
-
- Book:
- The Art of Inpainting
- Published online:
- 22 May 2025
- Print publication:
- 22 May 2025, pp 115-161
-
- Chapter
- Export citation
A comprehensive survey on advertising click-through rate prediction algorithm
-
- Journal:
- The Knowledge Engineering Review / Volume 40 / 2025
- Published online by Cambridge University Press:
- 21 May 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
REFNet: reparameterized feature enhancement and fusion network for underwater blur target recognition
-
- Article
- Export citation
-
The underwater target detection is affected by image blurring caused by suspended particles in water bodies and light scattering effects. To tackle this issue, this paper proposes a reparameterized feature enhancement and fusion network for underwater blur object recognition (REFNet). First, this paper proposes the reparameterized feature enhancement and gathering (REG) module, which is designed to enhance the performance of the backbone network. This module integrates the concepts of reparameterization and global response normalization to enhance the network’s feature extraction capabilities, addressing the challenge of feature extraction posed by image blurriness. Next, this paper proposes the cross-channel information fusion (CIF) module to enhance the neck network. This module combines detailed information from shallow features with semantic information from deeper layers, mitigating the loss of image detail caused by blurring. Additionally, this paper replace the CIoU loss function with the Shape-IoU loss function improves target localization accuracy, addressing the difficulty in accurately locating bounding boxes in blurry images. Experimental results indicate that REFNet achieves superior performance compared to state-of-the-art methods, as evidenced by higher mAP scores on the underwater robot professional competitionand detection underwater objects datasets. REFNet surpasses YOLOv8 by approximately 1.5% in
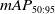 $mAP_{50:95}$ on the URPC dataset and by about 1.3% on the DUO dataset. This enhancement is achieved without significantly increasing the model’s parameters or computational load. This approach enhances the precision of target detection in challenging underwater environments.
$mAP_{50:95}$ on the URPC dataset and by about 1.3% on the DUO dataset. This enhancement is achieved without significantly increasing the model’s parameters or computational load. This approach enhances the precision of target detection in challenging underwater environments.
Deep learning-based collision detection framework for robot tasks in clutter
-
- Article
- Export citation
-
In this work, the problem of reliably checking collisions between robot manipulators and the surrounding environment in short time for tasks, such as replanning and object grasping in clutter, is addressed. Geometric approaches are usually applied in this context; however, they can result not suitable in highly time-constrained applications. The purpose of this paper is to present a learning-based method able to outperform geometric approaches in clutter. The proposed approach uses a neural network (NN) to detect collisions online by performing a classification task on the input represented by the depth image or point cloud containing the robot gripper projected into the application scene. Specifically, several state-of-the-art NN architectures are considered, along with some customization to tackle the problem at hand. These approaches are compared to identify the model that achieves the highest accuracy while containing the computational burden. The analysis shows the feasibility of the robot collision checker based on a deep learning approach. In fact, such approach presents a low collision detection time, of the order of milliseconds on the selected hardware, with acceptable accuracy. Furthermore, the computational burden is compared with state-of-the-art geometric techniques. The entire work is based on an industrial case study involving a KUKA Agilus industrial robot manipulator at the Technology
 $\&$ Innovation Center of KUKA Deutschland GmbH, Germany. Further validation is performed with the Amazon Robotic Manipulation Benchmark (ARMBench) dataset as well, in order to corroborate the reported findings.
$\&$ Innovation Center of KUKA Deutschland GmbH, Germany. Further validation is performed with the Amazon Robotic Manipulation Benchmark (ARMBench) dataset as well, in order to corroborate the reported findings.

Decision support for the identification of testate amoebae in microscopy images to detect peat presence in horticultural substrates
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
FirnLearn: A neural network-based approach to firn density modeling in Antarctica
-
- Journal:
- Journal of Glaciology / Volume 71 / 2025
- Published online by Cambridge University Press:
- 17 April 2025, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Understanding firn densification is essential for interpreting ice core records, predicting ice sheet mass balance, elevation changes and future sea-level rise. Current models of firn densification on the Antarctic ice sheet (AIS), such as the Herron and Langway (1980) model are either simple semi-empirical models that rely on sparse climatic data and surface density observations or complex physics-based models that rely on poorly understood physics. In this work, we introduce a deep learning technique to study firn densification on the AIS. Our model, FirnLearn, evaluated on 225 cores, shows an average root-mean-square error of 31 kg m−3 and explained variance of 91%. We use the model to generate surface density and the depths to the
 $550\,\mathrm{kg\,m}^{-3}$ and
$550\,\mathrm{kg\,m}^{-3}$ and 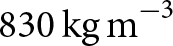 $830\,\mathrm{kg\,m}^{-3}$ density horizons across the AIS to assess spatial variability. Comparisons with the Herron and Langway (1980) model at ten locations with different climate conditions demonstrate that FirnLearn more accurately predicts density profiles in the second stage of densification and complete density profiles without direct surface density observations. This work establishes deep learning as a promising tool for understanding firn processes and advancing towards a universally applicable firn model.
$830\,\mathrm{kg\,m}^{-3}$ density horizons across the AIS to assess spatial variability. Comparisons with the Herron and Langway (1980) model at ten locations with different climate conditions demonstrate that FirnLearn more accurately predicts density profiles in the second stage of densification and complete density profiles without direct surface density observations. This work establishes deep learning as a promising tool for understanding firn processes and advancing towards a universally applicable firn model.

Validity and accuracy of artificial intelligence-based dietary intake assessment methods: a systematic review
-
- Journal:
- British Journal of Nutrition / Volume 133 / Issue 9 / 14 May 2025
- Published online by Cambridge University Press:
- 10 April 2025, pp. 1241-1253
- Print publication:
- 14 May 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Space-scale exploration of the poor reliability of deep learning models: the case of the remote sensing of rooftop photovoltaic systems
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 10 April 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
